-
NI Community
- Welcome & Announcements
-
Discussion Forums
- Most Active Software Boards
- Most Active Hardware Boards
-
Additional NI Product Boards
- Academic Hardware Products (myDAQ, myRIO)
- Automotive and Embedded Networks
- DAQExpress
- DASYLab
- Digital Multimeters (DMMs) and Precision DC Sources
- Driver Development Kit (DDK)
- Dynamic Signal Acquisition
- FOUNDATION Fieldbus
- High-Speed Digitizers
- Industrial Communications
- IF-RIO
- LabVIEW Communications System Design Suite
- LabVIEW Electrical Power Toolkit
- LabVIEW Embedded
- LabVIEW for LEGO MINDSTORMS and LabVIEW for Education
- LabVIEW MathScript RT Module
- LabVIEW Web UI Builder and Data Dashboard
- MATRIXx
- Hobbyist Toolkit
- Measure
- NI Package Manager (NIPM)
- Phase Matrix Products
- RF Measurement Devices
- SignalExpress
- Signal Generators
- Switch Hardware and Software
- USRP Software Radio
- NI ELVIS
- VeriStand
- NI VideoMASTER and NI AudioMASTER
- VirtualBench
- Volume License Manager and Automated Software Installation
- VXI and VME
- Wireless Sensor Networks
- PAtools
- Special Interest Boards
- Community Documents
- Example Programs
-
User Groups
-
Local User Groups (LUGs)
- Aberdeen LabVIEW User Group (Maryland)
- Advanced LabVIEW User Group Denmark
- ANZ (Australia & New Zealand) LabVIEW User Group
- ASEAN LabVIEW User Group
- Automated T&M User Group Denmark
- Bangalore LUG (BlrLUG)
- Barcelona LabVIEW Local User Group (BarVIEWona LUG)
- Bay Area LabVIEW User Group
- Bordeaux Atlantique LabVIEW User Group - BATLUG
- The Boston LabVIEW User Group Community
- British Columbia LabVIEW User Group Community
- Budapest LabVIEW User Group (BudLUG)
- Chennai LUG (CHNLUG)
- Chicago LabVIEW User Group
- Cleveland LabVIEW User Group
- CLUG : Cambridge LabVIEW User Group (UK)
- CSLUG - Central South LabVIEW User Group (UK)
- Dallas Fort Worth (DFW) LabVIEW User Group
- OKC LabVIEW User Group
- Delhi NCR (NCRLUG)
- Denver - ALARM
- DMC LabVIEW User Group
- DutLUG - Dutch LabVIEW Usergroup
- Middle East LabVIEW Local User Group (MELUG)
- Gainesville LabVIEW User Group
- GLA Summit - For all LabVIEW and TestStand Enthusiasts!
- GUNS
- Houston LabVIEW User Group
- High Desert LabVIEW User Group
- Highland Rim LabVIEW User Group
- Huntsville Alabama LabVIEW User Group
- Hyderabad LUG (HydLUG)
- Indian LabVIEW Users Group (IndLUG)
- Ireland LabVIEW User Group Community
- ItalVIEW - Milan, Italy LabVIEW+ Local User Group
- Israel LabVIEW User Group
- LabVIEW-FISICC
- LabVIEW GYM
- LabVIEW LATAM
- LabVIEW User Group Nantes
- LabVIEW Team Indonesia
- LabVIEW - University of Applied Sciences Esslingen
- LabVIEW User Group Berlin
- LabVIEW User Group Central Europe (LUG CE)
- LabVIEW User Group Meeting Austria (LUGMA)
- LabVIEW User Group Euregio
- LabVIEW User Group Munich
- LabVIEW Vietnam
- London LabVIEW User Group
- Long Island NY LabVIEW User Group
- Louisville KY LabView User Group
- LUGG - LabVIEW User Group at Goddard
- LUGE - Rhône-Alpes et plus loin
- LUGNuts: LabVIEW User Group for Connecticut
- LUG of Kolkata & East India (EastLUG)
- LVUG Hamburg
- Madison LabVIEW User Group Community
- Madrid LabVIEW Local User Group (MadLUG)
- Mass Compilers
- Midlands LabVIEW User Group
- Milwaukee LabVIEW Community
- Minneapolis LabVIEW User Group
- Montreal/Quebec LabVIEW User Group Community - QLUG
- NASA LabVIEW User Group Community
- Nebraska LabVIEW User Community
- New Zealand LabVIEW Users Group
- NI UK and Ireland LabVIEW User Group
- NOBLUG - North Of Britain LabVIEW User Group
- NOCLUG
- NORDLUG Nordic LabVIEW User Group
- North Oakland County LabVIEW User Group
- Norwegian LabVIEW User Group
- NWUKLUG
- RT LabVIEW User Group
- Orange County LabVIEW Community
- Orlando LabVIEW User Group
- Ottawa and Montréal LabVIEW User Community
- Pasadena LabVIEW User Group
- Philippines LabVIEW Local User Group (FilLUG)
- Phoenix LabVIEW User Group (PLUG)
- Poland LabVIEW Local User Group
- Politechnika Warszawska
- PolŚl
- Portland Oregon LabVIEW User Group
- Rhein-Main Local User Group (RMLUG)
- Rhein-Ruhr LabVIEW User Group
- Romandie LabVIEW User Group
- Romania LabVIEW Local User Group (RoLUG)
- Rutherford Appleton Laboratory (STFC) - RALLUG
- Serbia LabVIEW User Group
- Sacramento Area LabVIEW User Group
- San Diego LabVIEW Users
- Sheffield LabVIEW User Group
- Silesian LabVIEW User Group (PL)
- South East Michigan LabVIEW User Group
- Southern Ontario LabVIEW User Group Community
- South Sweden LabVIEW User Group
- SoWLUG (UK)
- Space Coast Area LabVIEW User Group
- Stockholm LabVIEW User Group (STHLUG)
- Swiss LabVIEW User Group
- Swiss LabVIEW Embedded User Group
- Sydney User Group
- Taiwan LabVIEW User Group (TWLUG)
- Top of Utah LabVIEW User Group
- TU Delft LabVIEW User Group (TUDLUG)
- Turkiye LabVIEW Local User Group (TurkLUG)
- UKTAG – UK Test Automation Group
- Utahns Using TestStand (UUT)
- UVLabVIEW
- Valencia LabVIEW Local User Group (ValLUG)
- VeriStand: Romania Team
- WaFL - Salt Lake City Utah USA
- Washington Community Group
- Western NY LabVIEW User Group
- Western PA LabVIEW Users
- West Sweden LabVIEW User Group
- WPAFB NI User Group
- WUELUG - Würzburg LabVIEW User Group (DE)
- Yorkshire LabVIEW User Group
- Zero Mile LUG of Nagpur (ZMLUG)
- 日本LabVIEWユーザーグループ
- [IDLE] LabVIEW User Group Stuttgart
- [IDLE] ALVIN
- [IDLE] Barcelona LabVIEW Academic User Group
- [IDLE] Brazil User Group
- [IDLE] Calgary LabVIEW User Group Community
- [IDLE] CLUG - Charlotte LabVIEW User Group
- [IDLE] Central Texas LabVIEW User Community
- [IDLE] Grupo de Usuarios LabVIEW - Chile
- [IDLE] Indianapolis User Group
- [IDLE] LA LabVIEW User Group
- [IDLE] LabVIEW User Group Kaernten
- [IDLE] LabVIEW User Group Steiermark
- [IDLE] தமிழினி
- Academic & University Groups
-
Special Interest Groups
- Actor Framework
- Biomedical User Group
- Certified LabVIEW Architects (CLAs)
- DIY LabVIEW Crew
- LabVIEW APIs
- LabVIEW Champions
- LabVIEW Development Best Practices
- LabVIEW Web Development
- NI Labs
- NI Linux Real-Time
- NI Tools Network Developer Center
- UI Interest Group
- VI Analyzer Enthusiasts
- [Archive] Multisim Custom Simulation Analyses and Instruments
- [Archive] NI Circuit Design Community
- [Archive] NI VeriStand Add-Ons
- [Archive] Reference Design Portal
- [Archive] Volume License Agreement Community
- 3D Vision
- Continuous Integration
- G#
- GDS(Goop Development Suite)
- GPU Computing
- Hardware Developers Community - NI sbRIO & SOM
- JKI State Machine Objects
- LabVIEW Architects Forum
- LabVIEW Channel Wires
- LabVIEW Cloud Toolkits
- Linux Users
- Unit Testing Group
- Distributed Control & Automation Framework (DCAF)
- User Group Resource Center
- User Group Advisory Council
- LabVIEW FPGA Developer Center
- AR Drone Toolkit for LabVIEW - LVH
- Driver Development Kit (DDK) Programmers
- Hidden Gems in vi.lib
- myRIO Balancing Robot
- ROS for LabVIEW(TM) Software
- LabVIEW Project Providers
- Power Electronics Development Center
- LabVIEW Digest Programming Challenges
- Python and NI
- LabVIEW Automotive Ethernet
- NI Web Technology Lead User Group
- QControl Enthusiasts
- Lab Software
- User Group Leaders Network
- CMC Driver Framework
- JDP Science Tools
- LabVIEW in Finance
- Nonlinear Fitting
- Git User Group
- Test System Security
- Developers Using TestStand
- Online LabVIEW Evaluation 'Office Hours'
- Product Groups
-
Partner Groups
- DQMH Consortium Toolkits
- DATA AHEAD toolkit support
- GCentral
- SAPHIR - Toolkits
- Advanced Plotting Toolkit
- Sound and Vibration
- Next Steps - LabVIEW RIO Evaluation Kit
- Neosoft Technologies
- Coherent Solutions Optical Modules
- BLT for LabVIEW (Build, License, Track)
- Test Systems Strategies Inc (TSSI)
- NSWC Crane LabVIEW User Group
- NAVSEA Test & Measurement User Group
-
Local User Groups (LUGs)
-
Idea Exchange
- Data Acquisition Idea Exchange
- DIAdem Idea Exchange
- LabVIEW Idea Exchange
- LabVIEW FPGA Idea Exchange
- LabVIEW Real-Time Idea Exchange
- LabWindows/CVI Idea Exchange
- Multisim and Ultiboard Idea Exchange
- NI Measurement Studio Idea Exchange
- NI Package Management Idea Exchange
- NI TestStand Idea Exchange
- PXI and Instrumentation Idea Exchange
- Vision Idea Exchange
- Additional NI Software Idea Exchange
- Blogs
- Events & Competitions
- Optimal+
- Regional Communities
- NI Partner Hub
-
 swatts
swatts
 on:
Thinking As a Service (TaaS) is not a good model!
on:
Thinking As a Service (TaaS) is not a good model!
-
DavidJCrawford
on:
The Case for an NI Linux Distribution
-
 Dhakkan
on:
Tech Growth is Done! (Click-bait alert)
Dhakkan
on:
Tech Growth is Done! (Click-bait alert)
-
swatts
on:
LabVIEW in a Box! 2 - I made a PCB
-
swatts
on:
A Lil bit of History ..
-
 Petru_Tarabuta
on:
Some Boring Statements
Petru_Tarabuta
on:
Some Boring Statements
-
 softball
on:
LabVIEW and Linux Review
softball
on:
LabVIEW and Linux Review
-
swatts
on:
LabVIEW in a Box!
-
 Taggart
on:
Influence
Taggart
on:
Influence
-
swatts
on:
TMiLV (This Month in LabVIEW) - Definitely NOT another podcast!
OpenDocument Format
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Hello my lovelies.
Update: Check out this tool
This article is a little bit different in that it's the beginning of a project I'm been thinking about for a little while. At the very least if I take it no further my scribblings may save someone some time.
First the why
The beauty of having open documents is that as a software developer I can make a package for disribution to my customer without worrying about licenses. This just feel much more wholesome to me. So I've looked at various options (ActiveX OpenOffice, dlls etc), but they all involve driving someone elses code. One of the reference books available is called OASIS OpenDocument Essentials and in it is this little snippet that sums up my general feeling.
When talking about storing in a propriety format rather than an open format.
Note also that your data can become inaccessible when the software vendor moves to a new internal format and stops supporting your current version. (Some people actually suggest that this is not cause for complaint since, by putting your data into the vendor’s proprietary format, the vendor has now become a co-owner of your data. This is, and I mean this in the nicest possible way, a dangerously idiotic idea.)
J. David Eisenberg
What I actually need is a way to generate a spreadsheet checklist for all the VIs in a project.
So what is the OpenDocument format.
Wikipedia sums it up thus.
The Open Document Format for Office Applications (ODF), also known as OpenDocument, is an XML-based file format for spreadsheets, charts, presentations and word processing documents. It was developed with the aim of providing an open, XML-based file format specification for office applications
Stuff I've learnt....
OD File Structure
If you save an OpenOffice or LibreOffice file it will save as an ODS (for a spreadsheet), ODT (for a word processing document) or ODP (for a presentation). These are a JAR format file, this being Java Archive or simply put a ZIPped package where some of the contents are NOT compressed. Here's one unzipped.
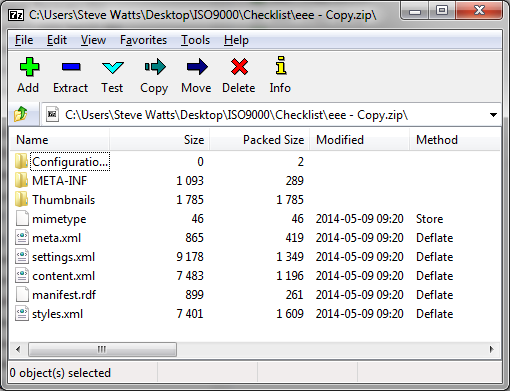
My first hurdle was not compressing mimetype.
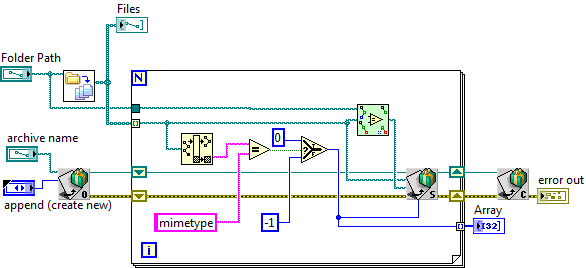
Here's how I did it (using the Open G Advanced Compression VIs, doctored so that I can set the compression type)
The file that does all the work is content.xml and here's what I've learnt about this bad boy. The best way to describe it is to show a spreadsheet with some data and display the xml and then describe how they get there.
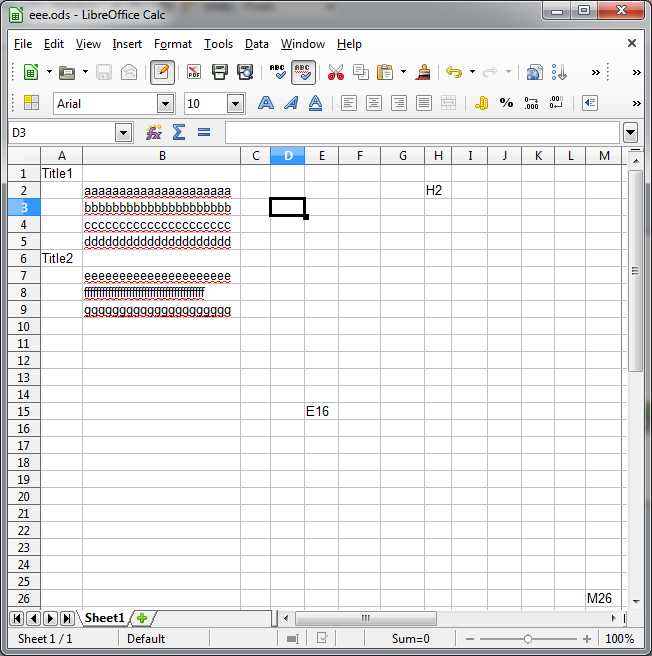 |  |
NOTE: the XML is from a spreadsheet where the columns haven't been squashed for artistic license, the xml for the one shown may therefore have more column info to describe the cell size.
After some headscratching and surprisingly little help from the internet I fathomed that it works like this....
The 3 table:table-column nodes describe the 1st column, the 2nd column with added width and then the remaining columns
We then have 13 table:table-row nodes that contain the cell information.
Of course this all looks lovely and ordered but the file really looks something like this.
<table:table table:name="Sheet1" table:style-name="ta1"><table:table-column table:style-name="co1" table:default-cell-style-name="Default"/><table:table-column table:style-name="co2" table:default-cell-style-name="Default"/><table:table-column table:style-name="co1" table:number-columns-repeated="11" table:default-cell-style-name="Default"/><table:table-row table:style-name="ro1"><table:table-cell office:value-type="string" calcext:value-type="string"><text:p>Title1</text:p></table:table-cell><table:table-cell table:number-columns-repeated="12"/></table:table-row><table:table-row table:style-name="ro2"><table:table-cell/><table:table-cell office:value-type="string" calcext:value-type="string"><text:p>aaaaaaaaaaaaaaaaaaaaa</text:p></table:table-cell><table:table-cell table:number-columns-repeated="5"/>
So I'll be using the DOM xml parser VIs and some XPath for searching out the nodes.
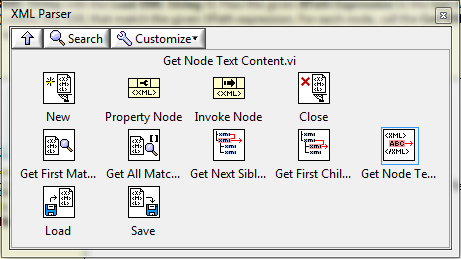
My plan is to make a polymorphic container type component where the polymorphic selector is the command. This will wrap the LVOOP document classes. With methods to Load, Save, Save As, Add Cell to Table, Add Array to Table, Get Cell Data, Get Cell Data Type.
If anyone is interested I'll post the code (it may be useful to use github to allow methods to be added)
Next step is to do some UML diagrams of the class structure. But that's for another day.
Lots of Love
Steve
Steve
Opportunity to learn from experienced developers / entrepeneurs (Fab,Joerg and Brian amongst them):
DSH Pragmatic Software Development Workshop
- Tags:
- opendocument
- xml
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
