Home
Community
User Groups
Special Interest Groups
LabVIEW Development Best Practices
LabVIEW Development Best Practices Blog
Community Browser
-
NI Community
- Welcome & Announcements
-
Discussion Forums
- Most Active Software Boards
- Most Active Hardware Boards
-
Additional NI Product Boards
- Academic Hardware Products (myDAQ, myRIO)
- Automotive and Embedded Networks
- DAQExpress
- DASYLab
- Digital Multimeters (DMMs) and Precision DC Sources
- Driver Development Kit (DDK)
- Dynamic Signal Acquisition
- FOUNDATION Fieldbus
- High-Speed Digitizers
- Industrial Communications
- IF-RIO
- LabVIEW Communications System Design Suite
- LabVIEW Electrical Power Toolkit
- LabVIEW Embedded
- LabVIEW for LEGO MINDSTORMS and LabVIEW for Education
- LabVIEW MathScript RT Module
- LabVIEW Web UI Builder and Data Dashboard
- MATRIXx
- Hobbyist Toolkit
- Measure
- NI Package Manager (NIPM)
- Phase Matrix Products
- RF Measurement Devices
- SignalExpress
- Signal Generators
- Switch Hardware and Software
- USRP Software Radio
- NI ELVIS
- VeriStand
- NI VideoMASTER and NI AudioMASTER
- VirtualBench
- Volume License Manager and Automated Software Installation
- VXI and VME
- Wireless Sensor Networks
- PAtools
- Special Interest Boards
- Community Documents
- Example Programs
-
User Groups
-
Local User Groups (LUGs)
- Aberdeen LabVIEW User Group (Maryland)
- Advanced LabVIEW User Group Denmark
- ANZ (Australia & New Zealand) LabVIEW User Group
- ASEAN LabVIEW User Group
- Automated T&M User Group Denmark
- Bangalore LUG (BlrLUG)
- Barcelona LabVIEW Local User Group (BarVIEWona LUG)
- Bay Area LabVIEW User Group
- Bordeaux Atlantique LabVIEW User Group - BATLUG
- The Boston LabVIEW User Group Community
- British Columbia LabVIEW User Group Community
- Budapest LabVIEW User Group (BudLUG)
- Chennai LUG (CHNLUG)
- Chicago LabVIEW User Group
- Cleveland LabVIEW User Group
- CLUG : Cambridge LabVIEW User Group (UK)
- CSLUG - Central South LabVIEW User Group (UK)
- Dallas Fort Worth (DFW) LabVIEW User Group
- OKC LabVIEW User Group
- Delhi NCR (NCRLUG)
- Denver - ALARM
- DMC LabVIEW User Group
- DutLUG - Dutch LabVIEW Usergroup
- Middle East LabVIEW Local User Group (MELUG)
- Gainesville LabVIEW User Group
- GLA Summit - For all LabVIEW and TestStand Enthusiasts!
- GUNS
- Houston LabVIEW User Group
- High Desert LabVIEW User Group
- Highland Rim LabVIEW User Group
- Huntsville Alabama LabVIEW User Group
- Hyderabad LUG (HydLUG)
- Indian LabVIEW Users Group (IndLUG)
- Ireland LabVIEW User Group Community
- ItalVIEW - Milan, Italy LabVIEW+ Local User Group
- Israel LabVIEW User Group
- LabVIEW-FISICC
- LabVIEW GYM
- LabVIEW LATAM
- LabVIEW User Group Nantes
- LabVIEW Team Indonesia
- LabVIEW - University of Applied Sciences Esslingen
- LabVIEW User Group Berlin
- LabVIEW User Group Central Europe (LUG CE)
- LabVIEW User Group Meeting Austria (LUGMA)
- LabVIEW User Group Euregio
- LabVIEW User Group Munich
- LabVIEW Vietnam
- London LabVIEW User Group
- Long Island NY LabVIEW User Group
- Louisville KY LabView User Group
- LUGG - LabVIEW User Group at Goddard
- LUGE - Rhône-Alpes et plus loin
- LUGNuts: LabVIEW User Group for Connecticut
- LUG of Kolkata & East India (EastLUG)
- LVUG Hamburg
- Madison LabVIEW User Group Community
- Madrid LabVIEW Local User Group (MadLUG)
- Mass Compilers
- Midlands LabVIEW User Group
- Milwaukee LabVIEW Community
- Minneapolis LabVIEW User Group
- Montreal/Quebec LabVIEW User Group Community - QLUG
- NASA LabVIEW User Group Community
- Nebraska LabVIEW User Community
- New Zealand LabVIEW Users Group
- NI UK and Ireland LabVIEW User Group
- NOBLUG - North Of Britain LabVIEW User Group
- NOCLUG
- NORDLUG Nordic LabVIEW User Group
- North Oakland County LabVIEW User Group
- Norwegian LabVIEW User Group
- NWUKLUG
- RT LabVIEW User Group
- Orange County LabVIEW Community
- Orlando LabVIEW User Group
- Ottawa and Montréal LabVIEW User Community
- Pasadena LabVIEW User Group
- Philippines LabVIEW Local User Group (FilLUG)
- Phoenix LabVIEW User Group (PLUG)
- Poland LabVIEW Local User Group
- Politechnika Warszawska
- PolŚl
- Portland Oregon LabVIEW User Group
- Rhein-Main Local User Group (RMLUG)
- Rhein-Ruhr LabVIEW User Group
- Romandie LabVIEW User Group
- Romania LabVIEW Local User Group (RouLUG)
- Rutherford Appleton Laboratory (STFC) - RALLUG
- Serbia LabVIEW User Group
- Sacramento Area LabVIEW User Group
- San Diego LabVIEW Users
- Saxony LabVIEW User Group (SAXLUG)
- Sheffield LabVIEW User Group
- Silesian LabVIEW User Group (PL)
- Michigan LabVIEW User Group
- Southern Ontario LabVIEW User Group Community
- South Sweden LabVIEW User Group
- SoWLUG (UK)
- Space Coast Area LabVIEW User Group
- Stockholm LabVIEW User Group (STHLUG)
- Swiss LabVIEW User Group
- Swiss LabVIEW Embedded User Group
- Sydney User Group
- Taiwan LabVIEW User Group (TWLUG)
- Top of Utah LabVIEW User Group
- TU Delft LabVIEW User Group (TUDLUG)
- Turkiye LabVIEW Local User Group (TurkLUG)
- UKTAG – UK Test Automation Group
- Utahns Using TestStand (UUT)
- UVLabVIEW
- Valencia LabVIEW Local User Group (ValLUG)
- VeriStand: Romania Team
- WaFL - Salt Lake City Utah USA
- Washington Community Group
- Western NY LabVIEW User Group
- Western PA LabVIEW Users
- West Sweden LabVIEW User Group
- WPAFB NI User Group
- WUELUG - Würzburg LabVIEW User Group (DE)
- Yorkshire LabVIEW User Group
- Zero Mile LUG of Nagpur (ZMLUG)
- 日本LabVIEWユーザーグループ
- [IDLE] LabVIEW User Group Stuttgart
- [IDLE] ALVIN
- [IDLE] Barcelona LabVIEW Academic User Group
- [IDLE] Brazil User Group
- [IDLE] Calgary LabVIEW User Group Community
- [IDLE] CLUG - Charlotte LabVIEW User Group
- [IDLE] Central Texas LabVIEW User Community
- [IDLE] Grupo de Usuarios LabVIEW - Chile
- [IDLE] Indianapolis User Group
- [IDLE] LA LabVIEW User Group
- [IDLE] LabVIEW User Group Kaernten
- [IDLE] LabVIEW User Group Steiermark
- [IDLE] தமிழினி
- Columbus OH LabVIEW User Group
- Grand Est LabVIEW User Group (LUGE GE)
- Academic & University Groups
-
Special Interest Groups
- Actor Framework
- Biomedical User Group
- Certified LabVIEW Architects (CLAs)
- DIY LabVIEW Crew
- LabVIEW APIs
- LabVIEW Champions
- LabVIEW Development Best Practices
- LabVIEW Web Development
- NI Labs
- NI Linux Real-Time
- NI Tools Network Developer Center
- UI Interest Group
- VI Analyzer Enthusiasts
- [Archive] Multisim Custom Simulation Analyses and Instruments
- [Archive] NI Circuit Design Community
- [Archive] NI VeriStand Add-Ons
- [Archive] Reference Design Portal
- [Archive] Volume License Agreement Community
- 3D Vision
- Continuous Integration
- G#
- GDS(Goop Development Suite)
- GPU Computing
- Hardware Developers Community - NI sbRIO & SOM
- JKI State Machine Objects
- LabVIEW Architects Forum
- LabVIEW Channel Wires
- LabVIEW Cloud Toolkits
- Linux Users
- Unit Testing Group
- Distributed Control & Automation Framework (DCAF)
- User Group Resource Center
- User Group Advisory Council
- LabVIEW FPGA Developer Center
- AR Drone Toolkit for LabVIEW - LVH
- Driver Development Kit (DDK) Programmers
- Hidden Gems in vi.lib
- myRIO Balancing Robot
- ROS for LabVIEW(TM) Software
- LabVIEW Project Providers
- Power Electronics Development Center
- LabVIEW Digest Programming Challenges
- Python and NI
- LabVIEW Automotive Ethernet
- NI Web Technology Lead User Group
- QControl Enthusiasts
- Lab Software
- User Group Leaders Network
- CMC Driver Framework
- JDP Science Tools
- LabVIEW in Finance
- Nonlinear Fitting
- Git User Group
- Test System Security
- Developers Using TestStand
- Online LabVIEW Evaluation 'Office Hours'
- LabVIEW Beginner Office Hours
- Product Groups
- Partner Groups
-
Local User Groups (LUGs)
-
Idea Exchange
- Data Acquisition Idea Exchange
- DIAdem Idea Exchange
- LabVIEW Idea Exchange
- LabVIEW FPGA Idea Exchange
- LabVIEW Real-Time Idea Exchange
- LabWindows/CVI Idea Exchange
- Multisim and Ultiboard Idea Exchange
- NI Measurement Studio Idea Exchange
- NI Package Management Idea Exchange
- NI TestStand Idea Exchange
- PXI and Instrumentation Idea Exchange
- Vision Idea Exchange
- Additional NI Software Idea Exchange
- Blogs
- Events & Competitions
- Optimal+
- Regional Communities
- NI Partner Hub
Latest Comments
- AristosQueue (NI) on: This Blog Has Moved...
- AristosQueue (NI) on: Using Variant Attributes for High-Performance Lookup Tables in LabVIEW
-
 AELmx
on:
See you at NIWeek!
AELmx
on:
See you at NIWeek!
-
 ramktamu
ramktamu
 on:
Video on Measurement Abstraction Layers, MVC and the Actor Framework
on:
Video on Measurement Abstraction Layers, MVC and the Actor Framework
-
 TroyK
on:
data export to a single excell sheet
TroyK
on:
data export to a single excell sheet
-
 amandion
on:
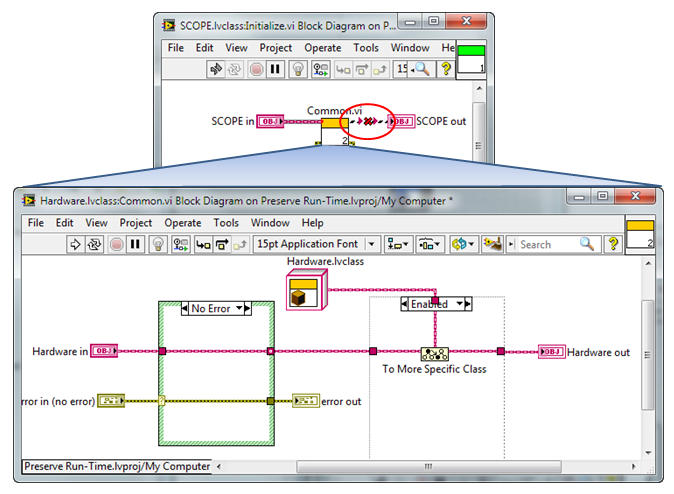
When Should the 'To More Specific' or 'Preserve Tun-Time Class' Primitives be Used with OOP in LabVIEW?
amandion
on:
When Should the 'To More Specific' or 'Preserve Tun-Time Class' Primitives be Used with OOP in LabVIEW?
-
 vishots.com
on:
Best Practices for Dynamic VI Loading (VI Lifetime Management Video)
vishots.com
on:
Best Practices for Dynamic VI Loading (VI Lifetime Management Video)
-
 sth
on:
Recorded Virtual User Group on Team-Based Development and Source Code Control
sth
on:
Recorded Virtual User Group on Team-Based Development and Source Code Control
-
 PaulLotz
on:
Using Events for Communication Between Asynchronous LabVIEW Loops
PaulLotz
on:
Using Events for Communication Between Asynchronous LabVIEW Loops
- AristosQueue (NI) on: Error Cluster Constant for LabVIEW 2011
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Blog Options
- Mark all as New
- Mark all as Read
- Float this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed
15043
Views
0
Comments
74205
Views
32
Comments

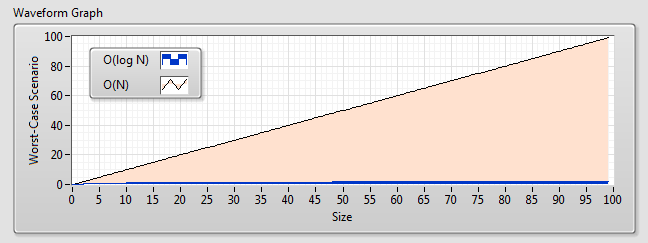

21778
Views
9
Comments
14678
Views
0
Comments
28414
Views
12
Comments
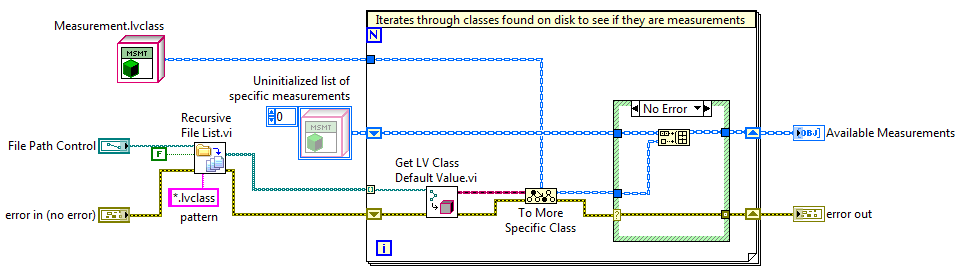
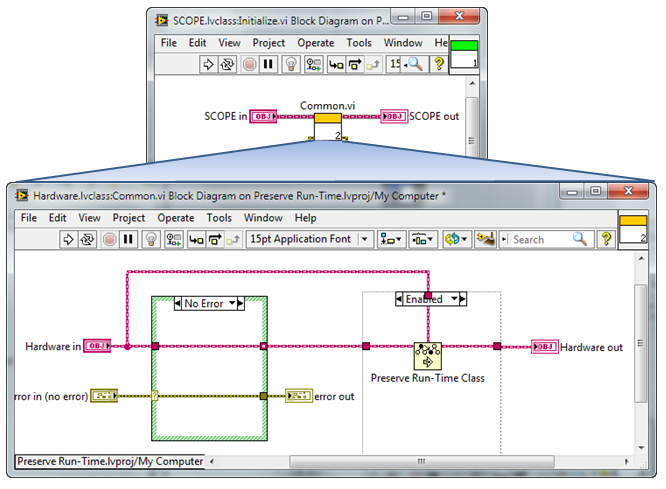
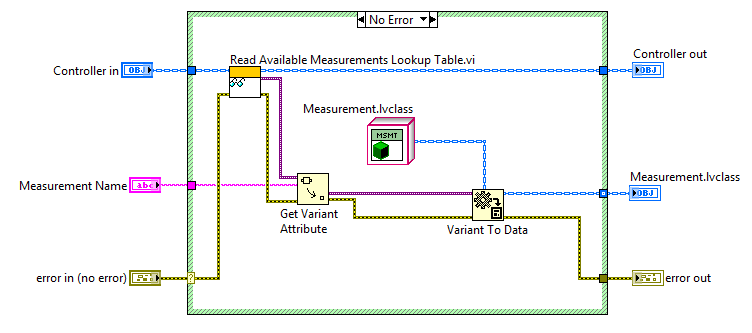
15640
Views
0
Comments
 The CLA Summit is a unique opportunity for me, as I get to participate as both a user and as a product manager. It’s great to be able to talk to so many other passionate and knowledgeable LabVIEW users, and as always, to hear your feedback and opinions regarding LabVIEW and the latest advanced concepts.
The CLA Summit is a unique opportunity for me, as I get to participate as both a user and as a product manager. It’s great to be able to talk to so many other passionate and knowledgeable LabVIEW users, and as always, to hear your feedback and opinions regarding LabVIEW and the latest advanced concepts. For those of you who weren’t able to attend, the topic this year was ‘separating user interfaces from application logic,’ which prompted a lot of passionate discussion (and healthy debate) regarding various approaches, such as model-view-controller and various frameworks for implementation. Presentations and demos from the summit are going to be posted to the community group, here:
For those of you who weren’t able to attend, the topic this year was ‘separating user interfaces from application logic,’ which prompted a lot of passionate discussion (and healthy debate) regarding various approaches, such as model-view-controller and various frameworks for implementation. Presentations and demos from the summit are going to be posted to the community group, here:
14197
Views
0
Comments

24796
Views
0
Comments
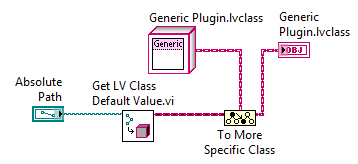
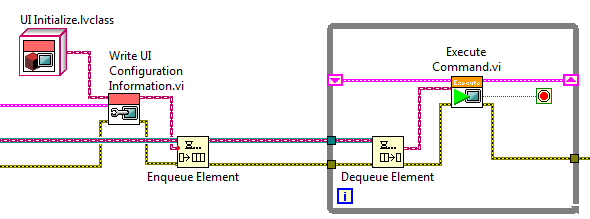
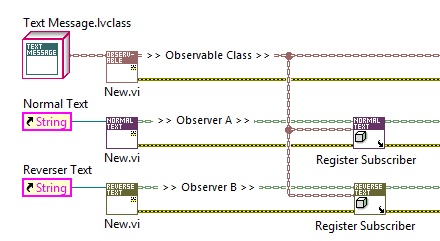
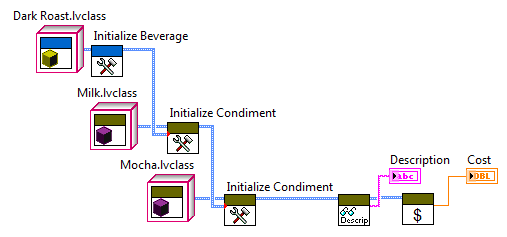
25626
Views
3
Comments
16022
Views
3
Comments
27636
Views
8
Comments

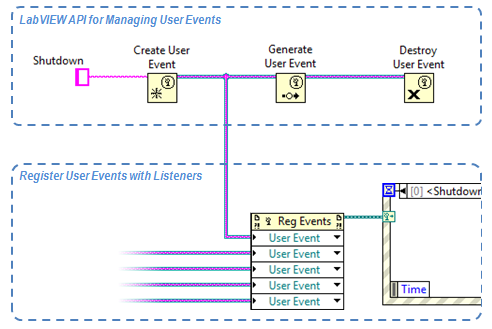
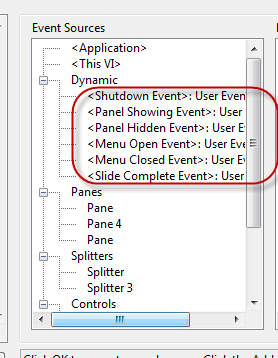
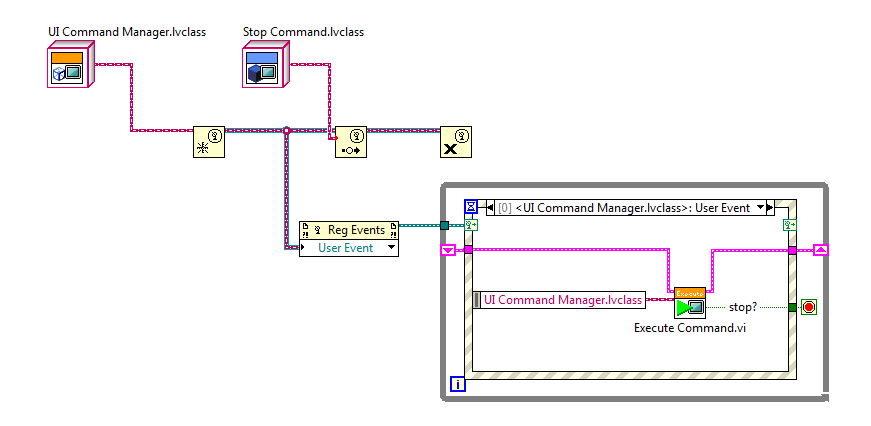
19638
Views
7
Comments

16918
Views
4
Comments
15981
Views
3
Comments
16936
Views
2
Comments
25595
Views
22
Comments
14031
Views
0
Comments
13083
Views
0
Comments
14119
Views
0
Comments
17911
Views
0
Comments
15879
Views
3
Comments
13689
Views
0
Comments
21959
Views
24
Comments
13224
Views
0
Comments
