-
NI Community
- Welcome & Announcements
-
Discussion Forums
- Most Active Software Boards
- Most Active Hardware Boards
-
Additional NI Product Boards
- Academic Hardware Products (myDAQ, myRIO)
- Automotive and Embedded Networks
- DAQExpress
- DASYLab
- Digital Multimeters (DMMs) and Precision DC Sources
- Driver Development Kit (DDK)
- Dynamic Signal Acquisition
- FOUNDATION Fieldbus
- High-Speed Digitizers
- Industrial Communications
- IF-RIO
- LabVIEW Communications System Design Suite
- LabVIEW Electrical Power Toolkit
- LabVIEW Embedded
- LabVIEW for LEGO MINDSTORMS and LabVIEW for Education
- LabVIEW MathScript RT Module
- LabVIEW Web UI Builder and Data Dashboard
- MATRIXx
- Hobbyist Toolkit
- Measure
- NI Package Manager (NIPM)
- Phase Matrix Products
- RF Measurement Devices
- SignalExpress
- Signal Generators
- Switch Hardware and Software
- USRP Software Radio
- NI ELVIS
- VeriStand
- NI VideoMASTER and NI AudioMASTER
- VirtualBench
- Volume License Manager and Automated Software Installation
- VXI and VME
- Wireless Sensor Networks
- PAtools
- Special Interest Boards
- Community Documents
- Example Programs
-
User Groups
-
Local User Groups (LUGs)
- Aberdeen LabVIEW User Group (Maryland)
- Advanced LabVIEW User Group Denmark
- ANZ (Australia & New Zealand) LabVIEW User Group
- ASEAN LabVIEW User Group
- Automated T&M User Group Denmark
- Bangalore LUG (BlrLUG)
- Bay Area LabVIEW User Group
- Bordeaux Atlantique LabVIEW User Group - BATLUG
- British Columbia LabVIEW User Group Community
- Budapest LabVIEW User Group (BudLUG)
- Chennai LUG (CHNLUG)
- Chicago LabVIEW User Group
- Cleveland LabVIEW User Group
- CLUG : Cambridge LabVIEW User Group (UK)
- CSLUG - Central South LabVIEW User Group (UK)
- Dallas Fort Worth (DFW) LabVIEW User Group
- North Dallas User Group Community
- Delhi NCR (NCRLUG)
- Denver - ALARM
- DMC LabVIEW User Group
- DutLUG - Dutch LabVIEW Usergroup
- Egypt NI Chapter
- Gainesville LabVIEW User Group
- GLA Summit - For all LabVIEW and TestStand Enthusiasts!
- GUNS
- Houston LabVIEW User Group
- High Desert LabVIEW User Group
- Highland Rim LabVIEW User Group
- Huntsville Alabama LabVIEW User Group
- Hyderabad LUG (HydLUG)
- Indian LabVIEW Users Group (IndLUG)
- Ireland LabVIEW User Group Community
- ItalVIEW - Milan, Italy LabVIEW+ Local User Group
- Israel LabVIEW User Group
- LabVIEW-FISICC
- LabVIEW GYM
- LabVIEW LATAM
- LabVIEW User Group Nantes
- LabVIEW Team Indonesia
- LabVIEW - University of Applied Sciences Esslingen
- LabVIEW User Group Berlin
- LabVIEW User Group Euregio
- LabVIEW User Group Munich
- LabVIEW Vietnam
- London LabVIEW User Group
- Long Island NY LabVIEW User Group
- Louisville KY LabView User Group
- LUGG - LabVIEW User Group at Goddard
- LUGE - Rhône-Alpes et plus loin
- LUGNuts: LabVIEW User Group for Connecticut
- LUG of Kolkata & East India (EastLUG)
- LVUG Hamburg
- Madison LabVIEW User Group Community
- Madrid LabVIEW Local User Group (MadLUG)
- Mass Compilers
- Midlands LabVIEW User Group
- Milwaukee LabVIEW Community
- Minneapolis LabVIEW User Group
- Montreal/Quebec LabVIEW User Group Community - QLUG
- NASA LabVIEW User Group Community
- Nebraska LabVIEW User Community
- New Zealand LabVIEW Users Group
- NI UK and Ireland LabVIEW User Group
- NOBLUG - North Of Britain LabVIEW User Group
- NOCLUG
- NORDLUG Nordic LabVIEW User Group
- North Oakland County LabVIEW User Group
- Norwegian LabVIEW User Group
- NWUKLUG
- RT LabVIEW User Group
- Orange County LabVIEW Community
- Orlando LabVIEW User Group
- Ottawa and Montréal LabVIEW User Community
- Pasadena LabVIEW User Group
- Philippines LabVIEW Local User Group (FilLUG)
- Phoenix LabVIEW User Group (PLUG)
- Politechnika Warszawska
- PolŚl
- Portland Oregon LabVIEW User Group
- Rhein-Main Local User Group (RMLUG)
- Rhein-Ruhr LabVIEW User Group
- Romandie LabVIEW User Group
- Romania LabVIEW Local User Group (RoLUG)
- Rutherford Appleton Laboratory (STFC) - RALLUG
- Serbia LabVIEW User Group
- Sacramento Area LabVIEW User Group
- San Diego LabVIEW Users
- Sheffield LabVIEW User Group
- Silesian LabVIEW User Group (PL)
- South East Michigan LabVIEW User Group
- Southern Ontario LabVIEW User Group Community
- South Sweden LabVIEW User Group
- SoWLUG (UK)
- Space Coast Area LabVIEW User Group
- Stockholm LabVIEW User Group (STHLUG)
- Swiss LabVIEW User Group
- Swiss LabVIEW Embedded User Group
- Sydney User Group
- Taiwan LabVIEW User Group (TWLUG)
- Top of Utah LabVIEW User Group
- TU Delft LabVIEW User Group (TUDLUG)
- UKTAG – UK Test Automation Group
- Utahns Using TestStand (UUT)
- UVLabVIEW
- VeriStand: Romania Team
- WaFL - Salt Lake City Utah USA
- Washington Community Group
- Western NY LabVIEW User Group
- Western PA LabVIEW Users
- West Sweden LabVIEW User Group
- WPAFB NI User Group
- WUELUG - Würzburg LabVIEW User Group (DE)
- Yorkshire LabVIEW User Group
- Zero Mile LUG of Nagpur (ZMLUG)
- 日本LabVIEWユーザーグループ
- [IDLE] LabVIEW User Group Stuttgart
- [IDLE] ALVIN
- [IDLE] Barcelona LabVIEW Academic User Group
- [IDLE] The Boston LabVIEW User Group Community
- [IDLE] Brazil User Group
- [IDLE] Calgary LabVIEW User Group Community
- [IDLE] CLUG - Charlotte LabVIEW User Group
- [IDLE] Central Texas LabVIEW User Community
- [IDLE] Grupo de Usuarios LabVIEW - Chile
- [IDLE] Indianapolis User Group
- [IDLE] LA LabVIEW User Group
- [IDLE] LabVIEW User Group Kaernten
- [IDLE] LabVIEW User Group Steiermark
- [IDLE] தமிழினி
- Academic & University Groups
-
Special Interest Groups
- Actor Framework
- Biomedical User Group
- Certified LabVIEW Architects (CLAs)
- DIY LabVIEW Crew
- LabVIEW APIs
- LabVIEW Champions
- LabVIEW Development Best Practices
- LabVIEW Web Development
- NI Labs
- NI Linux Real-Time
- NI Tools Network Developer Center
- UI Interest Group
- VI Analyzer Enthusiasts
- [Archive] Multisim Custom Simulation Analyses and Instruments
- [Archive] NI Circuit Design Community
- [Archive] NI VeriStand Add-Ons
- [Archive] Reference Design Portal
- [Archive] Volume License Agreement Community
- 3D Vision
- Continuous Integration
- G#
- GDS(Goop Development Suite)
- GPU Computing
- Hardware Developers Community - NI sbRIO & SOM
- JKI State Machine Objects
- LabVIEW Architects Forum
- LabVIEW Channel Wires
- LabVIEW Cloud Toolkits
- Linux Users
- Unit Testing Group
- Distributed Control & Automation Framework (DCAF)
- User Group Resource Center
- User Group Advisory Council
- LabVIEW FPGA Developer Center
- AR Drone Toolkit for LabVIEW - LVH
- Driver Development Kit (DDK) Programmers
- Hidden Gems in vi.lib
- myRIO Balancing Robot
- ROS for LabVIEW(TM) Software
- LabVIEW Project Providers
- Power Electronics Development Center
- LabVIEW Digest Programming Challenges
- Python and NI
- LabVIEW Automotive Ethernet
- NI Web Technology Lead User Group
- QControl Enthusiasts
- Lab Software
- User Group Leaders Network
- CMC Driver Framework
- JDP Science Tools
- LabVIEW in Finance
- Nonlinear Fitting
- Git User Group
- Test System Security
- Developers Using TestStand
- Online LabVIEW Evaluation 'Office Hours'
- Product Groups
- Partner Groups
-
Local User Groups (LUGs)
-
Idea Exchange
- Data Acquisition Idea Exchange
- DIAdem Idea Exchange
- LabVIEW Idea Exchange
- LabVIEW FPGA Idea Exchange
- LabVIEW Real-Time Idea Exchange
- LabWindows/CVI Idea Exchange
- Multisim and Ultiboard Idea Exchange
- NI Measurement Studio Idea Exchange
- NI Package Management Idea Exchange
- NI TestStand Idea Exchange
- PXI and Instrumentation Idea Exchange
- Vision Idea Exchange
- Additional NI Software Idea Exchange
- Blogs
- Events & Competitions
- Optimal+
- Regional Communities
- NI Partner Hub
- AristosQueue (NI) on: This Blog Has Moved...
- AristosQueue (NI) on: Using Variant Attributes for High-Performance Lookup Tables in LabVIEW
-
 AELmx
on:
See you at NIWeek!
AELmx
on:
See you at NIWeek!
-
 ramktamu
ramktamu
 on:
Video on Measurement Abstraction Layers, MVC and the Actor Framework
on:
Video on Measurement Abstraction Layers, MVC and the Actor Framework
-
 TroyK
on:
data export to a single excell sheet
TroyK
on:
data export to a single excell sheet
-
 amandion
on:
When Should the 'To More Specific' or 'Preserve Tun-Time Class' Primitives be Used with OOP in LabVIEW?
amandion
on:
When Should the 'To More Specific' or 'Preserve Tun-Time Class' Primitives be Used with OOP in LabVIEW?
-
 vishots.com
on:
Best Practices for Dynamic VI Loading (VI Lifetime Management Video)
vishots.com
on:
Best Practices for Dynamic VI Loading (VI Lifetime Management Video)
-
 sth
on:
Recorded Virtual User Group on Team-Based Development and Source Code Control
sth
on:
Recorded Virtual User Group on Team-Based Development and Source Code Control
-
 PaulLotz
on:
Using Events for Communication Between Asynchronous LabVIEW Loops
PaulLotz
on:
Using Events for Communication Between Asynchronous LabVIEW Loops
- AristosQueue (NI) on: Error Cluster Constant for LabVIEW 2011
Using Variant Attributes for High-Performance Lookup Tables in LabVIEW
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
If your instinct is to use an array to manage a lookup table, keep reading - there's a far better way. In case you're not familiar with the term, a 'lookup table' refers to a large table of values that need to be randomly and arbitrarily retrieved programmatically - you may also see these referred to as a 'dictionary' or 'map.' As the name implies, these are typically used in software when you want to retrieve a very specific element or value from a large dataset based on some unique identifier or key. If the data you need to retrieve is stored in a large, unsorted array, the only way to retrieve the information is to inspect every element in the array until you find the information you need - this is often referred to as a 'brute-force' method, and it's highly inefficient and extremely slow. As I'll explain, variant-attributes provide a very efficient and highly performant alternative to this approach in LabVIEW.
A real-world scenario that may help cement this concept would be the task of looking up a word in a dictionary - the word itself is the unique identifier and the information we're hoping to retrieve is the definition of that word. No one would ever try to find a word by inspecting every page in order, as this could take an extremely long time. Instead, we quickly skip to the word we want thanks to the fact that the dictionary stores the word in a sorted order. A typical dictionary (especially a print edition) also has the luxury of being a predefined dataset that remains fixed - words are not regularly added or removed.
In software, large datasets are often dynamic - elements are regularly added, changed or removed, which necessitates an efficient algorithm to easily find, retrieve, store and modify these items. I recently published this Measurement Utility, which employs several lookup tables that I'll use as examples. If you're not familiar with it, this utility is an architectural illustration of how to abstract measurements, the hardware that they measurements interact with, and the results that individual measurements return. The framework keeps track of the measurements that are currently running, the hardware that the system has access to, results from completed measurements, and other characteristics of the system. Since the framework is designed to run arbitrary measurements with arbitrary (but compatible) hardware, I needed a dynamic and performant way to easily store and retrieve various pieces of information.
The Measurement Utility uses a total of seven lookup tables to store various pieces of information, all of which are retrieved using a unique identifier string. If you're interested in exploring any of these and their use, look for them in the private data of Controller Object (in user.lib). The data-type of the value returned is predefined and indicated in the parenthesis:
- Table 1: Given the name of a measurement, return the queue to send messages to this task (Queue Reference)
- Table 2: Given the name of a measurement, return the Object representing this measurement (Class)
- Table 3: Given the name of a piece of hardware, return the Object representing this device (Class)
- Table 4: Given the name of a measurement, return an array of device types (ie: DMM, FGEN) it needs (Array of Strings)
- Table 5: Given the type of hardware needed, return an array of device IDs (ie: PXIe-4110) that match the type (Array of Strings)
- Table 6: Given the device ID of a piece of hardware, return whether or not it is currently in use (Boolean)
- Table 7: Given the name and time of a previously run measurement, return the Object representing the results of this measurement (Class)
Before going any further, we need to understand what a variant-attribute is. A variant is a data-type in LabVIEW that can be used to encapsulate and store any piece of data in LabVIEW; however, nothing is actually stored in the variant when using it as a lookup table. What we care about for the sake of creating a lookup table is a little-known property of the variant data-type: it can store attributes! If you look under the 'Cluster, class and variant' palette and dig into the 'variant' sub-palette, you'll see the API that we'll use - in particular, we care about the following functions:
- Set Variant Attribute
- Get Variant Attribute
- Delete Variant Attribute

Figure 1: The API for storing and retrieving keyed-value-pairs using Variant Attributes are straight forward and easy to use
This very simple API takes advantage of very high-performance algorithms under-the-hood to sort, manage and retrieve keyed-value-pairs. As per usual in LabVIEW, you don't have to know or understand how this mechanism works to take advantage of it, and it saves you the trouble of trying to keep a dataset ordered and writing the algorithms necessary to parse it efficiently (think hash tables and linked-lists).
One of the logical next questions is, 'how much more performant is a variant-attribute table versus simple brute-force?' The actual speed will obviously vary depending upon where in an array the data value would be located, but to compare algorithms you always examine the worst-case scenario. The worst-case-scenario for brute force is that you'll have to look through every single element before finding an item at the end, so we denote this as O(N) complexity, meaning that there is a linear relationship between the number of elements and the amount of time this operation may take. Variant-attributes are implemented using a C++ std:: map structure (this has not always been the case - only in more recent versions of LabVIEW), which has an O(log N) complexity, which is a considerable difference, even as N approaches a modest size.
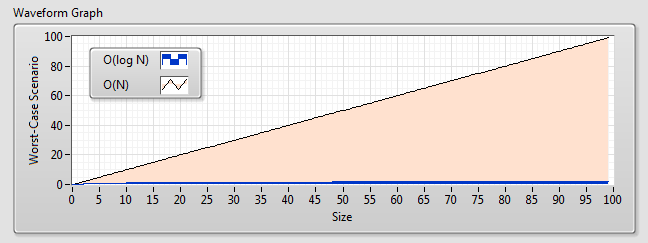
Figure 2: A comparison of the two algorithms reveals a considerable difference between the performance - the performance of the variant-attribute table is represented by the blue line, which is very hard to see when compared with the linear complexity of an array.
In addition, it's also much simpler than writing the code necessary to parse and search an array. The following block diagram illustrates how Table 2 is used in the Measurement Utility to retrieve the specific object representing a measurement based on the name.
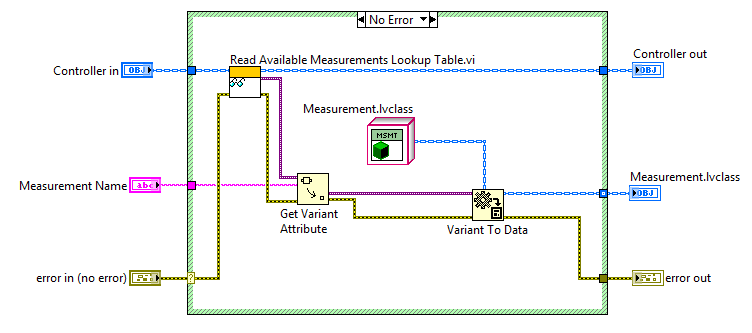
When loading a new measurement into the system, tables 2 and 4 are populated with information: Table 2 is the only location where the Measurement Object is stored (to avoid data copies), and Table 4 allows quick retrieval of the required hardware types when needed. You could argue that table 4 is unnecessary, but since retrieving this information is a common operation (perfored everytime a user selects a measurement from the UI drop-down), I made the design decision to not fetch the measurement object every single time.

For those of you familiar with the Actor Framework, the Measurement Class is actually derived from the Actor Class. Everytime a measurement gets spun up, the queue for this actor is stored in Table 1, which makes it easy to retrieve anytime a message needs to be sent to that measurement. Upon completion of the measurement, that queue is deleted from the lookup table. Results are returned (as an object) from measurements upon completion, which are stored in yet another lookup table (Table 7). This is especially useful, since we can easily accrue a large number of results, and we want users to be able to quickly retrieve and review results.
Hopefully this gives you a good understanding of how variant-attributes can be used as a much more efficient alternative to arrays. If you're interested in learning more, I would encourage you to explore the Measurement Utility referenced by this article, here. As usual, let me know if you have any thoughts or feedback or want additional explination!
NI Director, Software Community
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
