- Document History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Dictionary Library (Key Value Pairs)
DEPRECATED - For new designs use Tree API. Its much better 🙂
https://forums.ni.com/t5/LabVIEW-APIs-Discussions/Tree-API/td-p/3690049
The Dictionary Library enables developers to dynamically define global key-value pairs and access them by name anywhere in their LabVIEW application. The library uses variants when returning values and requires knowledge of casting variants to different data types and handling errors.
The implementation of the dictionary is based on an object oriented plug-in architecture. This allows the user to implement their own core responsible for basic behavior of the library, overwriting the basic Dictionary core class. The latest version of the library includes a human readable INI file core. You can save, edit and load a dictionary from a user friendly format.
The three implementations that are available right now are variant attribute, human readable ini file and binary file.
- The Variant Attribute implementation is built on top of LabVIEW variants and is characterized by high performance.
- The file implementation offers the dictionary data type to be stored and retrieved between application executions without any additional programming.
LabVIEW 2016 or higher required.
Please provide feedback and ideas for improvement in the comments below. Also feel free to link to your own Dictionary cores, if you create your own.
Dictionary is also known as associative array, map or symbol table. Learn more here: https://en.wikipedia.org/wiki/Associative_array
The library is dependent on the Extensible Session Framework (ESF) package which can be found here: https://forums.ni.com/t5/Reference-Design-Content/Extensible-Session-Framework-ESF-Library/ta-p/3522...
Software Requirements
- LabVIEW 2016
- ESF v2.4.0
The Dictionary Library can be installed from the VI packages below using VI Package Manager. Examples for the Dictionary are included in a separate ZIP file below.
Certified TestStand Architect
Certified LabVIEW Architect
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
There will be videos, documents and tutorials soon on using this toolkit.
Certified TestStand Architect
Certified LabVIEW Architect
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
One possible extensions would be the implementation of a fixed size "cache" where the oldest entry is automatically discarded if space runs out. In my particular application, the potential need for a given entry drops dramatically with age and things would not work without size limit, because lookups would become slower and slower and we would quickly run out or memory.
(My implementation is also based on variant attributes, but relatively specialized to my particular problem).
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thats a great idea. I will write something like that as an example. But I would probably make it a combination of both the file and variant approach, so that the variant stored value, if its not accessed for a long time, will auto store in a file. And if it was accessed then it will be reloaded from file into memory. This would handle performance and persistance in a seamless way. How would you like that?
Certified TestStand Architect
Certified LabVIEW Architect
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Offloading to file would probably not be useful in my case because a lookup would be too slow compared to simply recalcuating the missing entry from scratch. We also won't save that much because the "key" is several hundred bytes, so the variant attribute data itself would get large and slow. During fitting we generate a couple of hundred entries per second, most of them only to be used again within the next few seconds. In my case, calculation is about 15-20ms while retrieving from cache is 400-500x faster. Cache operations are the critical section shared by all parallel instances and thus need to be as fast as possible to avoid contention, especially if the number of cores is high. I currently get a proportional speedup with the number of cores, but that will probably flatten out with many more cores.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
The default path for file based dictionaries is based on the application path - which for a typical Windows application (installed in Program Files) will be a read-only directory. Perhaps it would be better to use the temp directory, or the running user's document folder?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thats a good idea. I will do that once I have some time 
Certified TestStand Architect
Certified LabVIEW Architect
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Looking for a Dictionary/CVT type solution for one of my projects I ended up writing a performance comparison of some of the options I found:
Functional Global with Regular Array Search based Key Lookup
Functional Global with Variant Based Key Lookup
These have all several differences in their functionality obviously (how they handle or not handle different data types, whether you can add or delete tags on the fly - if you need any other reference than the tag,how they are optimized for dynamic vs static tag operations etc.), but the core functionality I tested was dictionary and tag creation, Tag writes and reads (dynamic only (tag not repeates in this case), but I did allow multiple writes in one VI call if supported, as it is in the dictionary API).
The Dictionary Library at first seems very slow, when you just do some lazy testing i the IDE. One of the main reasons for that though is just that, unlike the others, its VIs have debugging enabled. Perhaps that should be disabled by default?
With debugging disabled and constant folding avoided - in a built application, the Dictionary Library outperforms all the truly comparable alternatives, even the CVT which I thought would be in a class of its own based on more simple testing. That was great news as I was leaning towards using CVT, but had issues with the fact that it does not allow easy dictionary modifications on the fly.
The fastest option of them all is a functional global with a variant based key search, but thats a much less generic solution unless you also make it support more data types (which I did not cover here).
Here is a summary of the normalized results (the values are relative to whatever was the fastest option for the task, so 3,0 for example means it took 3 timeas as long as the fastest option):
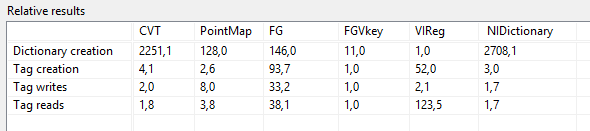
Such test results have limited usefulness when the actual test code is not included...but for now I'll just post them without the test code (test code would require all the source code of all the different solutions too so that's a bit messy).
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Just to be clear, is it safe to assume this benchmark uses:
-A simple data type like a double so overhead of copying the value is 0?
->I think this would explain the point value map, which has a bunch of other stuff stored with the actual value.
-Uses a dynamic set of names (for example, in a for loop repeatedly reading A, B, C, A, B, C)
->This would kill the advantage of the CVT's caching and explain that result.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
That is correct. The benchmarking was deliberately geared towards simple data types and the worst case when it comes to key lookup. If I had used a complex data type and/or static tags, the results would definitely be different. For my current use case that was not so important (I do not need to access one and the same tag over and over again so often that the static access time is critical - but there are plenty of cases where I need to access a large number of different tags with the same accessor.
I quickly rewrote the tests now to use static calls. The CVT takes advantage of caching in its dynamic read/write nodes, but also has a static version which you can use when you know up front that the tags will be fully static...(saves execution time by never even checking if the tag has changed) so I included bot alternatives here ("CVT-dynamicnode" and "CVT-staticnode"):

The Dictionary Library still holds its end. The CVT static node is the fastest in such a scenario, but not by much (on my test machine that is, its probably different on a slower target like a cRIO for example...).
(Note that I have not added lookup caching to the Function Globals here, if I did the variant based one would perform similar to the CVT.)
If I get the time I will create a test that is geared towards complex data types later. I'm also planning to make a feature table (to have a litte in-house presentation about this whole topic). Performance and its variation depending on the use case is after all just one of many differences.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I ran the tests with more complex data types as well (dynamic tags), in which case not all the alternatives support the type.
First here is with a cluster (containing an I32,one string and one small DBL-array):
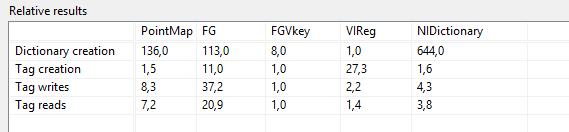
The CVT does no longer (I was a bit surprised to see) support variant as a data type so it was not tested with this cluster.
Then I tried using a variably sized DBL array instead, which the CVT polymorhpism supports:
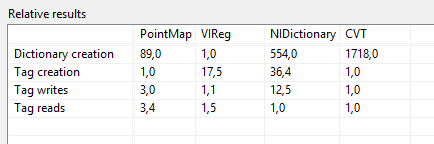
That concludes my performance testing for now I think.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I would just like to point out that NI Dictionary uses Variant Attributes mechanism in the background. This means that you can expect very similar results for the default dictionary core.
Certified TestStand Architect
Certified LabVIEW Architect
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Mads wrote:
I ran the tests with more complex data types as well (dynamic tags), in which case not all the alternatives support the type.
First here is with a cluster (containing an I32,one string and one small DBL-array):
The CVT does no longer (I was a bit surprised to see) support variant as a data type so it was not tested with this cluster.
Then I tried using a variably sized DBL array instead, which the CVT polymorhpism supports:
That concludes my performance testing for now I think.


Interesting, I'm very surprised the point map is still so many times slower. Nice benchmarks to have though
CVT never supported variants unless it was a while ago.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Since this became a benchmarking thread of sorts, I wanted to cross-post this here:
https://lavag.org/topic/19722-lv2016-new-in-place-struct-border-nodes-for-variant-attribute-access/
It would likely speed up CVT and the point-value map, not sure about this dictionary. I'm curious if there is a perf diff between in-place access of something small like a dbl and then branching the wire vs a direct read. If the direct read of the attribute is actually copying the entire variant into a new structure before converting to a dbl, I could see the in-place access as being significantly faster, but its worth testing.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Using the new IPE Variant Attribute Get/Replace functionality introduced in LabVIEW 2016 speeds the dictionary up quite a bit. With a dictionary of DBLs the write operations for example on my test machine ran about 1.5x faster
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Are you telling me that my toolkit is accidentally better in LV 2016? 
Certified TestStand Architect
Certified LabVIEW Architect
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
No, you'd have to change it to use this feature: https://lavag.org/topic/19722-lv2016-new-in-place-struct-border-nodes-for-variant-attribute-access/
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
oh, I think there is no way to use it in this API, but good to know it exists, thanks
Certified TestStand Architect
Certified LabVIEW Architect
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
It can be used in the API (the benchmark I referred to is from an actual modification of the API), but that would mean that you would need to have a separate version for LabVIEW 2016 and newer, which is not ideal of course.
(Would be cool if something like that could be solved using a conditional disable structure...allowing you to convert code from 2016 to earlier versions with the old implementation chosen - and still be able to forward-convert to 2016 AND get the 2016 version...but I'm not sure that would even be logically possible 🙂 )
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
you can build a core optimized for LV 2016 and post it here, I would be super happy for anyone sharing their cores
Certified TestStand Architect
Certified LabVIEW Architect
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi,
Polymorphic subvi Broken, Am i missing something to install ?

