- Document History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
LabVIEW Current Value Table (CVT) Library
Many embedded and industrial control applications require a mechanism to store and manage data in one location in the application so that different parts of the application have access to the current value of I/O channels and others variables. The Current Value Table (CVT) is a set of LabVIEW VIs that developers use to store and retrieve data asynchronously from different parts of an application. The CVT is based on functional global variables, also called LabVIEW 2 style global variables, and can be used on most LabVIEW targets.
Description
Machine control, automation and monitoring applications are typically developed as a number of independent processes running on one or more systems. Each process performs a separate task such as communication to other systems, I/O, control logic, data logging, etc. These independent processes share a set of common data or variables which allows them to work together to accomplish the tasks of the application. Sharing one common set of data enables centralized I/O operations with the I/O data being shared by many processes.
The Current Value Table (CVT) serves as the central data component and can be used in a wide range of applications. It allows other application components to share a common data repository and have direct access to the most up-to-date value of any variable used between components. Using this architecture one component in the application can handle all of the I/O operations and share the I/O data variables or tags with the rest of the application components. Application operations such as alarm detection, user interface updates, process logic, etc. are all handled by separate processes that share the same data repository.
Figure 1: Placing the CVT in context of the application functional blocks
Implementation
The Current Value Table is implemented in a two layer hierarchy consisting of core VIs and API VIs. The core contains all of the functionality of the CVT, including the data storage mechanism and additional service functions. The API VIs provide access to the CVT functionality in a simple interface. There are three groups of API functions that provide slightly different access to the CVT and vary in flexibility and performance, as well as easy-of-use.
Figure 2: CVT VI Hierarchy
The core data structure consists of two VIs which support tag management for the entire CVT, and an additional data storage VI for each data type supported.
The Memory Block polymorphic function stores all data for the system, and consists of a single VI for every data type supported. This functional global variable allows you to clear memory, read or write a single value in memory, and read or write a set of values in a single call.
The Tag List and Group List functions store all information necessary for the access and management of that data. The tag list stores the name, type, description, and memory location of each tag. The group list stores information about any groups formed in the table. Both of these functions store information by name in the form of variant attributes. Variant attribute "get" and "set" functions provide an extremely fast lookup which is superior to a linear array search for data sets larger than approximately 40 tags.
Users can extend the supported data types in the CVT by using the current VIs as a template and adding VIs for additional data types. Booleans, 32-bit integers, double precision floating-point numbers and strings are currently supported.
Core
The core VIs consist of two VIs for each data type supported by the CVT. Each of these VIs is configured to provide a set of functions or methods to their callers and uses shift registers to store data between calls to the VI.
The first of these VIs is the data storage VI called MemBlock. It contains a shift register which stores all of the CVT data for a single data type. It contains a few basic functions (Init, Read, Write) that provide access to the data. Different variables of the same data type are stored in an array in the MemBlock VI. To access an individual variable the caller needs to know the index of the desired data item in the array.
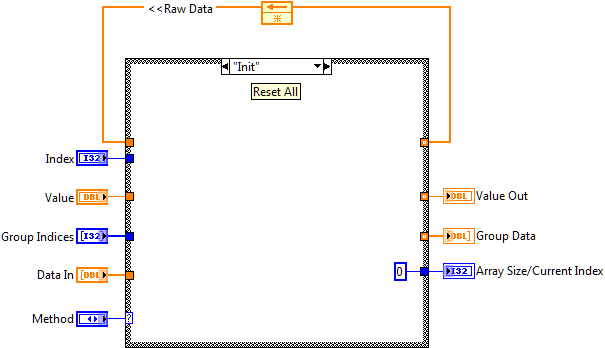
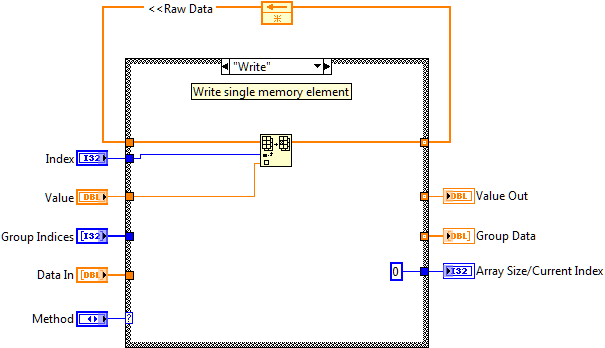
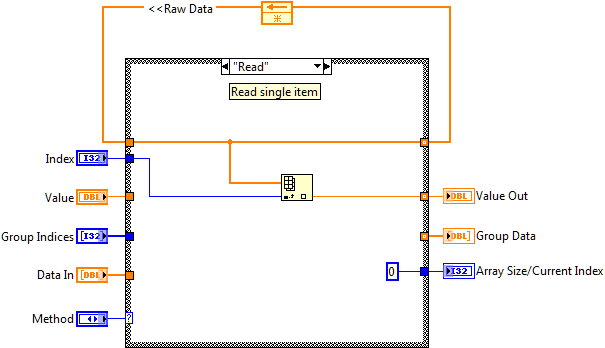
Figure 3: Implementation of the CVT Memory Block Core VI
The second core VI (Tag Memory) maintains a list of properties for each of the values stored in the Memory Block VI including the name and index of each value. This VI enables an application to retrieve the index in the storage array using the variable name. It also stores a string description for each value.
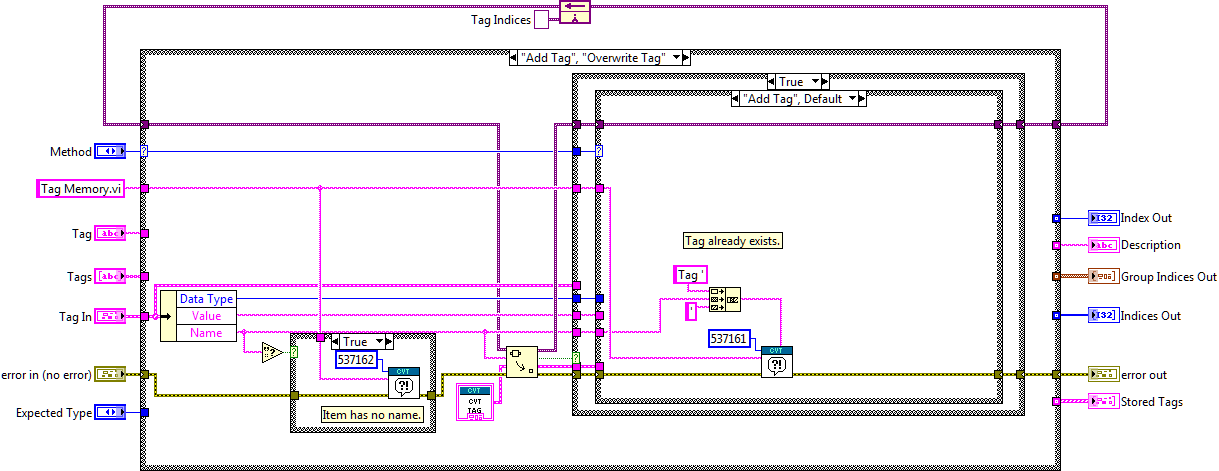
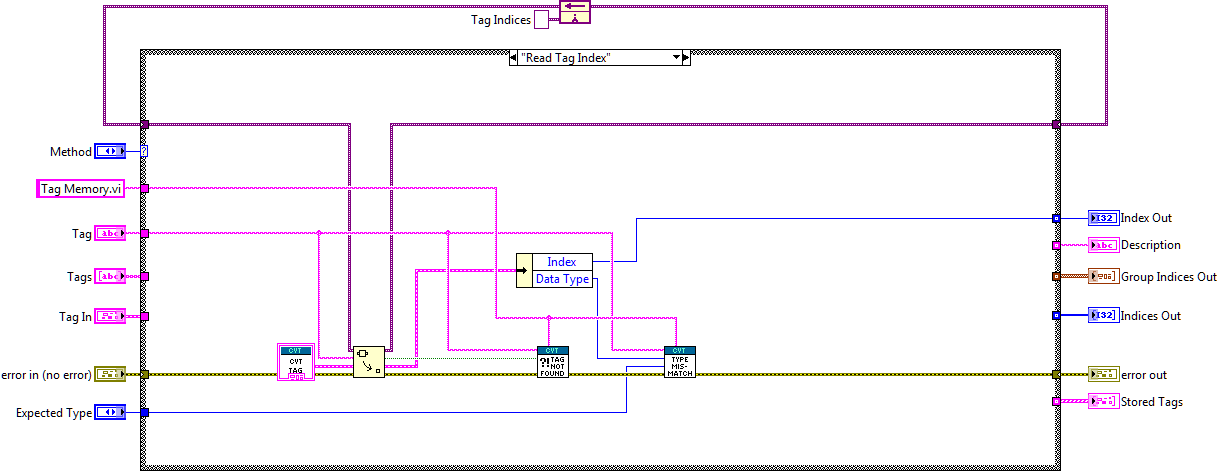
Figure 4: Implementation of the CVT Tag Memory VI
API - Using the CVT
The CVT contains three sets of API functions to provide different interfaces that can be chosen according to the needs of an individual application. The basic API provides simple write and read functionality. Two additional APIs provide a higher performance interface to the CVT, but place some restrictions on the application when using the CVT. All three APIs share the same common core VIs and can be used in conjunction with one another, so you can choose the appropriate function for each individual access to the CVT.
Create Tags
Before the CVT can be used to store and retrieve data it needs to be initialized to allocate memory in the Memory Block and define the variable properties in the CVT Tag Memory. The initialization of the CVT is defined using a cluster array that contains the attributes of the tags used in an application.
Version 3 of the CVT introduces a new cluster which defines groups of tgas in the CVT. This cluster is incompatible with the cluster used in prior versions of the library, but a conversion VI is provided for backwards compatibility. This cluster can be created as a constant on the diagram or loaded from a file. Version 3 of the CVT also adds the ability to create new tags as needed during runtime, without overwriting existing tags. The initialize VI allows the user to select whether or not they wish to clear the C
Figure 5: Initializing the CVT using a constant cluster array
Load From File
Rather than specifying the CVT Tags to Create as a constant or control, it is generally desirable to load the configuration from a file. Once the tags have been added the current tags your system requires, the current values can be saved to disk for documentation or system set up. Using a file allows you to modify the available tags and the properties of tags without having to modify the code of your program. An XML editor also reduces the effort required to create and configure large tag lists. The CVT API includes the CVT Load Tag List VI to load the XML tag configuration file.
Figure 6: Loading the CVT TagList from a file
Standard API
The standard API contains functions to read and write data items in the CVT using the variable name as an identifier. Using the standard API the variable name can be a static string or can be created at runtime using the LabVIEW string functions. In the API call, the variable name is used to lookup the index of the variable and then the value is accessed using the index.
To improve performance, version 3 of the CVT only performs the lookup on the first call, if the lookup previously failed, or if the tag name input changed from the previous iteration. This API uses polymorphic VIs to switch between data types. For writes, this data type is selected automatically based on the wire type. Reads can be selected by providing a default value or by manually selecting a type. The appearance of the VI will change based on the instance selected.
Figure 7: Example accessing different CVT variables using the basic API
All of the basic API functions, including the initialization VI, are contained in the main CVT function palette which is installed in the User Libraries function palette in LabVIEW.
Figure 8: CVT Basic API Function Palette
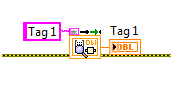
Static API
The Static API (Static Write.vi, Static Read.vi) is very similar to the basic API. However it requires that you use a static name (constant string) in your application when accessing a variable. This restriction allows each instance of the Static API to only perform the variable index lookup operation once on the first call to each instance. It then buffers the index for subsequent accesses providing a significant performance advantage when repeatedly reading or writing the same variable in the CVT. The Basic Example shows how to use the Static API.
The Static API functions are available in the Advanced subpalette of the main CVT function palette.
Figure 9: CVT Static API Function Palette
Index API
The Index API is an extension of the Static API and provides even better performance. Using the Index API you use two VIs to access a value in the CVT. The first VI is used to retrieve the index of a variable (Get Index.vi) in the CVT. This step is only performed once for each variable used. Then the index is used to access the variable value (Write Index.vi, Read Index.vi). This provides the thinnest possible API to repeatedly access the same value in the CVT. See the Advanced Example for how to use the Index API.
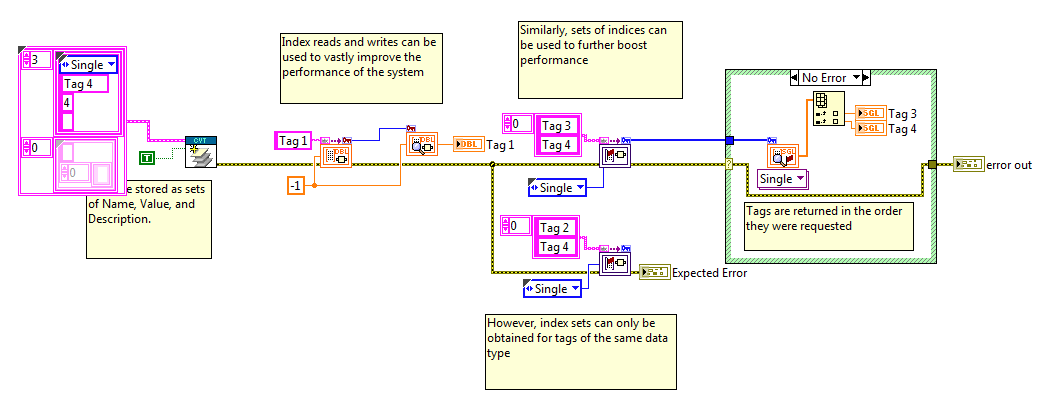
Figure 10: Example using the CVT Index API
The Index API functions are available in the Advanced subpalette of the main CVT function palette.
Figure 11: CVT Index API Function Palette
For sets of tags which share the same data type, the Advanced API can be used to further boost performance by eliminating the sub-VI overhead of each lookup in memory. Performance will vary, but a rule of thumb is to use set of indices any time you wish to access three or more tags of the same type. Because tag names themselves are untyped, the Advanced API look-up function returns the tag type along with the references in order to provide a type confirmation to the application code.
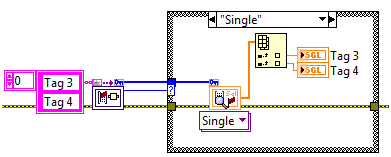
Group API
Sometimes, it can be beneficial to attach a name to a set of tags of varying data types rather than referencing each tag individually. Version 3 of the CVT adds a group API which allows the user to read or write a set of tags simultaneously. One method for forming a group is to create the group during initialization.
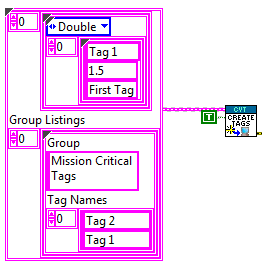
Groups can also be formed at run-time. Once a group has been formed, it can be accessed by the group name rather than the individual tags. Similarly to the Standard API, a look-up will only be performed if the group name changes or if an error occurs. Users cannot modify an already formed group, but groups can be deleted and reformed using this API. Care should be taken to ensure that tags are looked up after a group has been deleted or reformed. Once the lookup has been performed, the group can be read as a whole, in the order specified.
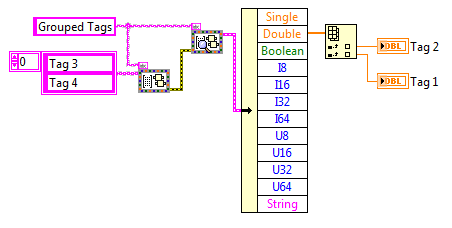
Utilities Functions
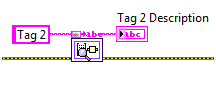
In addition to the VIs that access the stored variable values, the CVT also provides utility VIs to access additional properties or attributes of each variable. The current Utilities API provides the ability to retrieve the variable description. The description is a string attribute associated with each variable that may be used to store arbitrary information that relates to the variable.
Read Tag Description.vi provides a tool for retrieving the stored description of a tag.
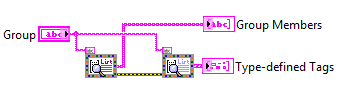
 List Grouped Tags.vi and List Grouped Tags By Type.vi provide a utility for retrieving the members of a group. The first function returns the full list as entered. The second returns a list which is organized by type, with a type descriptor for each set.
List Grouped Tags.vi and List Grouped Tags By Type.vi provide a utility for retrieving the members of a group. The first function returns the full list as entered. The second returns a list which is organized by type, with a type descriptor for each set.
Finally, Save CVT to Disk.vi and Save Grouped Tags to Disk.vi provide tools for storing the currently loaded CVT data to disk. Save CVT to disk will initiate a lookup of every tag in the system on first call, and will use that information to perform an extremely efficient index read on the data on subsequent calls. Save Grouped Tags to Disk will perform a lookup in the same fashion as the Basic API. Both functions will then pack the data into an XML file and save it in the location specified.
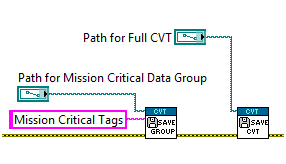
The Utilities API functions are available in a subpalette of the main CVT function palette.
Figure 12: CVT Utilities API Function Palette
These properties are stored in the TagList core VI for each data type. In order to add additional variable properties to the CVT, a developer must add the new property to the CVT Tags to Create control TypeDef and then add a new case to the TagList core VIs to provide a method to retrieve the new property from the TagList. API functions can be added following the template of Read Tag Description VI.
Examples
Using the CVT is very simple in most applications. The first step is to define the variables that will be used by the rest of the application and shared through the CVT. The variables to be used need to be defined in the tag configuration array, either as a constant on the diagram or using another method.
In the code of your application the CVT needs to be initialized once by passing the tag configuration array to the Create Tags VI. Once the CVT is initialized you can write and read any of the variables in the CVT using the three previously described APIs.
If you try to access a variable not defined in the CVT, the access function returns an error using a standard LabVIEW error cluster.
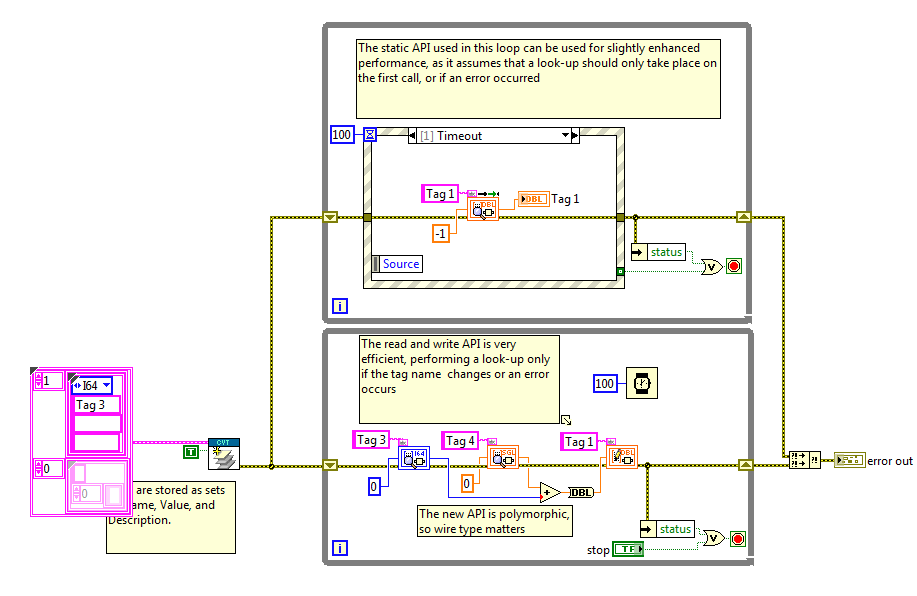
Figure 13: Example using the CVT functions to share data between two loops
Support
Please submit your feedback in the Current Value Table (CVT) discussion forum so that we can improve this component for future applications.
Older Versions
There has been a number of major versions of the CVT library with incompatibilities between version 2 and 3. Previous version's functions have been deprecated, but version 2 is retained in VIPM for preexisting projects. If you have any issues updating to the newer version specifically from the CVT library, please post to the discussion forum.
Installation
The Current Value Table library is available in the LabVIEW Tools Network (LVTN) repository and can be installed directly from VI Package Manager (VIPM).
vipm://ni_lib_cvt?repo_url=http://ftp.ni.com/evaluation/labview/lvtn/vipm
References
Changes in Current Value Table (CVT) Version 3
Discussion
http://forums.ni.com/t5/Components/Current-Value-Table-CVT/m-p/583424
Source Code
https://github.com/NISystemsEngineering/CurrentValueTable
Known Issues
https://github.com/NISystemsEngineering/CurrentValueTable/issues
(This document has been moved from ni.com and was previously located at http://www.ni.com/example/30326/en/ .)
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
