- Document History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
LabVIEW Unicode Programming Tools
Following are my observations and findings while using Unicode in a LabVIEW UI application. The purpose of using Unicode in this application is to localize the UI on the fly in any language without having to change the Computer locale. The application provides a settings page which allows the user to select the language of the UI. Based on this setting all UI components (controls and indicators) are localized into the selected language. The resource strings for all controls/indicators and languages are read from a text file containing Unicode strings.
Disclaimer:
LabVIEW for Windows has limited support for Unicode strings in the front panel controls and indicators. This is not an offically supported feature, meaning that it is not as fully tested as other released parts of the development and run-time environment. In addition this feature is not covered under standard product support and parts of this feature may change in future releases of LabVIEW, i.e. any code developed on this feature may require changes when upgrading to a newer version of LabVIEW. If you have any feedback or questions about using Unicode in LabVIEW post them as comments on this document or in the Developer Zone discussion forums.
The code posted as part of this document has been developed and tested in LabVIEW 2009 running on Windows XP SP3 (English). The VIs are saved back to LabVIEW 8.6. Earlier versions of LabVIEW did not include all of this Unicode support and it is suggested that you upgrade to LabVIEW 8.6 or later if you want to use Unicode in your application development.
This code has not been tested with other operating systems and I assume it will not work on non-Windows OSs, though I expect it should work in Windows Vista and Windows 7.
What is Unicode?
The answer to this question could cover many pages by itself so I will not attempt to provide a detailed or comprehensive explanation of the Unicode standard and its different character encodings. Please consult other online sources for this information. It will be helpful to be familiar with what Unicode is before proceeding with the rest of this document.
http://en.wikipedia.org/wiki/Unicode
http://en.wikipedia.org/wiki/UCS-2
Unicode and LabVIEW
Unicode is not officially supported by the LabVIEW environment, but there is basic support of Unicode available as described in this document. Unicode can support a wide range of characters from many different languages in the same application.
Windows XP (Vista, 7) is fundamentally built on Unicode and uses Unicode strings internally, but it also supports non-Unicode applications. By default LabVIEW on Windows (English) does not use Unicode strings, but rather uses Multibyte Character Strings (MBCS). The interpretation of MBCS is based on the current code page selected in the operating system. The current code page is set using the regional settings of the OS and determines how the bytes in the strings are rendered into characters on the screen. The most common code page is 1252 used by English Windows as well as several other Western languages and comprises the commonly known extended ASCII character set.
http://en.wikipedia.org/wiki/Windows-1252
When the regional settings in Windows are changed the OS may switch to a different code page for rendering strings. For example if you switch to Japanese, code page 932 will be used. Using different code pages allows LabVIEW to have localized versions of the development environment. All code pages include support for the basic ASCII characters used in the English language, as well as a local set of characters. Therefore if you have code page 932 selected, the operating system can still render ASCII characters as well as Japanese.
Using Unicode instead of MBCS, an application can render characters from many different alphabets or scripts without switching code pages/regional settings. In fact all of the language scripts supported in the legacy code pages are included in Unicode and Unicode keeps being expanded with more characters every release. Because Unicode does support more than 65535 characters nowadays, a concept of planes was introduced in conjunction with surrogate pairs. Most of the characters covered by the code pages are included in Plane 0 of the Unicode standard and fit on a 2-byte representation, but more complex characters for mathematics or ancient scripts have been located on higher planes and thus use surrogate pairs as they code point value (and are thus coded on 4 bytes).
http://en.wikipedia.org/wiki/Mapping_of_Unicode_character_planes
A common encoding form of the Unicode character set is UTF-16. UTF-16, depending on byte order is called Big Endian or Little Endian. Unicode in LabVIEW is handled as little endian, also called UTF-16LE. This is important to know when looking at the hexadecimal representation of strings or working with Unicode text files.
| Character | ASCII (hex) | UTF-16 (hex) | UTF-16LE (hex) - LabVIEW |
|---|---|---|---|
| z | 7A | 00 7A | 7A 00 |
| 水 | n/a | 6C 34 | 34 6C |
| Ѳ | n/a | 04 72 | 72 04 |
Table 1: Example of a few characters in ASCII and Unicode
When writing Unicode to a plain text file you commonly prepend a Byte Order Mark (BOM) as the first two characters of the file. The BOM indicates to the file reader that the file contians Unicode text and if the byte order is big-endian or little-endian. The BOM for big-endian is 0xFE FF. The BOM for little-endian including LabVIEW is 0xFF FE. Windows Notepad and Wordpad can detect a Unicode file using the BOM and display their contents correctly.
LabVIEW for Touchpanel on Windows CE
LabVIEW for Touchpanel on Windows CE supports multi-byte character sets (MBCS) — specifically double-byte character sets (DBCS). Under this scheme, a character can be either one or two bytes wide. If it is two bytes wide, its first byte is a special "lead byte," chosen from a particular range depending on which code page is in use. Taken together, the lead and "trail bytes" specify a unique character encoding.” (http://msdn.microsoft.com/en-us/library/ey142t48(VS.80).aspx" target="_blank">http://msdn.microsoft.com/en-us/library/ey142t48(VS.80).aspx<SPAN>) A code page only contains the characters from one particular language such as Korean. Therefore MBCS can only support ASCII and one other set of language characters at a time and you need to select the specific code page for non-ASCII characters to be used in your application. To do that, look for the "language for non-Unicode programs" in the Windows Control Panel.
Using Unicode in LabVIEW
Common Use Cases
A list of common uses of Unicode in an application developed using LabVIEW includes:
Non Unicode
All strings in the application used for display, user input, file I/O network communication (e.g. TCP/IP) are ASCII strings. This is the most common use of LabVIEW and does not require the use or consideration of Unicode.
Non-Unicode = Extension of ASCII based on system code page
ASCII technically only defines a 7-bit value and can accordingly represent 128 different characters including control characters such as newline (0x0A) and carriage return (0x0D). However ASCII characters in most applications including LabVIEW are stored as 8-bit values which can represent 256 different characters. The additional 128 characters in this extended ASCII range are defined by the operating system code page aka "Language for non-Unicode Programs". For example, on a Western system, Windows defaults to the character set defined by the Windows-1252 code page. Windows-1252 is an extension of another commonly used encoding called ISO-8859-1.
http://en.wikipedia.org/wiki/ASCII
http://en.wikipedia.org/wiki/ISO-8859-1
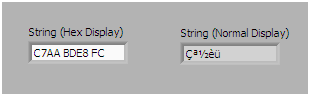
Figure 1: LabVIEW ASCII string in Hex and normal display showing extended ASCII characters
Unicode
• The application reads Unicode data from a file or other source and displays it using a non-Unicode encoding (ASCII based) on the user interface. In this use case it is assumed the Unicode characters are limited to the subset supported by extended ASCII.
• The application reads Unicode data from a file or other source and displays it as Unicode characters on the user interface.
• The application internally uses characters encoded in a non-Unicode way, including input from the UI by the user, but needs to write data to a file or other destination in Unicode.
• The application uses Unicode strings internally including input from the UI and writes Unicode data to a file or other destination.
LabVIEW Configuration for Unicode
To use Unicode in LabVIEW you must enable Unicode support by adding the following setting in the LabVIEW.ini file. After making this change you must restart the development environment.
[LabVIEW]
UseUnicode=True
LabVIEW Controls and Indicator Properties
The LabVIEW string controls and indicators have two private properties related to entering and displaying Non-Unicode (extended ASCII) or Unicode characters. These properties are not exposed through the regular property node; access to these properties is provided through subVIs as part of the examples included with this document.
• Force Unicode Text
• InterpretAsUnicode
Force Unicode Text is a property which can be enabled and disabled on the string control using the context menu of the control or indicators.
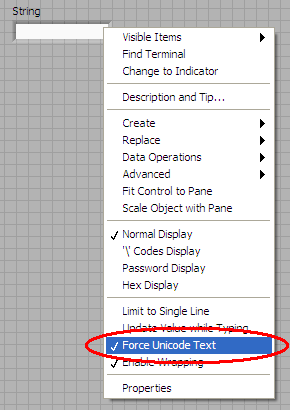
Figure 2: Setting the Force Unicode Text property on a string control
The Force Unicode Text property affects how text entered from the keyboard is converted to a string (byte stream) in the diagram. If text is passed from an ASCII keyboard and this property is turned on, then the text is automatically converted to the Unicode equivalent of the ASCII characters. Typically this means that every single byte character is converted to the two byte Unicode equivalent.
InterpretAsUnicode is a property which can be enabled on text elements of different UI controls and indicators, such as the text of a string control/indicator, the caption of a control/indicator, the Boolean text of a Boolean control/indicator, etc. This property controls whether a string value passed to the text element is interpreted as an ASCII or Unicode string. SubVIs provided with the example in this document allow you to pass strings to different UI elements and select whether you are passing an ASCII or Unicode string.
Note: The state of the InterpretAsUnicode property of a string element may be changed dynamically if text is pasted or entered into the text element by the user. The display mode (InterpretAsUnicode) of the text element will automatically adapt to Unicode or ASCII depending on the type of text entered into the control.
• If you paste a Unicode string into a text element the InterpretAsUnicode property is turned on.
• If you paste a regular ASCII string into a text element the InterpretAsUnicode property is turned off.
For example, if the display mode of a string control is Unicode (InterpretAsUnicode property on) and text is entered from an ASCII keyboard, the display mode will be switched to ASCII and the current value of the string control will be interpreted and displayed as ASCII characters. This can cause issues if the Force Unicode Text property is enabled for a string control. Entering regular ASCII text will cause the string control to interpret all data as ASCII, however the Force Unicode Text property will automatically convert the new characters entered in the control input to Unicode data. These two conditions combined will cause ASCII text to have a ‘space’ between each letter entered. These spaces are actually the extra Null byte, which are the second byte of each of the ASCII characters converted to Unicode. To resolve this issue you must detect the keyboard input and set the Text.InterpretAsUnicode property of the string control to True to properly display all text as Unicode. This is shown in the examples.
Labels and Captions
When localizing the name of a control or indicator on the user interface you should always use the caption of the control instead of the label. The label is part of the code of the VI (similar to a variable name) and should not be changed. The caption should be displayed instead of the label and can be changed at run-time using the VIs provided.
Listbox, Multicolumn Listbox and Table
The Listbox, Multicolumn Listbox and Table controls have different behavior in terms of processing Unicode strings from the rest of the text elements described previously. These controls so not use the InterpretAsUnicode property. Instead they look for a BOM (Byte Order Mark) on any strings passed to them. If a string passed to these controls starts with a BOM (either 0xFFFE or 0xFEFF) then the string will be handled as Unicode. This allows you to mix both Unicode and ASCII strings in the same control. The examples include subVIs to pass strings to these controls and mark them as Unicode using the BOM.
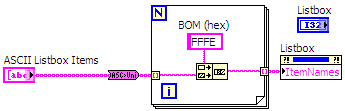
Figure 3: Adding the BOM to Unicode strings to update a listbox
Unicode Fonts
In order to display Unicode strings on your user interface the fonts you are using must have the necessary support for all the characters you are using. If you are using an extensive set of characters from languages using non-latin characters you should verify that your selected fonts have the necessary character support.
Two specific fonts commonly available on Windows that include most Unicode characters are Arial Unicode MS and Lucida Sans Unicode.
Programming Unicode in LabVIEW
Converting ASCII Strings to Unicode
Included in the examples are two very simple VIs to convert an ASCII (MBCS) strings to Unicode and vice versa. These VIs use functions provided by Windows to detect the current code page used for the MBCS and handle the conversion.
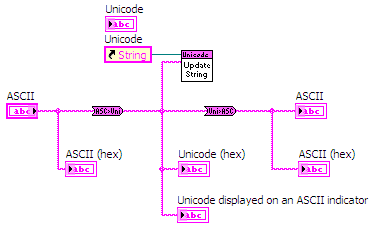
Figure 4: Converting between ASCII and Unicode strings in LabVIEW
The conversion VIs are polymorphic and can handle scalar strings as well as 1D and 2D string arrays.
Displaying Unicode Strings on Controls and Indicators
The attached project includes a number of examples showing how to display Unicode strings on different UI controls and indicators. For each of these control types subVIs are included to pass strings to the control and their caption and specify whether the string should be treated as Unicode or not. The following UI controls and indicators are supported with specific VIs:
- Caption of any control or indicator
- String
- 1D String Array
- 2D String Array
- Boolean
- Ring
- Listbox
- Multicolumn Listbox
- Table
Using control properties you can also access these controls inside of other data structures such as a cluster.

Figure 5: Converting an ASCII string to Unicode and display it on a string indicator, 1D string array and 2D string array
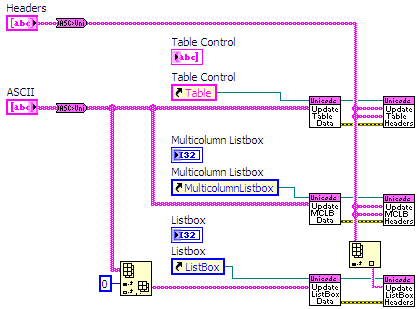
Figure 6: Converting an ASCII string array to Unicode and display it on a Listbox, Multicolumn Listbox and Table
Reading Unicode from a String Control
In order to read Unicode strings from a front panel string control there are a number of settings and that need to be made:
1. Enable the Force Unicode Text property of the string control from its context (right-click) menu.
2. Enable the Update Value while Typing property of the string control from its context menu.
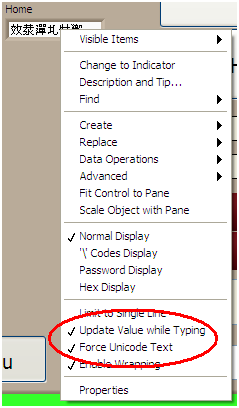
Figure 7: Enable the Force Unicode Text and Update Value while Typing properties
3. Add an event case to the Event Structure for the Value Change event of the string control. In the event case wire the control reference and new value from the event to the Tool_Unicode Update String VI as shown in the following diagram. This will update the string control as the user is typing to keep the InterpretAsUnicode property set to Unicode, while entering ASCII characters.
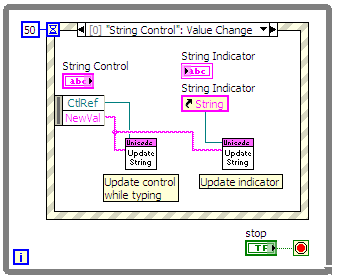
Figure 8: Event Handler for the Value Changed event of the string control
Reading and Writing Unicode Strings to Text File
When reading and writing text files it is important to know if the contents of the file is ASCII or Unicode. The Read from Text File function in LabVIEW does not know whether the contents of the file is ASCII or Unicode. Therefore you need to check to see if the file contains a BOM (Byte Order Mark) at the beginning of the data read from the file and then process the data accordingly.
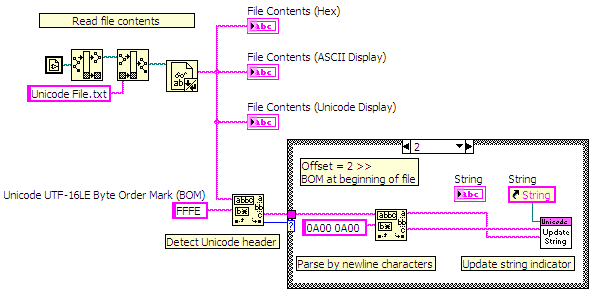
Figure 9: Read a Unicode text file and process
To write Unicode text to a file, convert all your strings to Unicode and then prepend the BOM before writing the final string to a file using the Write to Text File function.
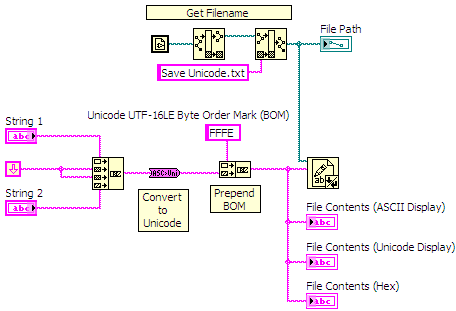
Figure 10: Write Unicode text to a file
Release Notes
June 2014 - Added VI package of the Unicode tools. v 2.0.0.4 Includes wrappers for built-in functions for converting between LV Text and UTF-8. Function palette moved to Addons palette.
February 2019 - Updated VI package to include minor bug fix that occurs in Windows 10 and LabVIEW 64-bit. Latest version is 2.0.1.5. The VIP will also be added to the LabVIEW Tools Network VIPM repository.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi,
I tried this library and it works great for standard labview controls and indicators, but when I try to use it to interpret the string returnd from a .net control inside labview, it doesn't behave as expected.
In my application, I have a data grid view control inside a .net container and when I try to read the text back from data grid view, the string returned has question marks(?) if I enter non-ASCII characters.
Is this the limitation of the library that it only works with the standard labview controls?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
In this case the limitation is the encoding used by the DataGridView (DGV), or possibly .net, and how non-ASCII characters are encoded when they are returned from the control to LabVIEW. I used the DataGridView available on the LV Tools Network for testing and based on my experiements it looks like the DataGridView returns data encoded in DBCS (Dual byte Character Set), not Unicode. Interpreting the DBCS characters as Unicode will not return the proper data.
As a test I used the string '日本IBM' which is Nihon IBM.
In LabVIEW, which uses UTF-16LE, this is encoded as E565 2C67 4900 4200 4D00 (5 characters, 2 bytes each)
In UTF-8 this is encoded as E898 B02C 6749 0042 004D 00 (mix of character widths)
In DBCS this is encoded as 93FA 967B 4942 4D (each Japanese character is two bytes, each ASCII character is one byte)
In addition, DBCS only supports one character set (one language) at a time, and in Windows you need to set the Windows System Locale setting to your desired location for the DGV to return proper DBCS characters. For example if you type or paste in Japanese characters your Windows System Locale must be set to Japan. Otherwise the DGV returns an incorrect string (all ?'s). Without this setting my test string returns 3F3F 4942 4D.
In the Unicode tools, you can use the ASCII to Unicode function to convert proper DBCS to Unicode for display on a LabVIEW control. This function uses the MultiByteToWideChar function in Windows, which handles both ASCII and DBCS.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Is there a way to use unicode text for front panel title (window title). I've tried by pre-appending BOM, but it doesn't help. Also I cannot find Interpret as unicode property.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Christian_L
First of thank-you for the unicode functions. They have been a real help. I have one problem that you may be able to help with. I have a graph, and I need to be able to use unicode for the "Plot.Name" is there any way that you could send me the "Plot.Name.InterpAsUnicode" property node?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Unfortunately the window title and graph plot name do not support Unicode.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
-------------------------------------------
In claris non fit interpretatio
-------------------------------------------
Using LV from 7
Using LW/CVI from 6.0
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Could you add to the toolkit a vi to handle the TipStrip of contorls, please?
Unfortunately the Tip Strips do not support Unicode characters.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Christian_L
I will start with an apology if this is not the place to ask this question. I know little about unicode and less about html. I have a program that is running a test and saving a report in html. it was all hardcoded in English. I was tasked with making it multilingual. I have used your functions to change over the program (thanks again) but now I have to rewrite the code that generates the html report. I think that standard html uses UTF-8 and your functions and labview use UTF-16LE. So I have all the text I need in UTF-16LE, do you have any functions to convert UTF-16LE to UTF-8 if that is even possible.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
RJGats,
I attached another VI to this document which contains a UTF-16 to UTF-8 conversion VI.
http://forums.ni.com/ni/attachments/ni/3016/21/9/Convert%20UTF-16LE%20to%20UTF-8.vi
This is based on the Windows WideCharToMultiByte function. https://msdn.microsoft.com/en-us/library/windows/desktop/dd374130(v=vs.85).aspx
I have not done any testing on this VI, so please validate for your use and use at your own caution.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Christian,
I am developing an application for a Chinese customer and have to translate the VI controls into Chinese. It's an application that I use on our welding systems that get sold to various customers. Your Unicode tools have been extremely useful. My last hurdle is having the Tab Captions also display Unicode (Chinese characters). I am currently using LV 2016. I am trying to use Display Unicode Tab Control Page Tabs.vi which is part of your Unicode tools. As is it works fine. When I try to increase the number of pages by either adding pages or duplicating pages the new pages do not display Chinese characters. Also, if I try to rearrange the pages LabVIEW crashes on me. Lastly when I try to duplicate and incorporate in my application, the reference to the Tab Control I am result in a broken line when I try to connect to Tool_Unicode Update Tab Control Pages.vi. Hoping you can help me out. Thank you so much. .... Nelson Orozco
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Christian_L
You have been so helpful in getting my program changed over to unicode, Thank-you. I have one last problem. I am creating a report in html and it is working fine for all the languages except Chinese. I look at the string just before I send it to a "Write to Text File Function" and it is correct, but when I open the HTML file it wrote it is wrong. any ideas. You will see the problem about the 10 line down in the bad file.


- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Re. Tab Control
To add additional tabs on the Tab control and use them with the Unicode library, follow these steps:
- Add a new tab using the right-click menu on the Tab control.
- Right click on the new control and unselect the Advanced>>Make Page Caption Match Label option. (This allow the caption of the tab, which will be Unicode, to be different from the label which must be ASCII.)
- Copy and paste a Unicode string into the new Tab caption. This changes the model of the caption from being ASCII to being Unicode.
You can now programmatically write new Unicode strings to the Tab caption.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
RJGats,
The first step to debugging this issue is to compare the string in LabVIEW and the contents of the file using a low level hex editor, to make sure that the individual bytes written to file are the same as you have in your LabVIEW string. This will also show the data bytes at the location where the file is starting to show errors.
One possibility is that LabVIEW may be inserting extra bytes. This can happen depending on what VI/function you are using to write the file. For example in some cases during file write, LabVIEW will replace a Line Feed character (0x0a) with a Carriage Return/LineFeed (0x0d0a), which is the standard end of line character (EOL) for Windows. So if by chance your Unicode includes a hex byte 0x0a, LabVIEW may be inserting the extra 0x0d, which would mess up the characters in your file.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Christian_L
Yes the "Write to Text File" is changing or adding codes - not good. The "Write to Binary File" is leaving the body alone but is appending "0000 3416" to the front of the file. Are there any LabView functions that doesn't muck with my data but just writes it to a file?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Christian_L
I found an add-on file write that is not changing or adding anything so I am good. Thank-you so much for all your help I could not have done the conversion without you.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hello Christian,
Again thank you for all of your work in this area and your assistance. I have one last hurdle. The application I have collects a fair amount of data and I need to be able to plot this data. I saw your example for displaying Unicode (i.e. Chinese characters in my application) characters for axis titles and plot titles. The only thing is that I tend to use multiple axes plots with a visible legend as shown in the atttached image. So my question is how do I display Unicode text in the legend box in place of the labels Plot 0, Plot 1, etc. and how do I display Unicode characters for the two Y-Axes Amplitude and Amplitude 2?
NelsonO

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
NelsonO,
Take a look at the new VI attached to the original document (Update Graph Labels Advanced.vi). This should work for XY Graphs as well as Waveform Graphs.
You pass in axes labels and plot labels as arrays. The plot legend must already be enabled for Unicode characters on the front panel as there is no property to enable it for Unicode mode programmatically. You can do this by pasting a Unicode string on any of the labels on the plot legend.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thank you very much for these subVIs, they are very helpful.
But I have a problem with update boolean text. it does not switch to unicode properly.
The problem is that sometimes it works fine and sometimes not.
Thank you
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
hichem55, please provide more detailed information about the code your are using and the problem you are having. What version of LabVIEW are you using. Can you isolate this problem in your code and include a code snippet in your post?
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I am sorry for the delay in replying.
In am using LabVIEW 2016 and I made a small VI Similar to the Example provided with the toolkit (copy paste).
When I switch to Japanese, at first it will not work properly and then after several Language switchs it works fine. I provided some photos



Thank you very much.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hello,
I have table/multi-column Listbox control in Labview
I want to give the user an option to type in/paste Unicode characters. Is this somehow possible?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Dear Christian,
I am a student who is working on a project. My goal is to translate words, from a text based database, from ASCII into UNICODE. I readed your post how to do it, and it works fine on the captions. But when I try to change a Boolean text, it does not work. It works on your test VI, but when I repeat it in my own VI, it does not work. When I copy your controls, it works only on your controls. What do I wrong and how can I fix it. I added my test-VI, containing two new controls and your controls from diffrent VI's.
Downloadlink: https://we.tl/OUxUycyk3N
One other question is: where can I find the property nodes. I changed the UseUnicode=True in the Labview.ini file, but still, I can not find it. I hope you have the time to help me.
Thanks in advance and I am waiting for your replay.
Yours sincerley,
Onno Ilman
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
One other question is: where can I find the property nodes. I changed the UseUnicode=True in the Labview.ini file, but still, I can not find it. I hope you have the time to help me.
https://forums.ni.com/t5/LabVIEW/Multi-language-alphanumeric-control/m-p/3097234
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
when I try to change a Boolean text, it does not work. It works on your test VI, but when I repeat it in my own VI, it does not work. When I copy your controls, it works only on your controls. What do I wrong and how can I fix it.
I have documented the steps to create a new digital control for use with the Unicode VIs in the following document.
https://forums.ni.com/ni/attachments/ni/3016/21/11/Create%20Digital%20Control.pdf
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hello,
I´m already using NI´s Unicode library in my actual application. Now I have to develop a new module were users should navigate via tree control. Tree control should show tags in different languages through runtime. Is it possible to use Unicode strings together with a tree control (e.g. use Cyrillic letters in tree control tag(names)?
Thx for your feedback.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Sammi2k,
Unfortuntaly the Tree Control in LabVIEW does not include any support for Unicode items or tags.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
When I was trying to send Email from LabVIEW, I face some issue with the UNICODE that is not regular Latin characters.
Here is the solution i came with that work for most of the case.
Benoit
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
When I change a char in the middle of a string in a string control, the Update String.vi will set the cursor always at the end of the string, after each single change. Is there a way to restore the cursor position while editing?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Use test selection start property.
Benoit
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Christian wrote:
> Unfortunately the window title and graph plot name do not support Unicode.
Use Windows API, window title can be set to an unicode string.
http://www.ni.com/example/29935/en/

George Zou
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi all,
In order to type in unicode characters in a string control, as suggested it is important to have string control property set to:

as well as having the update string VI in the event structure

Note that "Update String VI" causes the text selection position to move to end of the string, therefore it's important to get String Selection Start/end before running the Update String VI, and reset them after. (the set order is important too, has to be Start and then End)
This way you won't lose your text selection position if you are trying to type in new characters in the middle of the string.
Without resetting the text selection position, the text selection cursor will always move to the end of the entire string as soon as you hit a key to cause value change event, making editing rather annoying.
Hope this helps 😊
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I see that the vis "Update Listbox Data", "Update Listbox Headers", "Update MultiCol Listbox Data" and "Update MultiCol Listbox Header" cotnain strict references to Listbox controls.
This is a problem when I pass the reference to my listbox.
Cast to more specific class fails with "Type mismatch" error.
What should I do in this case?
-------------------------------------------
In claris non fit interpretatio
-------------------------------------------
Using LV from 7
Using LW/CVI from 6.0
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Good day!
I'm trying to make "FormatString"s to accept Unicode, to refrain from converting digital displays of sliders to separate string controls.

Property node does not accept Unicode, or maybe just null characters (English character pairs).

Is there any way to integrate Unicode into FormatString? Have anyone done it?
"When I need the side of a building to view all the code..." -Mark Yedinak
"...when you need a navigation window to view the navigation window..." -Jeff Bohrer
- « Previous
-
- 1
- 2
- Next »
