- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
One more question. :) Concerning general matrix computation,
07-12-2013 06:46 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hello, there.
I always appreciate you for giving comment. 
At this time, I am trying to make a simple matrix computation code.
What I have coded as below.
The input matrix becomes 2 by 2 matrix namely square matrix, under code works fine.
However, the input matrix becomes not square matrix such as 2 by 3 matrix, it does not work.
At cuBLAS GEMM vi, There are the wires for A, B, and C's matrix size.
A, B, and C matrices can be written by using m, n, and k as
> A : m by k (m x k)
> B : k by n (k x n)
> C : m by n (m x n)
I wired them properly, but it did not work.
Because I wired same matrix into A and B. What I wanted to do is getting A square matrix.
Also can be used aAA+bC, however, it is little bit hard to wire A.. I used aAB+bC rather than aAA+bC.
So, A must be transpose and conjugated.
Under(and attached) code has a matrix 2 by 3.
A and B are wired as same matrix, A is conjugate transpose.
Therefore C is 2 by 2 matrix.
In this case, I think m, n, and k are 2, 2, and 3, respectively.
However, it does not make proper result.
It returns an error code as below.
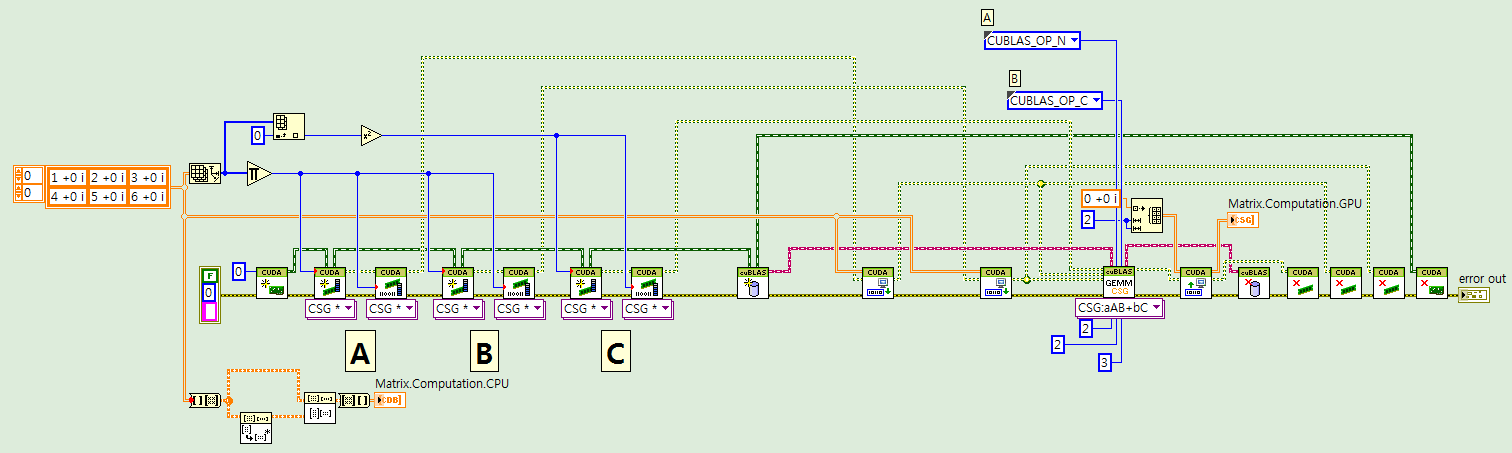
If above(and attached) code is wrong, please let me know where is wrong.
Error code
-------------------------
Error -359630 occurred at call to cublasCgemm_v2 in cublas32_50_35.dll.
Possible reason(s):
NVIDIA provides the following information on this error condition:
code:
CUBLAS_STATUS_INVALID_VALUE = 7
library version supplying error info:
4.1
The following are details specific to LabVIEW execution.
library path:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\bin
call chain:
-> lvcublas.lvlib:CGEMM (aAB+bC).vi:1
-> [Example] generalMatrix.cuBLAS.vi
IMPORTANT NOTE:
Most NVIDIA functions execute asynchronously. This means the function that generated this error information may not be the function responsible for the error condition.
If the functions are from different NVIDIA libraries, the detailed information here is for a unrelated error potentially.
--------------------------
Thank you in advance!
Have a nice Friday 🙂
Albert
07-15-2013 12:48 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I think this is strange because I just have changed some points that can calculate above VI.
At B using "transpose matrix", at GEMM.vi using "CUBLAS_OP_N" not "CUBLAS_OP_C".
I have a question because I guess there is no difference between two options.
Because there is just difference at using array VI(transpose matrix) and using "CUBLAS_OP_C".
Why it did not work previous code and it worked fine..?
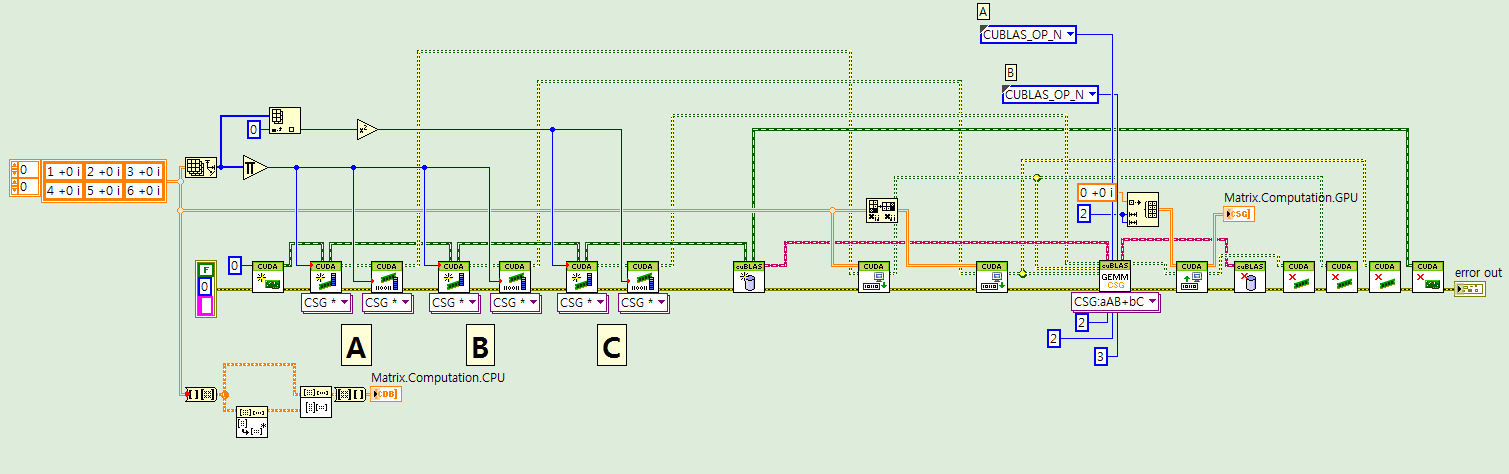
Thank you in advance!
I always appreciate developer this convinient toolkit!
Sincerely,
Albert
01-14-2014 04:14 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I have the same problem... i cant find a way to multiply to matrices that are already in the memory of the Nvidia card:
A(mxk) multiply B(kxn)*
this is just not working, or does anybody every got it work?
I would be very happy if you could help me.... MathGuy maybe ?
thanks.
