- Document History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Hand-written digit recognition using an artificial neural network (ANN) and LabVIEW image processing
Contact Information
Petru Tarabuta, Third year MEng Electronic and Electrical Engineering, expected graduation: 2016
University of Sheffield, United Kingdom
Email Address: petru.tarabuta@gmail.com
Submission Language: English
Description:
This is a software project that does hand-written digit recognition with the help of an artificial neural network (ANN) algorithm. The dataset for the neural network algorithm was captured by the author. This system was inspired by the free online Machine Learning course offered by Stanford University on Coursera.org.
Attached below is the LabVIEW project saved for LabVIEW 2014 and 2011. The zip files contain the images used in the training and test sets, as well as the text files that store the ANN weights matrices Theta1 and Theta2. It should be possible to select one of the images, run the VI and see the predictions and confidence levels being overlaid on the front panel display.
Products
NI software:
- NI LabVIEW 2014
- Vision Development Module 2014
Other software:
- MATLAB
No hardware was used in the project.
The Challenge
The aim of the project was to perform hand-written digit recognition, which is a type of Intelligent Character Recognition (ICR). ICR is a close cousin of optical character recognition (OCR), the difference being that ICR aims to recognize hand-written text or digits, while OCR aims to interpret typewritten characters.
OCR and ICR are important because they are used in applications such as automatic car number plate recognition, automatic information extraction from hand-written forms or documents, making scanned images of printed text searchable (searchable PDF books) and production line automated testing.
This project aimed to explore the introductory concepts in Intelligent Character Recognition by using an artificial neural network to identify digits hand-written by the author. Moreover, the project aimed to record how the performance of the system varied as a function of the regularization parameter, λ, and to use learning curves to determine whether the system has high bias or high variance. The performance of the system was defined to be the ratio of correctly recognised digits over the total number of digits in the test set.
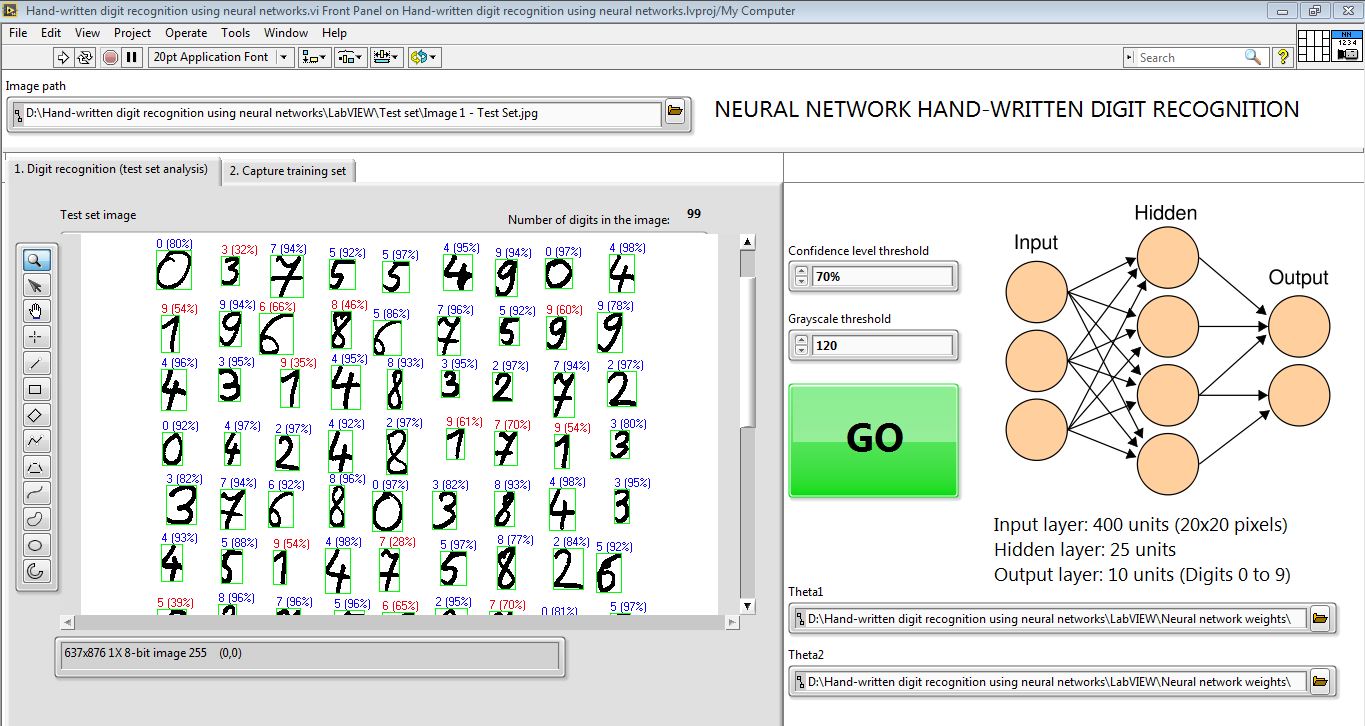
Figure 1: Main application front panel
.JPG)
Figure 2: ANN's predictions and confidence level in each prediction (%)
The Solution
The system’s design and operation is outlined below. The system took around three weeks to build, without including the time taken to study the machine learning concepts.
1. Creating the dataset.
The author hand-wrote 2990 digits: 299 examples for each of the ten possible digits, zero through to nine. The sheets on which the digits were written were then scaned using a regular office scanner. One of the aims of this project was to become familiar with using IMAQ functions and image processing concepts in LabVIEW. Building a new dataset of hand-written digits, rather than using one of the freely available datasets online, provided this opportunity.
The IMAQ palette made it straight-forward and intuitive to perform the image processing and analysis required for this project. Moreover, the NI IMAQ Concepts manual found here was an invaluable resource when learning about image processing and computer vision.
2. Converting images to training examples.
In order for a hand-written digit to become part of the dataset, the LabVIEW VI:
- Filters out anything in the image that is not a digit. The particles with an area of less than 50 pixels, or particles that are touching the border, are rejected.
2. Detects each digit’s bounding rectangle and overlays the bounding rectangles on the front panel image display.
3. The inside of the bounding rectangles become regions of interest (ROIs). Each ROI now encloses one and only one hand-written digit.
4. Each ROI is resized into a 20-by-20 pixel image. As it can be seen in Figure 3 below, the 20x20 pixel image is quite pixelated and loses some of the original digit information. (Having a higher resolution of the individual digit images would increase the system performance but slow down the process of training the ANN, as the ANN’s number of input layer units is equal to the number of pixels of the images (each pixel becomes an input node to the ANN). Currently, training the ANN takes around 10 minutes on a training set of 2990 examples of 20x20 pixel images.)
5. The 20-by-20 pixel images are converted to numeric 2D arrays with 20 rows and 20 columns. The 20x20 2D arrays are flattened into 400x1 vectors. Each such vector contains the information for one hand-written digit.
6. The dataset is built by stacking together all the 400x1 vectors, resulting in a 2D array with 400 columns and m rows, where m is the number of hand-written digits scanned by the LabVIEW VI.
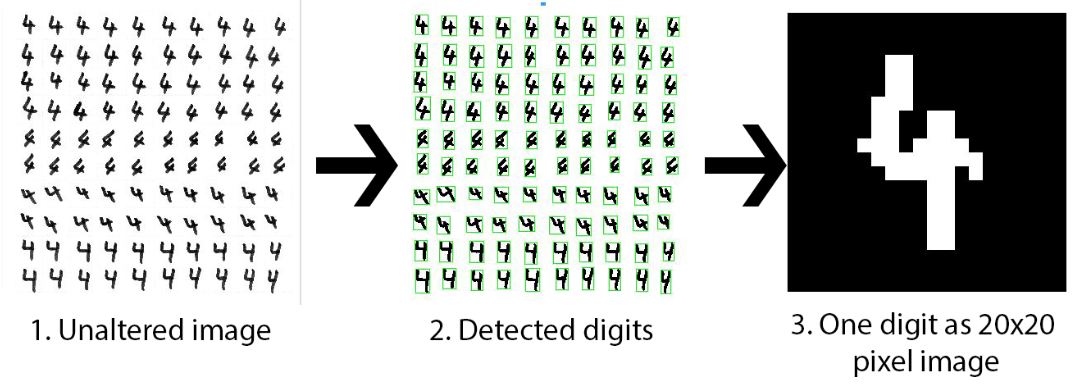
Figure 3: Detecting the digits in the image and resampling each one into a 20x20 pixel image
3. Training the ANN
The dataset is then used to train the artificial neural network. This is done in MATLAB, as the complex program that trains the ANN was inherited from the fourth programming exercise of the aforementioned Machine Learning course and time constraints prohibited the porting of the program through to a Mathscript node. The outputs of this script are two text files containing the Theta 1 and Theta 2 matrices, which are the matrices containing the weights, or parameters, of the ANN.
The ANN’s structure consists of an input layer with 400 units (corresponding to the 20x20 resolution of the input images), an output layer with 10 units (corresponding to the ten possible digits, zero through to nine) and a single hidden layer of 25 units.

Figure 4: Structure of the artificial neural network
4. Test system performance
The text files containing the Theta 1 and Theta 2 matrices are read by LabVIEW and a Mathscript node uses the weights matrices to generate the predictions of the ANN when shown test set images containing hand-written digits. The predictions, alongside the confidence level of the ANN are overlaid on the front panel display, for easy visualization of the system’s ability to recognize digits.
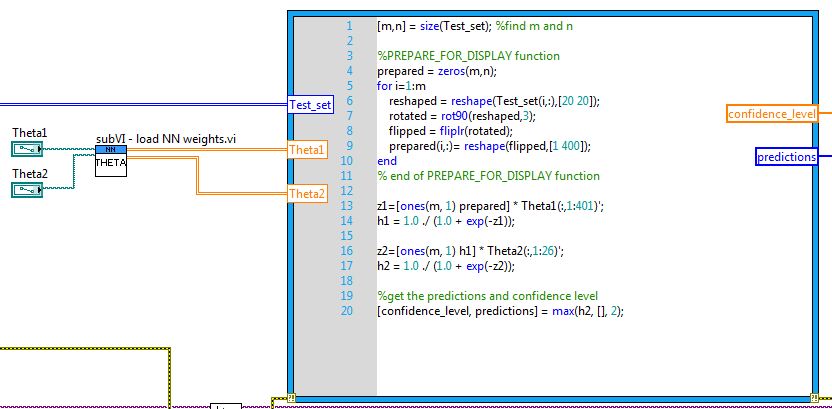
Figure 5: Mathscript node that creates the predictions based on the ANN weights matrices Theta1 and Theta2
The ANN has been shown to correctly identify 85% of the hand-written digits in the test set. The ANN seems to suffer from high bias, also known as under-fitting the data. Therefore, increasing the number of hidden units, from 25 currently, should help reduce the bias and increase the accuracy. However, this was left as a future expansion.
In-depth video description:
Possibilities for improvement and expansion:
- Use grayscale digit images, rather than black and white images (also known as binary images) used at the moment. Using grayscale images would allow the use of the MNIST database of handwritten digits, which contains 70,000 examples. The digits in that dataset were hand-written by numerous people and therefore contain representations of numerous writing styles. Using such a dataset will make the neural network more accurate at recognizing different writing styles.
- Use of a webcam to do real-time digit recognition off a sheet of paper that is placed in front of the webcam
- Vary the neural network structure to optimize performance:
a) Increase the number of hidden layer units, from 25 currently
b) Increase the number of input layer units, from 400 currently
4. Expand to hand-written letter recognition
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Nice work, Petru! Very impressive!!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
This is an amazing project Petru. You have done an amazing job once more!!!!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Attilio,
Would you like to describe what you are trying to do here?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I'm trying to build a program which detects objects using neural network. I'm really new at Labview and ANN so I'm looking for material for understanding how to realise my project. I would be grateful for any kind of suggest.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Attilio,
From your email I understand that you are working on a project that requires you to create a LabVIEW Real-Time (RT) system that uses a neural network (NN) to recognize objects. You would like to know how to create a dataset of images that you can then use to train the NN.
It seems to me that knowledge in the following three areas is required in order to create this project:
1. Knowledge of the LabVIEW environment and familiarity with LabVIEW RT concepts
2. Knowledge of the LabVIEW Vision Development Module (Image Processing and Computer Vision in LabVIEW)
3. Knowlege of machine learning and neural networks
Here are some resources that should help with each topic:
1 and 2. Some excellent introductory videos and tutorials about programming in LabVIEW are found at: https://www.ni.com/getting-started/labview-basics/
However, the best way to learn is from the official National Instruments (NI) manuals, which are very well written and provide exercises that start as being easy and progress towards more complex. These manuals are not free unfortunately, but you can ask your faculty or department - they might have a licence with NI Italy that includes training courses for you. Ask if the faculty has access SPOT (Self-Paced Online Training). SPOT is NI's online training platform which is the second best thing after sitting the courses in person. On SPOT you should find courses on both the basics of LabVIEW (these courses are called Core 1 and Core 2) but also on LabVIEW Real-Time.
For a thorough understanding of Image Processing terms and VIs in the LabVIEW Vision Development Module, I recommend the following excellent "IMAQ Vision Concepts manual": http://www.ni.com/pdf/manuals/322916a.pdf. It is fairly easy to read, but it is packed with useful information.
The Vision Development Module contains VIs that can quickly do object learning and recognition. If you use these high-level VIs there would be no need to develop a NN anymore. This great project shows these powerful VIs in action: https://decibel.ni.com/content/docs/DOC-41700
3. Neural Networks, Machine Learning
The best introductory course in Machine Learning I know of is the one offered on Coursera and taught by professor Andrew Ng: https://www.coursera.org/learn/machine-learning/. Neural Networks are covered in enough depth in weeks 4 and 5, when in the exercise you get to build the hand-written digit recognition system that I based this project on.
Some questions that might help:
1, What camera are you using? What type of card or device are you using to receive the camera images? Is the processing done on that card/device or on a PC?
2. Do you have a block diagram of the system?
3. Do you have access to the LabVIEW Real-Time module and/or the LabVIEW Vision Development Module? Do you have access to NI training?
All the best,
Petru
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Petru,
thanks for your exhaustive answer.
I still don't have a block diagram of the system. The camera which I decided to use for this project the one mounted on my laptop. I used the VDM for some simple color recognition application, but I never used before LabVIEW RT module (so I will start asking my faculty if I can get access to SPOT).
In the beginning Neural Network were a pre-requisites for developing this project, but as long as I saw, I should consider which would be the best solution using only LabVIEW.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Attilio,
I assume that you will try to run the LabVIEW program on your laptop, since the images are captured with the laptop's webcam. Please note that you cannot run LabVIEW Real-Time on any PC or laptop.
This is because in order for a program to execute in Real-Time (a.k.a. deterministically) it has to run on a special hardware that runs a light weight operating system specifically designed for RT operation. These operating systems are called RT OS. For example, you can run a RT application on the NI cRIO, sbRIO or myRIO.
You cannot run an RT application on a Windows PC, as Windows cannot achieve the level of loop period repetability (determinism) to classify it as RT. An RT application is one in which the loop periods are always within a very small tolerance of the loop period you specified. For example, if you set a loop period of 1 ms, the actual loop periods might range between 0.995 ms and 1.005 ms in an RT OS. On Windows, the loop period might range between 0.9 ms and 1.1 ms (or more variance) from iteration to iteration.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hello !
I wish to run this program on my laptop, could you tell me a bit more about the software requirements ? I have Windows 10 on my system. Also does the MathScript module come with LabView 2014 or should it be purchased separately ? Did you use the 64 bit or the 32 bit versions ? Also please tell me which version of MatLab should I use and how I can train the ANN to understand my handwriting ?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I was making my own license plate detection and was using your video (Hand-writt
Or is it possible to zip the video file and mail it to me?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hello dear. Please explain to me how to create Theta1.txt, Theta2.txt file. help me thank you.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Focus on client connections: Keep up major areas of strength for with your clients by conveying top notch benefits and giving incredible client assistance. Grasp their necessities, convey successfully, and surpass their assumptions to fabricate trust and support rehash business and references. Piedmont business Capital
