- Document History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Version 3 of the Current Value Table (CVT) introduced some significant changes in the library. This document provides a summary of these changes as well as some comparative performance benchmarks.
Changes in CVT v3
- Addition of new data types (all scalar types).
- The API has been changed to a polymorphic implementation to allow easier selection of the correct data type.
- Tags can be added or removed from groups which can be referenced as a single item.
- Numerous tags of a single data type can be referenced in a set, allowing for much faster data access.
- Tag management VIs have been rewritten to provide large performance gains.
- API calls have been modified to implement a smarter lookup process.
- Utility VIs allow users to save the entire CVT to an XML file.
- A compatibility layer is included to ensure compatibility with tools like the CIE and CCC which rely on version 2 of the CVT API.
- Runtime performance has been improved across the board. See below for details.
- Tags can be added at any point during runtime.
Implementation of CVT v3
The Current Value Table is implemented in a two layer hierarchy consisting of core VIs and API VIs. The core contains all of the functionality of the CVT, including the data storage mechanism and additional service functions. The API VIs provide access to the CVT functionality in a simple interface. There are a few sets of API functions that provide slightly different access to the CVT and vary in flexibility and performance, as well as easy-of-use.

The core data structure consists of two VIs which support tag management for the entire CVT, and an additional data storage VI for each data type supported.
The Memory Block polymorphic function stores all data for the system, and consists of a single VI for every data type supported. This functional global variable allows you to clear memory, read or write a single value in memory, and read or write a set of values in a single call.
The Tag List and Group List functions store all information necessary for the access and management of that data. The tag list stores the name, type, description, and memory location of each tag. The group list stores information about any groups formed in the table. Both of these functions store information by name in the form of variant attributes. Variant attribute "get" and "set" functions provide an extremely fast lookup which is superior to a linear array search for data sets larger than approximately 40 tags.
API in CVT v3
The CVT contains a number of API function sets to provide different interfaces that can be chosen according to the needs of an individual application. The basic API provides simple write and read functionality. The additional APIs provide a higher performance interface to the CVT, but place some restrictions on the application when using the CVT. All three APIs share the same common core VIs and can be used in conjunction with one another, so you can choose the appropriate function for each individual access to the CVT.
Create Tags
Before the CVT can be used to store and retrieve data it needs to be initialized. Initialization allocates memory for contained tags, forms any groups specified, and stores any user-defined metadata. The initialization of the CVT is defined using a cluster array that contains the attributes of all variables used by an application. Version 3 of the CVT introduces a new cluster which allows the system to handle new features like groups. This cluster is incompatible with the cluster used in prior versions of the library, but a conversion VI is provided for backwards compatibility. This cluster can be created as a constant on the diagram or loaded from a file. Version 3 of the CVT also adds the ability to create new tags as needed during runtime, without overwriting existing tags. The initialize VI allows the user to select whether or not they wish to clear the CVT.
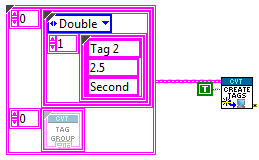
Standard API
The standard API contains functions to read and write data items in the CVT using the variable name as an identifier. Using the basic API the variable name can be a static string or can be created at runtime using the LabVIEW string functions. In the API call, the variable name is used to lookup the index of the variable and then the value is accessed in the using the index. To improve performance, version 3 of the CVT only performs the lookup on the first call, if the lookup previously failed, or if the tag name input changed from the previous iteration. This API uses polymorphic VIs to switch between data types. For writes, this data type is selected automatically based on the wire type. Reads can be selected by providing a default value or by manually selecting a type. The appearance of the VI will change based on the instance selected.
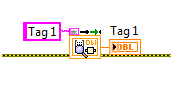
Static API
The Static API is very similar to the standard API. However it requires that you use a static name (constant string) in your application when accessing a variable. This restriction allows each instance of the Static API to only perform the variable index lookup operation once on the first call to each instance. It then buffers the index for subsequent accesses providing a significant performance advantage when repeatedly reading or writing the same variable in the CVT. Version 3 of the CVT also allows the static API to perform the lookup again if an error occurred, rather than relying on the "first call?" primitive. This API can be distinguished by the inclusion of a small glyph which indicates that the lookup value is stored internally.
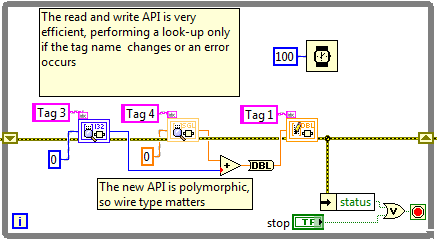
Advanced API
The Advanced API provides even better performance with the tradeoff of requiring the application-level code to perform the lookup. Using the Advanced API you use two VIs to access a value in the CVT. The first VI is used to retrieve the index and type of a variable in the CVT. This step is only performed once for each variable used. Then the index is used to access the variable value. This provides the thinnest possible API to repeatedly access the same value in the CVT.
For sets of tags which share the same data type, the Advanced API can be used to further boost performance by eliminating the sub-VI overhead of each lookup in memory. Performance will vary, but a rule of thumb is to use set of indices any time you wish to access three or more tags of the same type. Because tag names themselves are untyped, the Advanced API look-up function returns the tag type along with the references in order to provide a type confirmation to the application code.
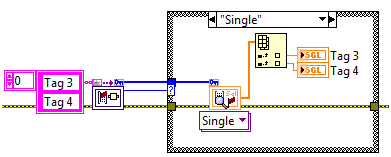
Group API
Sometimes, it can be beneficial to attach a name to a set of tags of varying data types rather than referencing each tag individually. Version 3 of the CVT adds a group API which allows the user to read or write a set of tags simultaneously. One method for forming a group is to create the group during initialization.
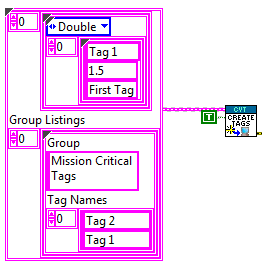
Groups can also be formed at run-time. Once a group has been formed, it can be accessed by the group name rather than the individual tags. Similarly to the Basic API, a look-up will only be performed if the group name changes or if an error occurs. Users cannot modify an already formed group, but groups can be deleted and reformed using this API. Care should be taken to ensure that tags are looked up after a group has been deleted or reformed. Once the lookup has been performed, the group can be read as a whole, in the order specified.
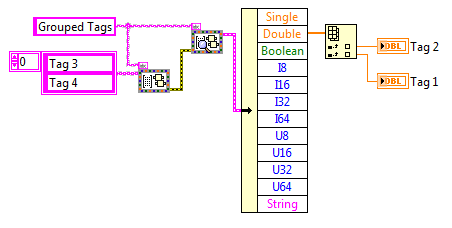
Utilities Functions
In addition to the VIs that access the stored variable values, the CVT also provides utility VIs to access additional properties or attributes of each variable or group.
Read Tag Description.vi provides a tool for retrieving the stored description of a tag.
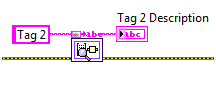
List Grouped Tags.vi and List Grouped Tags By Type.vi provide a utility for retrieving the members of a group. The first function returns the full list as entered. The second returns a list which is organized by type, with a type descriptor for each set.
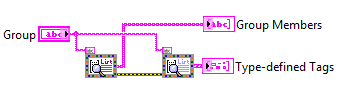
Finally, Save CVT to Disk.vi and Save Grouped Tags to Disk.vi provide tools for storing the currently loaded CVT data to disk. Save CVT to disk will initiate a lookup of every tag in the system on first call, and will use that information to perform an extremely efficient index read on the data on subsequent calls. Save Grouped Tags to Disk will perform a lookup in the same fashion as the Basic API. Both functions will then pack the data into an XML file and save it in the location specified.
Performance of the CVT v3
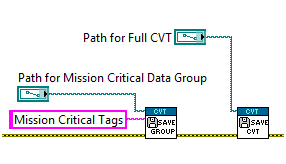
A series of performance tests were generated and run using the Unit Test Framework in order to compare the performance of any change to the performance of the CVT v2.0.1. The results of these tests, when run on a Quad-core laptop, are shown below. All tests consist of 1000 reads. For individual access APIs, a single value is read. For bulk access APIs, 1000 values are read. The only exception is for the 4x Parallel Static Reads and Writes tests shown in Figure A, where 400,000 accesses are performed across 4 parallel loops.

Figure A: Performance results for the higher-speed CVT APIs. This demonstrates the improvements offerred by the modified memory function. Note: Since CVT 2.0.1 can only read items by index, I have used that as the result for Reference Read, Reference Write, Group Read, and Group Write.
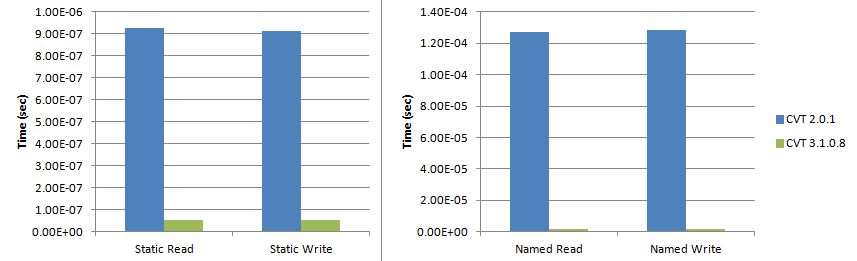
Figure B: Performance results for static access and for named access. These tests demonstrate the improvements made to the tag management functions. Even across 1000 reads, the single lookup performed by the static reads function is enough to slow the entire test down for CVT 2.0.1, as compared to the more direct comparison offered through the tests in Figure A. The Named Read and Write tests use the basic API to read 1000 tags in sequence, performing the lookup every time.
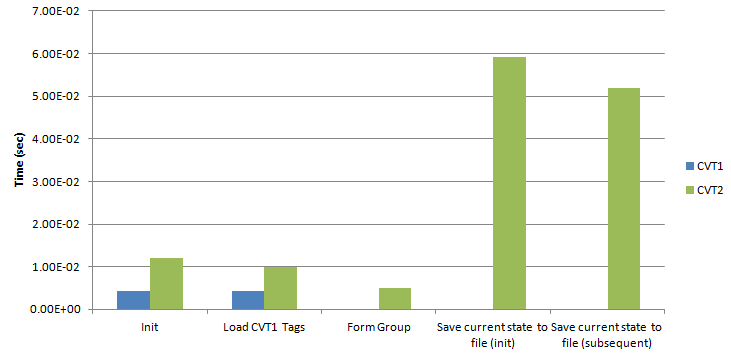
Figure C: Performance results for tag management functions. Because run-time performance was the goal, some slight sacrafices were made to init-time performance. This test also demonstrates the time taken to save 2000 tags to disk and to form a group of 2000 tags. Note: For CVT 2.0.1, the "Load CVT1 Tags" test is equivalent to the "Init" test. Init uses the native tag type for each API. As such, the "Load CVT1 Tags" does not include groups, but does include the code required to convert from CVT1 tags to CVT3 tags.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Someone I showed this to privately was reading this from Eli's blog and wondered about the use of a similar mechanism for the CVT. I figured it might be nice to comment this on publicly.
The short version of my response is that we do use that, but it's performance is too slow to be used for everything.
To clarify a little bit (and there is more information in that link), variants can store, within their data structure, a set of attributes. These attributes apparently use a C++ std::map structure for storage, meaning that you can get from a lookup input (like a string), to the data you desire with better performance, on average, than through a linear search. At one point I did a benchmark comparing a linear search for the middle element (that is, the average lookup time) and compared it to the average lookup time for a variant attribute. If I recall correctly, variant attributes began having better performance after ~50 elements were added to the array. The big problem is that, for our use cases, we also want to store data with that string name. This has a tendancy to make the code unpleasant.
As far as using it for the current value table, as it is written, we do! It is used to perform the conversion from tag name to memory location. That is, the variant attribute map stores a cluster of metadata about a given tag, like its description, data type, and index. The problem here is that the map has a reliably fast lookup time, even for large sets, but that lookup time is only fast relative to a linear search. Indexing an element from an array is ridiculously quick, and quick is what we need most of all on embedded targets with large channel counts.
Now, to actual numbers from the benchmarks I provided. Figure B shows 'named read' access, which includes both the lookup time (string->memory location) and the read time (memory location->data). However, Figure A's index read time shows us that the raw read time (memory location->data) is on the order of 40-60 ns. While not perfect, this should give us an order of magnitude guess as to how long the lookup time is. CVT 2.x used a linear search, so searching for 1000 elements from a 1000 element array gave us an average lookup time of 0.127 ms - 50 ns = 0.127 ms. CVT 3.x uses a variant attribute search and had an average lookup time of 1830 ns - 50 ns = 1780 ns. The benefits of using the variant-based map search rather than the array-based linear search are apparent, but I think it is clear where the lookup performance pales in comparison to the actual reads, which is why the provided implementation was chosen.
This performance is also one of the reasons that the CVT is still scalar-only. Besides the challenges of storing an array in memory using the current implementation (we would basically need a whole new memory structure, or else suffer in performance), the performance of the variant lookup or a data value reference (DVR) is really going to be superior to the implementation developed here. It is still on my list as a possible future addition (to at least create similar wrapper/lookup/grouping functionality as in the CVT), but for now the available tools are pretty good.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Is there an ETA an the official release?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
At this point the code is fairly well tested but I don't have a timeline for an "official" release. I will certainly post back here if I have one. To clarify, however, even if we have an "official" release it will still operate under the same sample code license, and will not be considered an official NI product. The purpose of releases like this is to give users a solid starting point for development, not to provide a full-featured solution.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
<Edited, see below>
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Code has been reviewed by my group internally and we made some changes for 3.2.0.13 above, but I intend for this to be the initial non-beta release.
If upgrading to 3.2.0.13, the default data type changed from single to double to match labview better. Please be very careful about situations where you performed reads using the beta code.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I noticed in the lower level Memory Block VIs, feedback nodes are implemented as opposed to shift registers. I recalled an old post discussing that FN are slightly slower than SR: http://forums.ni.com/t5/LabVIEW/Execution-speed-feedback-node-vs-shift-register/m-p/295536/highlight... . This was benchmarked in later versions of LV, so not sure if updates in more recent versions of LV have turned the tide and the use of FN is now recommended for performance over SR?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hey Quintin,
I chose feedback nodes for a few reasons:
- I absolutely hate the normal while loop+sr implementation of functional globals. I know that is the 'way' you do it, but it just doesn't make any sense to me and I think if we stopped teaching it in core training all new users would feel the same way. Feedback nodes feel like a more explicit "here is memory" implementation so I chose that.
- I also saw posts like that and the end result is that these things shift over time. One may be faster in 2010 and slower in 2011, as the compiler team implements optimizations in the background. During development I did some of my own tests and never saw a really consistent difference between the two. Any difference I did see was minor, so I went with the implementation I liked better
Hope this helps  .
.
Thanks,
Daniel
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
The 'shift over time' answer was exactly what I was wondering about. Thanks!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi,
I tried to use CVT Data Logger (CDL) with the CVT v3 and the "CDL Read CVT Tags.vi" was broken. First I thought CDL isn't compatible with the new CVT v3 but it actually is. It seems that the execution mode of the "CDL Read CVT Tags.vi" is set to subroutine which creates an error that "Subroutine priority VI cannot call a non-subroutine priority subVI". If I change it to normal priority, it isn't broken anymore and it can be run. I tried it out with the "CDL Example_Basic.vi" after the execution mode change and it seems to work correctly.
Are you planning to update the CDL to work better with the CVT v3? I guess there could be some performance improvements in the CDL with the new CVT v3 functions as you can read multiple indexes at once.
Anyway, good job updating the CVT!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hey Matti,
Thanks for that feedback. We actually just put together a few bug fixes and packaged them last week, so we should have something available soon on the tools network (look for NI Current Value Table). I believe this fixes that subroutine problem as well.
On the topic of updates we've been making changes to different components as we have time, and we haven't had much time. CVT Client Communication (CCC) was our highest priority and I think that is in work, but CDL was further down the list. However I did have a few personal goals for that update, which I hope to make happen. For example, if you look inside the CDL you'll see that the original author used queues to buffer data for larger writes. Recently I've discovered that the TDMS advanced API can write single-point data extremely efficiently without having to do the buffering ourselves. This should improve performance and vastly improve readability of the code...but again, need to find the time to actually get it done .
Thanks,
Daniel
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Great! Looking forward for the CVT release. CCC update sounds good also and try to find some time to update the CDL.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Matti,
The updated version of the CVT Client Communication (CCC) library is now available in the LabVIEW Tools Network repository. You can download it directly from VI Package Manager. I do not have any updates on the CDL yet.
-Chris
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
CVT v3 is great, but I'd like to request that the API be expanded to provide a better interface for creating tags dynamically. Right now, it seems you have to create an instance of the "File Format.ctl" clutser and figure out which values to provide for each tag you want to create. It's not intuitive how to specify that value as a string, either. I'd like to see a simple polymorphic VI for creating a new tag (or a bunch of new tags of the same type).
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hey Staab. Thanks for the feedback . That feature is actually one I recently thought of while we were in the process of putting out the last release a few weeks ago. There is already an internal function ("data to ascii" or something along those lines) which handles creating the "value" string, this but it would definitely be nice to wrap up in a higher level function like "form tag" or something. I'll think about it some more and if we find some time in the next few months I'll try to put something together.
Thanks,
Daniel
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thanks for the updates Daniel and Chris!
Just noticed a need for improvement in the CDL. It would be nice to be able to set the sample rate to be lower than 1Hz in some cases. For example on some long term temperature measurement cases we sample every 15 minutes and it isn't possible (without modifying the original CDL API) to set the sample rate to that value in the current CDL.
Hope you could take this into account when you have time to work with the CDL update.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
That is definitely something I've noticed as well. My idea was to make the CDL into an API and then distribute the engine--which is what the CDL currently is--as a sample library or something...but that is still a ways off. Thanks for the feedback, though.
-Daniel
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi Chris and Daniel,
Any news on the CDL development? I'm currently working with a project which could benefit from newer version of CDL.
-Matti
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hey Matti,
Unfortunately I ran into some issues with the API I wanted to use (advanced TDMS API) related to performance. My initial assessment was correct--it is much faster than the current CDL--but it turned out that the speed was only on 99% of iterations. Every few seconds (depending on the data rate of course), the flush to disk would have to be performed and that API seems to perform it synchronously. Since my goal was to greatly simplify the CDL by changing it from a process to an API, this poses some issues that I have yet to resolve. Its definitely something we're working on, but unfortunately I don't have a solution yet.
That having been said, making a solid, reusable, well documented API is a lot different from writing some code to accomplish the task--so I quickly drew something up and posted it here:
https://decibel.ni.com/content/docs/DOC-35679
At its core, I copied the code from what will become the new API, but it doesn't handle many of the use patterns I want to go after with the new code. Hopefully it helps.
Thanks,
Daniel
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
An alpha release of the CDL was just uploaded here:
https://decibel.ni.com/content/docs/DOC-41855
Its probably not too helpful just yet as it doesn't support arrays, but now that we've released the other associated components I was able to publicly release that package. For anyone looking, the difference between the old CDL and this release is that (a) we added support for new types (b) it uses a more dataflow-oriented tag bus implementation and (c) we've separated the api (copy data from cvt to file) and the process (which is where you can set the loop rate, for example).
Its still rough, and it doesn't support everything (although we would like that, its tough to do at high performance -- may need to use two separate files), but its at least available. If you give it a go, please do provide feedback.
Thanks,
Daniel
