ni.com is currently undergoing scheduled maintenance.
Some services may be unavailable at this time. Please contact us for help or try again later.
- Document History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
LabVIEW Unicode Programming Tools
Following are my observations and findings while using Unicode in a LabVIEW UI application. The purpose of using Unicode in this application is to localize the UI on the fly in any language without having to change the Computer locale. The application provides a settings page which allows the user to select the language of the UI. Based on this setting all UI components (controls and indicators) are localized into the selected language. The resource strings for all controls/indicators and languages are read from a text file containing Unicode strings.
Disclaimer:
LabVIEW for Windows has limited support for Unicode strings in the front panel controls and indicators. This is not an offically supported feature, meaning that it is not as fully tested as other released parts of the development and run-time environment. In addition this feature is not covered under standard product support and parts of this feature may change in future releases of LabVIEW, i.e. any code developed on this feature may require changes when upgrading to a newer version of LabVIEW. If you have any feedback or questions about using Unicode in LabVIEW post them as comments on this document or in the Developer Zone discussion forums.
The code posted as part of this document has been developed and tested in LabVIEW 2009 running on Windows XP SP3 (English). The VIs are saved back to LabVIEW 8.6. Earlier versions of LabVIEW did not include all of this Unicode support and it is suggested that you upgrade to LabVIEW 8.6 or later if you want to use Unicode in your application development.
This code has not been tested with other operating systems and I assume it will not work on non-Windows OSs, though I expect it should work in Windows Vista and Windows 7.
What is Unicode?
The answer to this question could cover many pages by itself so I will not attempt to provide a detailed or comprehensive explanation of the Unicode standard and its different character encodings. Please consult other online sources for this information. It will be helpful to be familiar with what Unicode is before proceeding with the rest of this document.
http://en.wikipedia.org/wiki/Unicode
http://en.wikipedia.org/wiki/UCS-2
Unicode and LabVIEW
Unicode is not officially supported by the LabVIEW environment, but there is basic support of Unicode available as described in this document. Unicode can support a wide range of characters from many different languages in the same application.
Windows XP (Vista, 7) is fundamentally built on Unicode and uses Unicode strings internally, but it also supports non-Unicode applications. By default LabVIEW on Windows (English) does not use Unicode strings, but rather uses Multibyte Character Strings (MBCS). The interpretation of MBCS is based on the current code page selected in the operating system. The current code page is set using the regional settings of the OS and determines how the bytes in the strings are rendered into characters on the screen. The most common code page is 1252 used by English Windows as well as several other Western languages and comprises the commonly known extended ASCII character set.
http://en.wikipedia.org/wiki/Windows-1252
When the regional settings in Windows are changed the OS may switch to a different code page for rendering strings. For example if you switch to Japanese, code page 932 will be used. Using different code pages allows LabVIEW to have localized versions of the development environment. All code pages include support for the basic ASCII characters used in the English language, as well as a local set of characters. Therefore if you have code page 932 selected, the operating system can still render ASCII characters as well as Japanese.
Using Unicode instead of MBCS, an application can render characters from many different alphabets or scripts without switching code pages/regional settings. In fact all of the language scripts supported in the legacy code pages are included in Unicode and Unicode keeps being expanded with more characters every release. Because Unicode does support more than 65535 characters nowadays, a concept of planes was introduced in conjunction with surrogate pairs. Most of the characters covered by the code pages are included in Plane 0 of the Unicode standard and fit on a 2-byte representation, but more complex characters for mathematics or ancient scripts have been located on higher planes and thus use surrogate pairs as they code point value (and are thus coded on 4 bytes).
http://en.wikipedia.org/wiki/Mapping_of_Unicode_character_planes
A common encoding form of the Unicode character set is UTF-16. UTF-16, depending on byte order is called Big Endian or Little Endian. Unicode in LabVIEW is handled as little endian, also called UTF-16LE. This is important to know when looking at the hexadecimal representation of strings or working with Unicode text files.
| Character | ASCII (hex) | UTF-16 (hex) | UTF-16LE (hex) - LabVIEW |
|---|---|---|---|
| z | 7A | 00 7A | 7A 00 |
| 水 | n/a | 6C 34 | 34 6C |
| Ѳ | n/a | 04 72 | 72 04 |
Table 1: Example of a few characters in ASCII and Unicode
When writing Unicode to a plain text file you commonly prepend a Byte Order Mark (BOM) as the first two characters of the file. The BOM indicates to the file reader that the file contians Unicode text and if the byte order is big-endian or little-endian. The BOM for big-endian is 0xFE FF. The BOM for little-endian including LabVIEW is 0xFF FE. Windows Notepad and Wordpad can detect a Unicode file using the BOM and display their contents correctly.
LabVIEW for Touchpanel on Windows CE
LabVIEW for Touchpanel on Windows CE supports multi-byte character sets (MBCS) — specifically double-byte character sets (DBCS). Under this scheme, a character can be either one or two bytes wide. If it is two bytes wide, its first byte is a special "lead byte," chosen from a particular range depending on which code page is in use. Taken together, the lead and "trail bytes" specify a unique character encoding.” (http://msdn.microsoft.com/en-us/library/ey142t48(VS.80).aspx" target="_blank">http://msdn.microsoft.com/en-us/library/ey142t48(VS.80).aspx<SPAN>) A code page only contains the characters from one particular language such as Korean. Therefore MBCS can only support ASCII and one other set of language characters at a time and you need to select the specific code page for non-ASCII characters to be used in your application. To do that, look for the "language for non-Unicode programs" in the Windows Control Panel.
Using Unicode in LabVIEW
Common Use Cases
A list of common uses of Unicode in an application developed using LabVIEW includes:
Non Unicode
All strings in the application used for display, user input, file I/O network communication (e.g. TCP/IP) are ASCII strings. This is the most common use of LabVIEW and does not require the use or consideration of Unicode.
Non-Unicode = Extension of ASCII based on system code page
ASCII technically only defines a 7-bit value and can accordingly represent 128 different characters including control characters such as newline (0x0A) and carriage return (0x0D). However ASCII characters in most applications including LabVIEW are stored as 8-bit values which can represent 256 different characters. The additional 128 characters in this extended ASCII range are defined by the operating system code page aka "Language for non-Unicode Programs". For example, on a Western system, Windows defaults to the character set defined by the Windows-1252 code page. Windows-1252 is an extension of another commonly used encoding called ISO-8859-1.
http://en.wikipedia.org/wiki/ASCII
http://en.wikipedia.org/wiki/ISO-8859-1
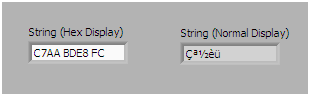
Figure 1: LabVIEW ASCII string in Hex and normal display showing extended ASCII characters
Unicode
• The application reads Unicode data from a file or other source and displays it using a non-Unicode encoding (ASCII based) on the user interface. In this use case it is assumed the Unicode characters are limited to the subset supported by extended ASCII.
• The application reads Unicode data from a file or other source and displays it as Unicode characters on the user interface.
• The application internally uses characters encoded in a non-Unicode way, including input from the UI by the user, but needs to write data to a file or other destination in Unicode.
• The application uses Unicode strings internally including input from the UI and writes Unicode data to a file or other destination.
LabVIEW Configuration for Unicode
To use Unicode in LabVIEW you must enable Unicode support by adding the following setting in the LabVIEW.ini file. After making this change you must restart the development environment.
[LabVIEW]
UseUnicode=True
LabVIEW Controls and Indicator Properties
The LabVIEW string controls and indicators have two private properties related to entering and displaying Non-Unicode (extended ASCII) or Unicode characters. These properties are not exposed through the regular property node; access to these properties is provided through subVIs as part of the examples included with this document.
• Force Unicode Text
• InterpretAsUnicode
Force Unicode Text is a property which can be enabled and disabled on the string control using the context menu of the control or indicators.
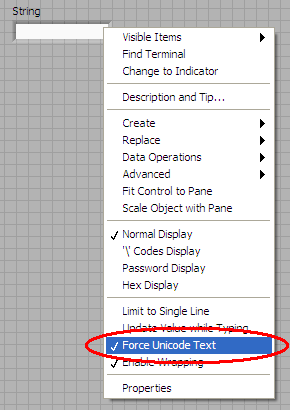
Figure 2: Setting the Force Unicode Text property on a string control
The Force Unicode Text property affects how text entered from the keyboard is converted to a string (byte stream) in the diagram. If text is passed from an ASCII keyboard and this property is turned on, then the text is automatically converted to the Unicode equivalent of the ASCII characters. Typically this means that every single byte character is converted to the two byte Unicode equivalent.
InterpretAsUnicode is a property which can be enabled on text elements of different UI controls and indicators, such as the text of a string control/indicator, the caption of a control/indicator, the Boolean text of a Boolean control/indicator, etc. This property controls whether a string value passed to the text element is interpreted as an ASCII or Unicode string. SubVIs provided with the example in this document allow you to pass strings to different UI elements and select whether you are passing an ASCII or Unicode string.
Note: The state of the InterpretAsUnicode property of a string element may be changed dynamically if text is pasted or entered into the text element by the user. The display mode (InterpretAsUnicode) of the text element will automatically adapt to Unicode or ASCII depending on the type of text entered into the control.
• If you paste a Unicode string into a text element the InterpretAsUnicode property is turned on.
• If you paste a regular ASCII string into a text element the InterpretAsUnicode property is turned off.
For example, if the display mode of a string control is Unicode (InterpretAsUnicode property on) and text is entered from an ASCII keyboard, the display mode will be switched to ASCII and the current value of the string control will be interpreted and displayed as ASCII characters. This can cause issues if the Force Unicode Text property is enabled for a string control. Entering regular ASCII text will cause the string control to interpret all data as ASCII, however the Force Unicode Text property will automatically convert the new characters entered in the control input to Unicode data. These two conditions combined will cause ASCII text to have a ‘space’ between each letter entered. These spaces are actually the extra Null byte, which are the second byte of each of the ASCII characters converted to Unicode. To resolve this issue you must detect the keyboard input and set the Text.InterpretAsUnicode property of the string control to True to properly display all text as Unicode. This is shown in the examples.
Labels and Captions
When localizing the name of a control or indicator on the user interface you should always use the caption of the control instead of the label. The label is part of the code of the VI (similar to a variable name) and should not be changed. The caption should be displayed instead of the label and can be changed at run-time using the VIs provided.
Listbox, Multicolumn Listbox and Table
The Listbox, Multicolumn Listbox and Table controls have different behavior in terms of processing Unicode strings from the rest of the text elements described previously. These controls so not use the InterpretAsUnicode property. Instead they look for a BOM (Byte Order Mark) on any strings passed to them. If a string passed to these controls starts with a BOM (either 0xFFFE or 0xFEFF) then the string will be handled as Unicode. This allows you to mix both Unicode and ASCII strings in the same control. The examples include subVIs to pass strings to these controls and mark them as Unicode using the BOM.
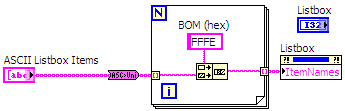
Figure 3: Adding the BOM to Unicode strings to update a listbox
Unicode Fonts
In order to display Unicode strings on your user interface the fonts you are using must have the necessary support for all the characters you are using. If you are using an extensive set of characters from languages using non-latin characters you should verify that your selected fonts have the necessary character support.
Two specific fonts commonly available on Windows that include most Unicode characters are Arial Unicode MS and Lucida Sans Unicode.
Programming Unicode in LabVIEW
Converting ASCII Strings to Unicode
Included in the examples are two very simple VIs to convert an ASCII (MBCS) strings to Unicode and vice versa. These VIs use functions provided by Windows to detect the current code page used for the MBCS and handle the conversion.
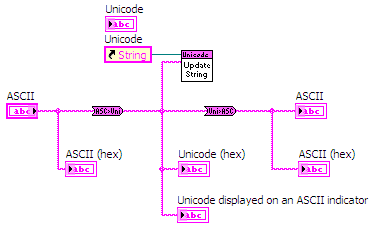
Figure 4: Converting between ASCII and Unicode strings in LabVIEW
The conversion VIs are polymorphic and can handle scalar strings as well as 1D and 2D string arrays.
Displaying Unicode Strings on Controls and Indicators
The attached project includes a number of examples showing how to display Unicode strings on different UI controls and indicators. For each of these control types subVIs are included to pass strings to the control and their caption and specify whether the string should be treated as Unicode or not. The following UI controls and indicators are supported with specific VIs:
- Caption of any control or indicator
- String
- 1D String Array
- 2D String Array
- Boolean
- Ring
- Listbox
- Multicolumn Listbox
- Table
Using control properties you can also access these controls inside of other data structures such as a cluster.

Figure 5: Converting an ASCII string to Unicode and display it on a string indicator, 1D string array and 2D string array
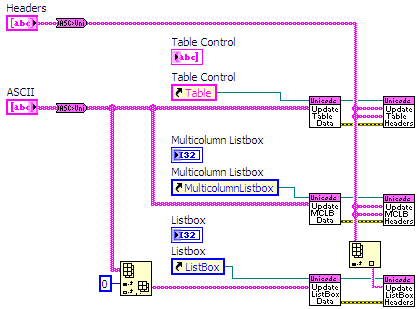
Figure 6: Converting an ASCII string array to Unicode and display it on a Listbox, Multicolumn Listbox and Table
Reading Unicode from a String Control
In order to read Unicode strings from a front panel string control there are a number of settings and that need to be made:
1. Enable the Force Unicode Text property of the string control from its context (right-click) menu.
2. Enable the Update Value while Typing property of the string control from its context menu.
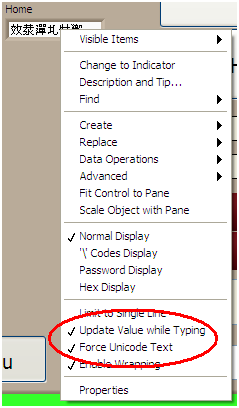
Figure 7: Enable the Force Unicode Text and Update Value while Typing properties
3. Add an event case to the Event Structure for the Value Change event of the string control. In the event case wire the control reference and new value from the event to the Tool_Unicode Update String VI as shown in the following diagram. This will update the string control as the user is typing to keep the InterpretAsUnicode property set to Unicode, while entering ASCII characters.
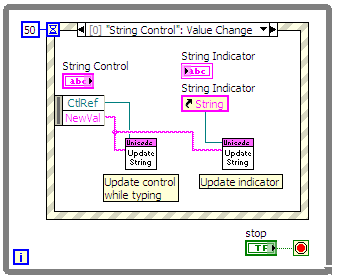
Figure 8: Event Handler for the Value Changed event of the string control
Reading and Writing Unicode Strings to Text File
When reading and writing text files it is important to know if the contents of the file is ASCII or Unicode. The Read from Text File function in LabVIEW does not know whether the contents of the file is ASCII or Unicode. Therefore you need to check to see if the file contains a BOM (Byte Order Mark) at the beginning of the data read from the file and then process the data accordingly.
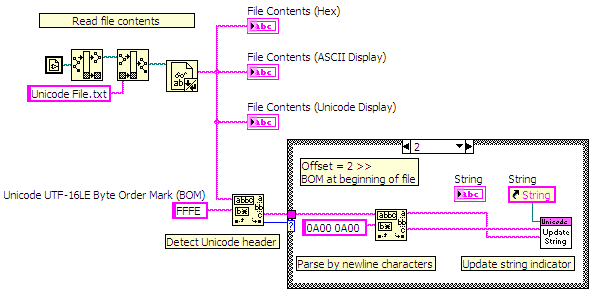
Figure 9: Read a Unicode text file and process
To write Unicode text to a file, convert all your strings to Unicode and then prepend the BOM before writing the final string to a file using the Write to Text File function.
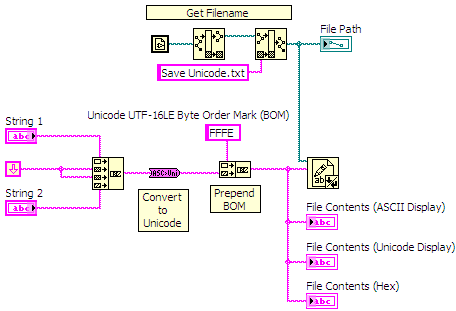
Figure 10: Write Unicode text to a file
Release Notes
June 2014 - Added VI package of the Unicode tools. v 2.0.0.4 Includes wrappers for built-in functions for converting between LV Text and UTF-8. Function palette moved to Addons palette.
February 2019 - Updated VI package to include minor bug fix that occurs in Windows 10 and LabVIEW 64-bit. Latest version is 2.0.1.5. The VIP will also be added to the LabVIEW Tools Network VIPM repository.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
A few comments on Unicode have begun here (of all places...). I am a big proponent of Unicode in LabVIEW, and using it the past year and a half has been both interesting and rewarding.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Perhaps this document will be very useful for me to develop multilingual application. But I have some questions here. I have a project in which I have to use Korean language. You know this is a language which includes unicode characters. For example I am using lots of xy graph in my project. I have to change x axis and y axis name with korean words. But when I assign 한국어/조선말 word to x axis name, it doesn't appear like that. You have written a function which can update captions but not xy graph axis names. I can't update that names. I would like to apply same solution to this names but you have made "update caption vi" password protected. I understand but I really need what that vis include. This vi is very critical for me to understand how to update x and y axis name. You also made other critical vis password protected. For example updating string, boolean text vis are password protected too. Please let me know how to update any of my control's captions, boolean text, x and y axis names and etc. I really need to know that. Please help me.
I didn't find your email address. I am very sorry for writing my problem here.
mehmetned6@hotmail.com
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I have added a VI to the download file for updating the X axis and Y axis label of any of the Chart and Graph indicators in LabVIEW.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
How can i change the TabCaption of the Tab Control?
CLA
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
If you meant the caption of the whole tab control, you can use Tool_Unicode Update Caption.vi to make this change.
If you are asking about the name of each individual tab in the tab control, then you can not change it programmatically. This is because the name of the tab is part of the programming logic and can not be changed at run-time. For example, if you wire the tab control terminal to a case structure in your diagram, the case names take on the names of the individual tabs, and these can't be changed at run-time. The tabs do not have a caption separate from their logical names, like the control does as a whole.
To solve this problem you can overlay a classic string indicator with transparent background over each tab and update its value for your localized names. You'll need to make the color of the strings in the tab the same as the background so that the user doesn't see them. You also need to add code to detect mouse clicks on the overlay strings to change the active page of the tab control when the user clicks on the tab while the VI is running.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Dear Christian,
Here i send the example vi what i am facing problem
in changing the TabCaption in different language's for your reference.
Please check the Vi and replay me as soon as possible.
CLA
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
siva,
I don't see any example attached to your comment. I will add an example to the document above showing a solution to using and updating a tab control. The example uses a string indicator and transparent button overlaid on each tab.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I have uploaded some basic VIs to do the conversion between various encodings, UTF-8, UTF-16, UTF16LE.
அன்புடன்
தமிழ் நேரம்
முதல் இந்திய ஆய்வுமெகபொப சிற்பி
சோதனைநிறுத்தம் சிற்பி
மற்ற சான்றிதழ்கள்
யாதும் ஊரே! யாவரும் கேளிர்!!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I have added a Utility VI to read and write Unicode text files (similar functionality of the Notepad application in Windows).
அன்புடன்
தமிழ் நேரம்
முதல் இந்திய ஆய்வுமெகபொப சிற்பி
சோதனைநிறுத்தம் சிற்பி
மற்ற சான்றிதழ்கள்
யாதும் ஊரே! யாவரும் கேளிர்!!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thank you for these additional utilities, Anish.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Does the "Export String" Feature of LabVIEW support unicode text? I want to use it to localize VIs and i have problems importing unicode txt files.
Greets
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
The Export/Import Strings feature in LabVIEW does not support Unicode. One option you can consider is the LTK LabVIEW Localization Toolkit from SEA.
https://www.ni.com/en-us/shop/product/localization-toolkit-for-labview.html
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I already knew about the LTK, but thanks anyway. My reason for asking is, that i am currently writing a Thesis on possibilities to change languages in labview. I had much succes using the export/import-strings method, sadly the files Labview creates on my machine running german Windows XP and english Labview only support about 200 characters (my guess: Windows-1252 character set is beeing used). I wonder if there is any way around this limitation.
greetings
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Using the VI server functions in LabVIEW (property nodes for VIs, controls, etc.) you can build your own Import/Export Strings functionality which could support Unicode for any parts of LabVIEW that does support Unicode.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
First of all: Thanks a lot for that unicode option!
I'm now working a while with it and found some small problems. One of them is still Unicode and TabControl caption. Since LV6.1 we have the property Independent Label to have caption text independent from the logical names on TabControl pages. The hidden front panel elements are not really a solution for us. We don't have such fixed Tab size and structure. From my view it should be possible to have a tool for it like for the other front panel elements.
The next problems are concerning the ring item list, hidden unicode on boolean, ..... Please have a look at the attachment (Unicode problems.zip). I hope you will support me like you did it before.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
LVTester:
Unicode input need double space.vi >> See Read Unicode from String Control.vi example on how to create the behavior you need at run-time
Tab Control: I added another function and example for the Tab Control Pages
The other three problems you show are bugs in the Unicode implementation. I will forward them to the development team.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
For some reasons I still have to work with Labview 8.5.
Can you save the examples for LV 8.5?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I can not get the boolean text to work. the boolean caption works fine., Thanks. is the a big reason why the code is password protected?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Christian,
Is it possible to complete the library with a Tool_Unicode Update Boolean.vi (but for boolean with action "arming at release". the one in the library just work with the boolean with action "commute until release"
I tryied to modifiy your vi but I just succeed for caption, not for text. (due to password on "tools_unicode_display_boolean.vi")
regards
jerome
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Jerome,
I have reposted the LV 2009 version of the VIs without password protection. Hopefully this should provide you the ability to make the necessary changes for your Boolean controls.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
How did you get Caption.InterpAsUnicode ? I'm looking through properties of any control and I can't find it.



- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
please refer the following section in this document
LabVIEW Configuration for Unicode
and restart the LabVIEW. you should be able to View those properties. Caption--> Interpret As Unicode.
அன்புடன்
தமிழ் நேரம்
முதல் இந்திய ஆய்வுமெகபொப சிற்பி
சோதனைநிறுத்தம் சிற்பி
மற்ற சான்றிதழ்கள்
யாதும் ஊரே! யாவரும் கேளிர்!!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
This unicode is handy and all, but until it work or you have some way to make it work on the menu bar, it fall short of being a real solution for multiple langauge. in the western us we have a host of multi cutural people all looking at the same program. it would be nice if we could change it also on the fly to be a different langauge. or maybe a make a menu bar control that we use in place of it. that we could modifiy.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I did what is described in this section but still I can't see those properties
es.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
You must use the VIs LV_Unicode-115-lv2009 (no password).zip (433.5 K)
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Having those prepared VIs is great, but I want to know how it's done. I can see that author uses xxx.InterpAsUnicode property but I fail to find it in my environment even after enabling unicode in *.ini file. I don't know how to enable that property 
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Top secret, need to know basis. if you know it could change the balance of world power.. ok just kidding.. NI wishes for many parts of LabView to be off limits to the normal developer. I am sure they think there is a good reason for it.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Pitol,
As described in the document these properties are not officially supported by LabVIEW and are enabled through special settings in the development environment along with other similar interfaces that are not exposed publicly at this time.
For Unicode support these are the only two relevant properties. Using the property nodes from the existing examples you can now use these properties on other controls as well if they are availbale for these
controls.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I assumed that those properties are some kind of NI magic stuff  But is it safe to use properties that are not officially supported?
But is it safe to use properties that are not officially supported?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
is there any hidden property to view enum Strings[] in Unicode?
-------------------------------------------
In claris non fit interpretatio
-------------------------------------------
Using LV from 7
Using LW/CVI from 6.0
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
vix,
Enum strings are part of the programming logic (e.g. they are used to name the cases of a case structure) and can therefore not be Unicode and can not be changed at runtime. The Strings[] property of an enum will return the current set of (ASCII) strings in the Enum definition.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I am using the Report Generation toolkit to load excel worksheets. One of the sheets has mixed chinesse and english columns. When I read the column with the Chinese in it I get all ??? (question marks) back. How can I read excel cells into labview? I have my labview setup so I can copy chinese characters out of my worksheet and paste directly into a frontpanel text box and that works great. Just when I load the cell into memory then prepend the BOM then put into text box does not work.
Thanks for any help
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi jboden,
When you say "I have my labview setup so I can copy chinese characters out of my worksheet and paste directly into a frontpanel text box", I assume that means you followed the instructions on this document to enable Unicode in LabVIEW controls. While the UseUnicode token allows to support the display of Unicode text in LabVIEW, it has its limitation and doesn't make LabVIEW a fully Unicode compliant application. What it allows is to render a Unicode string properly on screen, but it doesn't guarantee that the LabVIEW string manipulation functions will work, nor any toolkit functions like the Report Generation Toolkit. That's why this feature is private and unsupported.
For example here, I think it would be a safe bet to say that the ActiveX calls to Excel used in the Report Generation Toolkit are still trying to convert the Unicode Excel text to your system codepage (or system locale). Unless you change your system locale (aka "Language for non-Unicode programs") to Chinese (and be careful to know whether you are dealing with Simplified Chinese or Traditional Chinese), this conversion will fail and give you question marks.
So in this case, I would advise you to change your system locale to the proper Chinese encoding and try this again. At that point, you won't need the UseUnicode token to display Chinese because your whole system will already be set to intepreting dual byte chars as Chinese.
Let me know how this works for you. Good luck!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I'm making multiple language i my application and I have used this article and find it very helpful.
But now I have a problem to translate the pages on my tab control.
You have an example of how it works which works fine.
But if I add a new page to the tabcontrol the new page doesn't accept unicode.
My question is what kind of property you have made on the first pages?
Hope you understand what I mean.
Best regards
Simon
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Simon,
When you add a new page to a tab control, the display on the new page is not Unicode by default. You need to change it to Unicode display, you can do that by copy/pasting a Unicode string from another application into the page tab. You need to do this just once manually and then the display will be Unicode. This needs to be done for each tab page individually. Unfortunately there is not a programmatic way to make this change.
When I need a Unicode string for this or other similar purpose I normally use the Google Tranlsate page, translate English text to Chinese or another non-Latin character language, and copy the translated text. Google Translate is also how I created all of the strings in the examples (just in case any of the translations seem strange).
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Displaying Unicode on frontpanel elements works, as far as I noted, fine.
But I could not manage displaying charakters on menue or frontpanel titels.
Is this not possible or have I done something wrong?
Regards
Spirou
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Spirou,
Unfortunately LabVIEW currently does not support Unicode text for the VI (run-time) menu or window title.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thanks.
That was so much easier than I expected.
I thought that I needed to do something programmatic.
Thanks for the help.
Best regards
Simon
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Nearly three years ago I showed a problem with Unicode on ring front panel element drop-down list. It seems noting happen and I still get no professional support on that issue from my local NI support.
Now I like to use that channel again to ask NI and the community for a solution or work-around.
To understand the problems please have a look on “Ring front panel element with unicode.jpg”
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Nearly three years ago I showed a problem with Unicode on ring front panel element drop-down list. It seems noting happen and I still get no professional support on that issue from my local NI support.
Now I like to use that channel again to ask NI and the community for a solution or work-around.
To understand the problems please have a look on “Ring front panel element with unicode.jpg”
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I have a fix for your problem, https://drive.google.com/folderview?id=0B2PQnQevlIl9UEgwSlluT2pqMW8&usp=sharing
The vi's are done in LV 2012
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
How did you solve this? Thank you!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I noticed that while working with this toolbox sometimes it happens a mess on the fonts and the numbers of numeric indicators are shown with meaningless characters.
After my investigation I think it is because the numbers are somehow interpreted as unicode.
Is there a function to force "Interpret as Unicode" to False for numbers of numerical controls and indicators?
-------------------------------------------
In claris non fit interpretatio
-------------------------------------------
Using LV from 7
Using LW/CVI from 6.0
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I was having the same issue, it was completely random and still I have no
idea which is the true solution. But often, after recreating corrupt
controls, the problem goes away.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Unfortunately this does sound like a control that is getting corrupted. There are no properties or methods to control the numerical text in regards to Unicode, as Unicode should not be used with the value displayed in the control.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hello Christian,
I'm not sure if this is a corrupted control.
As a matter of fact, if you chnage UseUnicode to "False" in the LabVIEW.ini file and leopen LabVIEW, the control is shown properly.
I think that for some strange reason, LV starts to interpret as Unicode the numbers of the control, and it shouldn't do this for any reason. I think this is clearly a LV bug, but in my application I can install a fix, but I can't upgrade to a newer major release of LV. This is why I asked for a property to force LV not to interpret the numbers as Unicode.
You can fix the problem clicking on the control and enetering a new value, but you must do this for every numerical control that shows this problem!!
-------------------------------------------
In claris non fit interpretatio
-------------------------------------------
Using LV from 7
Using LW/CVI from 6.0
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Hi everybody, I find a way to reproduce a common bug displayed when using Unicode.
The VI can be downloaded here (LV2012): https://dl.dropboxusercontent.com/u/12080600/Unicode%20Bug.vi
1: On the block diagram, double click the label with "n°" inside and copy&paste the text inside the second string of the array,

2: if needed refresh the screen (by scrolling down&up with the mouse) and now the string array will appear like this:

3: double click the label with "ABC" inside and copy&paste the text inside the first string of the array and now the string array will appear like this:

Note: there is an extra space between "n" and "°"
Can this be helpful to solve the bug?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I confirm the bug in LV2015 too
-------------------------------------------
In claris non fit interpretatio
-------------------------------------------
Using LV from 7
Using LW/CVI from 6.0
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
This is actually not a bug, but expected behavior.
In your VI the ABC free string is in ASCII, while n° is in Unicode. When you paste either one into the string array you change the whole string array to either ASCII or UNICODE.
ASCII ABC when converted to Unicode becomes 䉁. Actually it becomes 䉁C, as each Unicode character is 2 bytes, but LabVIEW does not display the extra byte which is the C.
When UNICODE n° is converted to ASCII it becomes n °.
The best solution in this cases is to use UNICODE for all strings, and use the UNICODE version of ABC.
In LabVIEW it can be difficult to create a UNICODE version of a normal ASCII string. For this purpose, the version 2.0.0.4 VIP of the Unicode tools above, include VIs to convert between ASCII and Unicode (UTF-16LE).
Another option is to:
- Create a string control or constant.
- Type in the string you want to convert to UNICODE, e.g. 'ABC'
- Right click on the control or constant and turn on 'Force Unicode Text'
- The text that is now displayed in the control or constant is a Unicode version of the original text.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
