- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
read character from file
10-28-2007 12:56 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
10-28-2007 01:04 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
10-28-2007 06:26 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi,
Here is the read from characters1.vi
Adam
10-28-2007 06:57 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
;Human Chromosome 1
CONTIG-1p1
And then has the list of character codes. If your offset in your other string is based on the start of data, not the start of the file, then, for this file, you will be 31 bytes off. If this header is constant, then you can add 31 to your number. If this header can change, then you'll need to determine its length.
If these files aren't that big, you should load the file, then process it instead of doing constant file I/O to get one byte at a time.
10-28-2007 07:45 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi,
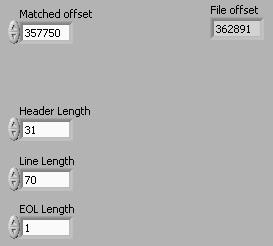
The header stays constant. The program is supposed to open a text file. Contained in the text file is the location of the sequence match in chrom1.p1 based on character postion and the length of the match. The program then calculates the sequence match postion - 500 and the ((sequence match postion+ length) + 500). The program is the supposed to open chrom1.p1, goto the character postion and count the nucelotides until the program reaches 500. It does this twice, once for the 500 before and once for the 500 after. When I run the program for the first match, which begins at character postion 357750 and ends at character postion 358005, I had to add a constant of (5141+(357750-500)+ iteration) to get it to go to the correct location. For the rest of the matches, using this constant makes them all off.
Adam
10-28-2007 08:29 PM - edited 10-28-2007 08:29 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I think you have a lot of unnecessary complication in your code. First I would recommend cleaning up all the wiring. Use right click clean wire to get rid of unnecessary bends. Line up your functions so that data flows from left to right without an excessive number of bends. There is a log of iterative string searching and cleaning going on in the upper left. This could probably be looped, or a scan from string function could return a lot of these values in a single step. But is it possible that your counts are off because of characters that you are or aren't stripping out on the preliminary code? Also, local variables would be better to use than the Value property nodes. Shift registers would be better still.
There seems to be no reason to read or write to the files one character at a time. The code would be a lot more efficient if you read all 500 characters at once. Then do your search routines. You know you are reading exactly 500 characters because you are reading 1 at a time and executing the loop exactly 500 times. Each execution is doing an open, read and close of the file.
Since it seems like your problems are in determining the start position, concentrate on that preliminary code where you calculate the start position. Put indicators on the various strings and numeric values to see if those functions are performing they way you want. Since you are having issues with the start position, perhaps the errors are in the math that calculates the start position. Your second flat sequence doesn't seem to take into account the length of the search string. It looks like it takes a part of the search string and converts it to a number. Maybe the error is in the data in that string control and not in the calculations.
Message Edited by Ravens Fan on 10-28-2007 09:34 PM
10-28-2007 10:16 PM - edited 10-28-2007 10:16 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
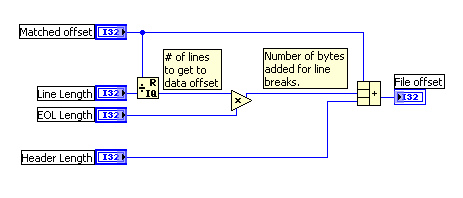
You can avoid this by reading the file in, stripping the header, and removing all the line feeds. Your data should be one contiguous stream at that point. But, you will need to determine if loading the whole file to do this is practical. With this calculation, you can do it a byte at a time if you wish.
Message Edited by Matthew Kelton on 10-28-2007 10:17 PM
{kind=link}
{kind=link}
