- Document History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Traditional Versus Object Oriented Programming in LabVIEW
Object oriented programming (OOP) in LabVIEW has many benefits, but for those who've learned LabVIEW apart from the OOP paradigm, the transition can be daunting. I wanted to help bridge the gap by providing some high level definitions of terms, explanations of OOP concepts, and show a "before and after OOP" application attached at the bottom of this document. These OOP principles help facilitate designing software that is scalable, modular, extensible, and reusable.
I'll start with a brief description of the three major concepts of OOP:
1. Encapsulation
2. Inheritance
3. Polymorphism
Encapsulation
Loosely defined, encapsulation means "the practice of hiding the unimportant details of how a software module accomplishes its task". Of course, the details are important to you as the programmer of the software module. But the user of the software module often doesn't need to know how the task is accomplished.
We often inadvertently create a set of VIs designed to work on a specific cluster of data, usually a Type Def, thus accidentally forming a software module. Intentionally applying the encapsulation philosophy to the data means we would deliberately and strictly design a set VIs that get / set values of the cluster and / or operate on the cluster. Only these VIs would be able to interact with the cluster. If the cluster is accessed outside of one of the "sanctioned VIs", we want LabVIEW to break the run arrow. This strict enforcement of data access and manipulation helps to prevent a code module from being used outside its intended design.
Encapsulation can not only be applied to the data, but also to the module's VIs. We've all written VIs that support the overall goal of a software module, but aren't meant to be called in any way other than as a subVI in the software module they are supporting. Without applying encapsulation, the support VIs could be reused by other developers. Then the original author is obligated to not change those subVI's behavior for fear of breaking unintended clients. Another way to think of encapsulation is the prevention of establishing dependant relationships.
Carefully considering how the data of your software module is accessed and what VIs are allowed to be used outside of the software module helps prevent unintended dependency's from forming (aka coupling) and promotes cohesion.
Range checking / data validation is just one great demonstration of encapsulation's value. For example, if you're creating a data acquisition application that also logs data to disk, you may want to allow the user to specify the save location of the log file. Your code may look like:
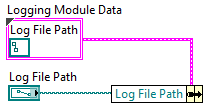
But you may also want to restrict the file's location to a specific portion of the hard drive. Without using encapsulation, you'd need to keep track of all locations in the application where the path could be updated and then perform some sort of check at each location. This method is prone to error because a developer might miss places in the code where the path is set, or simply forget to check at all. These oversights are magnified when the code is passed off to another developer. To help solve these problems consider making a subVI such as the following:
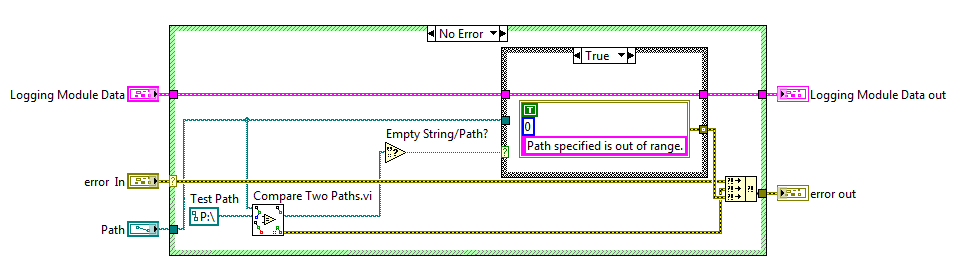
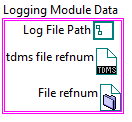
This subVI would be the means by which the "Log File Path" was set (a bundle by name updates the cluster). It would also be responsible for enforcing the rules for "Log File Path", namely that files can only be written to the P:\ drive. We've consolidated the checking logic into this one VI. But without the encapsulation features of LVOOP, a developer is free to simply bundle and unbundle at will outside of this VI. However, with OOP, we can direct LabVIEW to associate a VI with the Logging Module Data such that the run arrow will be broken if the Type Def is accessed outside of the sanctioned VI (the association process is described later in the section "Associating a Type Def with VIs - a.k.a. How to create a class").
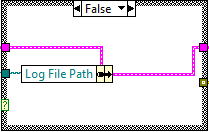
Now our logging application looks like:
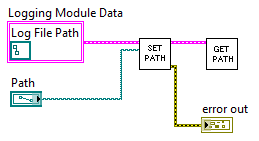
We've directed LabVIEW to associate the Set Path.vi and Get Path.vi with the Logging Module Data so that only these two VIs can be used to access the "Log File Path" member of the Type Def.
Another example of encapsulation traditionally practiced is the use of LabVIEW Functional Global Variables (a.k.a "action engines"). By design, the cluster never appears on the block diagram outside of the action engine. It's contained in an uninitialized shift register, preventing unauthorized or ill defined interactions with the data.
There are a number of articles to help explain actions engines:
Basic Functional Global Variable Example
Community Nugget: Action Engines.
Clearly defining access to your code module's data via a set of top level VIs frees a developer from the burden of tracking interaction locations within the code module (such as the logging example above) since LabVIEW breaks the run arrow with each incorrect interaction. It also prevents unintentional coupling across software modules by defining a set of top level VIs designed to interact with the module. In addition, by providing a set of VIs to act on the data, you create an intuitive interface for anyone who may want to use your code module. Thus, the functions themselves become the documentation.
Inheritance
Inheritance, loosely defined, means that data (Type Def) and functionality (set of VIs) in a code module can be used as a foundation for other related code modules. Another way to think of it: inheritance allows you to build up functionality of a module by building on previous work, one "layer" at a time. Each layer gets all of the functionality of the one beneath it, but can then be edited and customized, leaving the original layer alone. The newly customized module can then itself be used as a foundation for further customization. The primary advantage of inheritance is code reuse and appropriate separation between each module. Consider the following graphic:
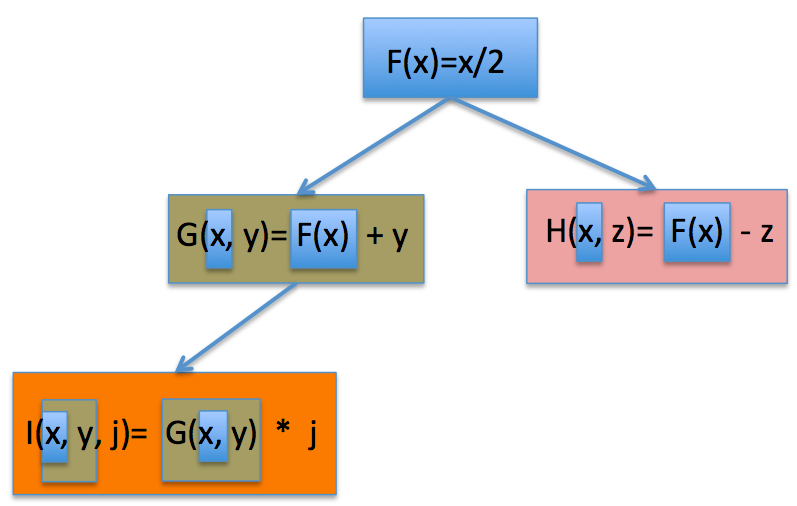
Each colored rectangle represents a code module that does "something" with some input unique to itself. (I'm using the familiar math notation for a function to aid in the demonstration.) The base layer is a function named "F" that takes in a parameter, x, and divides it by two. I then want to build two other functions with F at their core, each with their own additional behavior and parameters. Using inheritance define two new functions, G and H, each with their own input parameter, y and z respectively. Because G and H inherit from F, they each get F's functionality and parameters "for free", but can then define their own behavior and specify their own parameters. In G's case, it calls the base layer, F, and then adds y to it. Therefore, executing G requires an"x" parameter and a "y" parameter. In H's case it calls the base layer, F, and then subtracts z. Therefore, executing H requires an "x" and a "z". To further demonstrate the concept, I define a function, I, which calls G which calls F. Therefore to execute I requires an "x", a "y" and a "j".
This looks and feels very similar to a VI hierarchy where each subVI is represented by a function (F, G, H, I). By changing the behavior of F, all of the layers built on top would automatically get the new behavior of F because they inherit from, a.k.a. built on top of, F. But the major difference between a VI hierarchy and inheritance is the parameters for each function. Although we can easily create a VI hierarchy today, there is no way to create independent data hierarchies. Put another way, because H calls F, there is no way for H to be "ignorant" of y (used by G). That unnecessary "knowledge" leads to high coupling and low cohesion. Inheritance solves this problem by allowing independent data hierarchies.
As an example, let's go back to the data logger mentioned above. There are many file formats to choose from, each with specific advantages and disadvantages. For example, some file formats are human readable but have slower performance (like a text file) whereas other file types will require a file reader (such as a LabVIEW data log) but have better performance. We decide to create a single API that can perform both actions and abstract away the details. (Abstraction means hiding away all but the details relevant to the task, in this case saving data to disk).The common element to all logging types is a path to a file. So our base layer would have a Type Def that contains a path. Let's say that we wanted to be able to write a TDMS as well as a Binary file. Traditionally, we would put all of the information necessary for both TDMS and Binary in the same cluster.
Then we would put a case statement in each VI to operate on either file format so that the same VI could be used for both TDMS and the Binary type. We would also pass in a command to each subVI so they would know which file format to write.
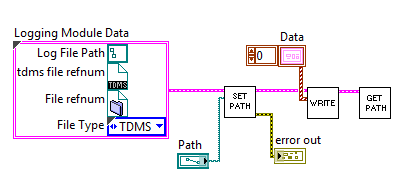
In this scenario we no longer have separate and clearly defined VIs for TDMS and Binary files. They've been merged together into a single set of VIs and the cohesion has decreased. Further, the cluster itself becomes a "dumping ground" for the parameters across all of the VIs.
Here's the problem with the "dumping ground" approach: the number of cases in each case structure will increase as different types of information creep into the Logging Module Data. What happens when we want to add a new file type? Or what happens when we start specifying file type specific information such as "big-endian". For each new ability or each new file type, the cluster grows, the original VIs need to be edited, and then revalidated. There's also a high likelihood that once the code is passed along to another developer, they will add more information to the cluster beyond the original intent. As time goes on cohesion decreases and coupling increases making the logging module difficult to support and costly for feature addition.
Inheritance in OOP solves this problem. Instead of adding information to one main cluster, we create a base layer for "log", containing a path constant. Then inherit once for the TDMS type and then again for the Binary type. Because we inherited from the "log" layer, both the Binary and TDMS layers automatically get a "path" constant in their Type Defs, but each new layer is "ignorant" of the other, thus preserving cohesion and preventing coupling. Now we can add new data to each layer's data without the layers affecting each other. Consequently, two new Type Defs are created that look like the following:
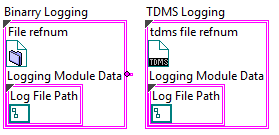
But now that we have two Type Defs, how can can they both be passed to the logging functions? A benefit of inheritance in LabVIEW is: different data types can flow along the same wire, so long as that wire is from a common layer. Now that the data type on the wire can change at run time, won't that break the VI that uses the data? Polymorphism, the third facet of OOP, is the answer to that question.
Polymorphism
In the traditional LabVIEW programming paradigm, we already have the notion of "polymorphic VIs". A polymorphic VI is a single VI node on the block diagram that can change behavior depending on the data you wire into one of its terminals at edit time (when the code isn't running), or depending on which instance you select from the ring selector at edit time.
The DAQmx Create channel is a well known example of a polymorphic VI. DAQmx Create Channel.vi allows you to create a Voltage, Current, Force, etc channel depending on the selection from the ring selector. However, once the selection is made and the program is running, that selection cannot be changed. The "Variant to Data" primitive is another example of a polymorphic VI. Although it has no ring selector, the "data" output will change depending on what's wired into the "type" input. Again, this change in behavior is all at edit time.
By contrast, with OOP in LabVIEW, polymorphism means "the function to execute will change depending on the data type passed to it at run time". This terminology can be confusing. In order to clarify the edit time vs. run time difference in behavior, LabVIEW OOP polymorphic VIs are called "dynamic dispatch" VIs. The term "dynamic" refers run time versus edit time, and dispatch referrers to the change in functionality. Literally, a different VI will execute depending on which Type Def is passed to the VI at run time. The VI node on the block diagram acts like a place holder, similar to the Call by Reference node. The VI that will actually execute at run time is determined once that placeholder receives the Type Def at run time. A benefit of inheritance in LabVIEW is: different data types can flow along the same wire, so long as that wire is from a common layer. This property is described in detail in "Demonstration of Polymorphism" below.
As a result of polymorphism, a single VI node on the block diagram can have many behaviors. The behavior depends on which Type Def is passed to it at run time. The nature of the dynamic dispatch VI node allows us to separate and organize functionality and preserve high cohesion and low coupling.
Continuing with our logging example, the two children layers, TDMS and Binary, inherit from the common "logging" layer that has a path constant in its cluster Type Def. Then each child layer adds its own unique information and, therefore, are different data types. However, again, both came from the common base layer. To reiterate, different data types can flow along the same wire, so long as that wire is of a common base layer. In other words, both a TDMS Type Def and a Binary Type Def can be passed on the same wire so long as that wire is of the "log" type. Since both a TDMS and Binary Type Def can be passed on the same log wire, the "write" function can dynamically dispatch the correct version of write that matches with the data passed to it.
It is important to note that the notion of designing VIs around a data type, and that the data type on a wire determines what functions execute is the paradigm shift between OOP and classic LabVIEW programming.
OOP Class Formal Definition
At this stage I need to pause and give the formal definition of a LabVIEW OOP class. Thus far, I've been using the terminology "body of code", "code module", "cluster", "layers", and "type def". To reiterate, the code module is a set of VIs designed to accomplish a single task. In our example so far the task has been to write to a log file. The Type Def contains the data used by the code module to accomplish the task, in this case the path and file refnums.
- In LabVIEW Object Oriented Programming, a "class" is the combination of a set of data (a type def), the set of VIs designed to operate on that type def, and the ability to build layer on layer (inheritance).
- An "object" is an instance of a class. This is the "object" of "Object Oriented Programming". As mentioned above "the notion of designing VIs around a data type and that the data type on a wire determines what functions executes is the paradigm shift between OOP and classic LabVIEW programming." The program is oriented around objects, a.k.a. instances of classes. In the classic LabVIEW programming style, the program is oriented around individual VIs.
As an analogy of "instance", when you drag the .ctl of a Type Def onto a block diagram, LabVIEW places an instance of that type def. Editing the original definition causes instances to update with the changes.
In the graphic below, the constants on the right side of the "=" objects of their respective classes. The traditional representation of a type def is on the left and the OOP representation is on the right:
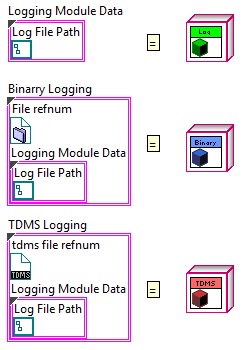
(You'll notice that TDMS and Binary contain "Logging Module Data" in their Type Defs. TDMS and Binary both inherited from log, and therefore have log's data and abilities.)
Demonstration of Polymorphism
To demonstrate how polymorphism solves the problem of passing different data types to the same VI (the question posed at the bottom of the inheritance section) consider the following block diagram.
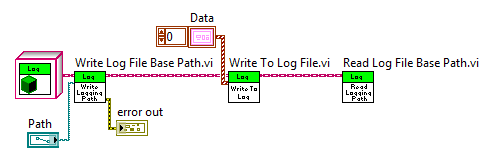
The "Log" wire type is passed between all three VIs, and Log is the parent of Binary and TDMS. The Binary and TDMS class each have a path in their data because they inherit from the Log class. Because they both inherit from Log, there is no need to re-implement how the path is set for the Binary and TDMS classes. To reiterate, both TDMS and Binary get the data and abilities of thier parent. In this case, the Write to Log File Base Path and Read Log File Base Path.
Now consider the diagram below.
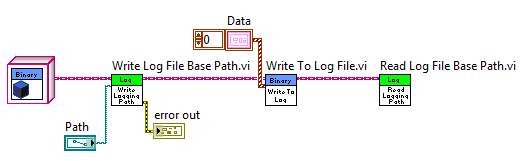
Polymorphism allows us to invoke a different "Write" instance by changing the object that is wired in. The log file generated from this block diagram will be a binary file type because the Binary object is passed on the parent's wire to each VI. LabVIEW automatically selected the correct VI implementation because of the association between data type and functions (Binary Class and Binary's implementation of Write to Log File).
To change to the TDMS version, simply change the object passed on the wire. Again, LabVIEW automatically chooses the correct dynamic dispatch VI.
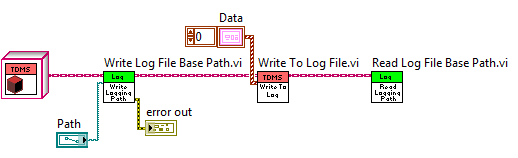
Both of the examples shown above are edit time changes. I placed two different objects on the block diagram and wired them into the "write Log File Base Path.vi". But to demonstrate the RUN TIME behavior of dynamic dispatch, see the following block diagram:
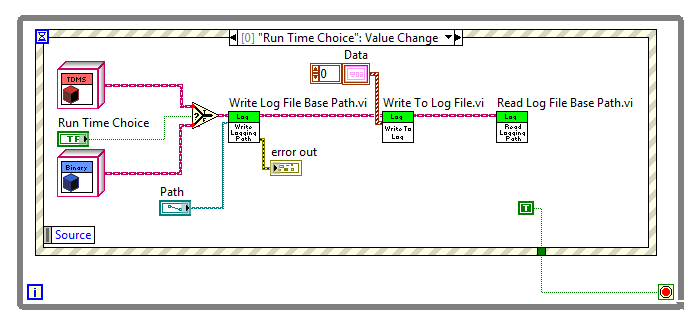
You'll note that the parent's implementation of the "Write to Log File.vi" function is shown on the block diagram. In this case, LabVIEW doesn't know which object will be passed to the "Write to Log File.vi" function at run time, so it displays the parent's implementation because it is common to both possible objects. Once the code runs and the user presses "Run Time Choice", the "true" selection will pass a TDMS object on the parents wire which will cause the TDMS class' "Write to Log File.vi" to execute.
Associating a Type Def with VIs - a.k.a. How to Create a Class
When creating classes in LabVIEW there are many options. The following articles from the online LabVIEW help documentation have all of the necessary steps.
Creating a LabVIEW Class - The step by step mechanics of creating a class
Changing the Inheritance of a LabVIEW Class - The step by step mechanics of creating the inheritance relationship between two classes.
Creating a Member VI in a LabVIEW Class - The step by step mechanics of creating the different types of member VIs of a class.
Creating LabVIEW Classes - An in depth discussion of OOP topics, such as Inheritance, Polymorphism and Encapsulation
An application written with OOP versus traditional programming in LabVIEW
I've been asked by numerous customers for an example application implemented using the traditional LabVIEW style versus the LabVIEW Object Oriented style. I decided to use the very well known "Continuous Measurement and Logging" sample project that ships with LabVIEW. It's designed to simultaneously acquire from hardware (simulated in this case), log the acquired data to file, update the graph of the front panel, and respond to user events, such as button presses. I've taken a very small section of the application, namely the file IO module, and replaced it with an OOP implementation.
You can see all of the edits I made by opening up the bookmark manager (View>>Bookmark Manager) and noting all of the C_Cilino_OOP hash tags. Double clicking on each tag will take you to the edit location. I've endeavored to change as little as possible to make the comparison as easy as possible. The VI Package installs the Classed Based Logging application to <LabVIEW>\examples\National Instruments\Class Based Logging.
Note, I've implemented two sub classes in the project and put them in an .lvlib. This .lvlib is designed to work beyond the scope of this sample project.
You'll note that the program is hard coded to select TDMS but can easily be changed:
Conclusion
Object Oriented Programming shifts a programmer's perspective from functions to data. This shift lends itself to better software design so that individual functions and code modules have low coupling and high cohesion. Encapsulation, inheritance, and polymorphism facilitate good software design so that the features in your applications will be more scalable, modular, extensible and reusable.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Loosely defined, encapsulation means "a clearly defined way to interact with a module of software".
That's an Interface, not Encapsulation. Encapsulation LEADS to the need for an interface, but they are not the same thing. I'm not sure if muddying the waters at the beginningof such a document is a good idea. Maybe I'm just being pedantic.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Intaris wrote:
Loosely defined, encapsulation means "a clearly defined way to interact with a module of software".
That's an Interface, not Encapsulation. Encapsulation LEADS to the need for an interface, but they are not the same thing. I'm not sure if muddying the waters at the beginningof such a document is a good idea. Maybe I'm just being pedantic.
Hi Intaris,
Strictly speaking I agree with you. Here are some definitions of encapsulation from the web I found by doing a quick search:
The packing of data and functions into a single component.
Encapsulation is a way of organizing data and methods into a structure by concealing the the way the object is implemented, i.e. preventing access to data by any means other than those specified. Encapsulation therefore guarantees the integrity of the data contained in the object.
My loose definition was intended to make the idea of encapsulation accessible to our LabVIEW community by not introducing words like "packing" "method" "protect" etc. The idea of "interacting" can easily be understood in representing accessors by VIs.
But I think your point has merit and I'll augment the definition. I consider this document a work in progress, providing further clarification, examples etc as comments on the forum grow. If the article gets too big (and it's already approaching that limit) I may break each topic into another document.
My highest goal in this article is to make OOP accessible to anyone who might want to quickly learn about it and investigate if it is the right method for their application. I'm actually going to be giving a presentation at NIWeek 2014 on an Introduction to Object Oriented Programming.
Like you, I'm a lover of words so I appreciate your feedback!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Encapsulation is both the means and the end of abstracting away class data and private methods, leaving an intentionally truncated public API. The word interface can be overused in our line of work (customer, panel, wiring, UI, messaging, API, public). In the context of OOD, I like the way Java uses the term (and suppose that LabVIEW will one day support the concept in the following context): Java Inteface from Wikipedia:
"Interfaces are used to encode similarities which the classes of various types share, but do not necessarily constitute a class relationship. For instance, a human and a parrot can both whistle; however, it would not make sense to represent Humans and Parrots as subclasses of a Whistler class. Rather they would most likely be subclasses of an Animal class (likely with intermediate classes), but both would implement the Whistler interface."
One idea is to just redefine encapsulation in the article and refer to "interface" as API when necessary.
Certified LabVIEW Architect
TestScript: Free Python/LabVIEW Connector
One global to rule them all,
One double-click to find them,
One interface to bring them all
and in the panel bind them.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
I agree with Intaris. "A clearly defined way to interact with a module of software" is the definition of an interface or API, not encapsulation. If I had to define encapsulation, I'd go with something like...
"Encapsulation is the practice of hiding the unimportant details of how the software module accomplishes its task from the users."
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Leave out the word "unimportant". 🙂 The details are important, but not to the caller.
Data in an action engine is encapsulated behind the API exposed by the action engine VI.
A private method of a class is encapsulated within the class.
An entire class may be encapsulated by being marked private to the owning library.
These are all forms of encapsulation. But in all cases, access to those items is permitted only via the public interface.
I think the distinction between "interface" and "encapsulation" is that any interface is the way of interacting with a software module. Encapsulation is specifically when activity of that module is not exposed in the public interface.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Very nice, and I learned a lot from the talk at NIWeek. I'm currently "diving into" my first Traditional to OOP conversion and have a question. I'm defining an "Abstract Class" called Input Device that has methods "Open", "Sample", and "Close". I defined two child classes that inherit from this class, and I created Open, Sample, and Close using "VI for Override".
There is reference in several places to doing this, and noting that if the parent class doesn't "do" a method, it can mark it as "Must be overridden". To quote -- "To ensure LabVIEW enforces this requirement, you can mark the VI in the parent class as one that each child must override and let LabVIEW enforce the requirement". How do I do that? I could not figure this out. I should note that when I created the parent's "empty" VI (say, Open), I created it as a New from Dynamic Dispatch, and simply saved it.
So far, I'm having fun ...
Bob Schor
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Bob,
This feature is available in the Class Properties dialog on the Item Settings page. For methods with suitable properties there is a "Require descendant classes to override this dynamic dispatch VI" checkbox.
Paul
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Thanks. I missed the Item Setting page ...
BS
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Daklu wrote:
I agree with Intaris. "A clearly defined way to interact with a module of software" is the definition of an interface or API, not encapsulation. If I had to define encapsulation, I'd go with something like...
"Encapsulation is the practice of hiding the unimportant details of how the software module accomplishes its task from the users."
Bravo! So well said, I've shamelessly stolen your definition. 
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Consider what one of the early thinkers had to say, quoted from Wikipedia:
"In his book on object-oriented design object-oriented design, Grady Booch defined encapsulation as "the process of compartmentalizing the elements of an abstraction that constitute its structure and behavior; encapsulation serves to separate the contractual interface of an abstraction and its implementation."
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Chris,
Thank you so much for putting these resources together. I have been studying them and I think OO is finally sinking in.
I have been trying to understand OO for years.
Thanks so much!
Dan Shangraw, P.E.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
hello all, while i am stuck at home during this pandemic and having to telework, i wanted to increase my LabVIEW programming capabilities. so, i started the on-line course "Object-Oriented Design and Programming in LabVIEW". However, problems soon arise that i cannot get past. the course work that i downloaded from NI is dated 2010 so im assuming that was the preferred LabVIEW version. i am currently running LabVIEW 2018 PDS. the topic is Inheriting Methods from a Parent Class. i'm at the point where my version of LabVIEW does not work in the way that the course work implies that it should. at this point in the course i have created a project, added a virtual vi to contain all of my classes, i have built one class and set the properties as described, and i have built methods for the class. in this section i am to use Windows Explorer to drag in other classes that have already been built and included in the course, into my virtual folder. this part does not work.
i apologize for giving too much info but i have spent over a week trying to get past this problem. i'm sure the answer is simple. i just haven't found it yet and need some help or guidance.
