- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Managing batch 2D FFTs on a GPU
07-28-2016 11:27 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hello, I'm afraid that I'm pretty new to GPU computing, and this may be obvious to the more experienced!
The "Multi-channel FFT" example was really helpful in getting set up with GPU computing on LabVIEW, particularly the commented sections explaining what's going on. I've sort of managed to adapt this to my own application in image processing, but I'm looking to optimise my code for execution speed.
The Multi-channel FFT example initialises the cuFFT library to batch-process 1D arrays. It then allocates memory for a 2D array of 1D samples, to be batch-transformed each time the WHILE loop executes. My question is: what's the best way to generalise this to batch processing of 2D arrays?
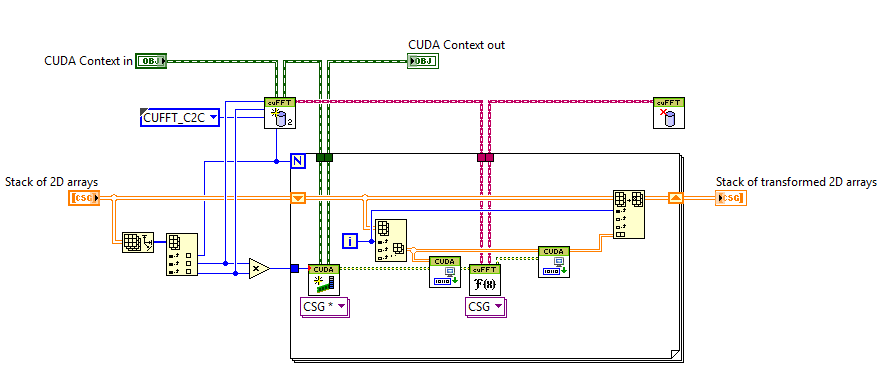
I have a stack of 2D CSG arrays (derived from image data) that are held in a 3D array. I want to transform each page of the 3D array, returning another array of CSGs. The image below shows one way to do this, but I'm not convinced that this is correctly taking advantage of the 'batch' option in the cuFFT library setup, and I expect there's a better (faster) way. Does anyone have any ideas?
My feeling is that there's a way to place all of the 2D arrays in memory in a contiguous array, and somehow let LabVIEW know how that array is divided up, but I can't see a way forward.... Many thanks in advance!
07-28-2016 11:51 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
The simplest way is to write CUDA program in Visual C, compile it into a DLL and call the DLL functions in your program.
Currently I am interested to write a client/server application that would allow to use multiple GPUs networked PCs. It is only useful if the dataset you want to process is not overwhelming for your LAN.
I am nowhere near completion...
Trying to implement Zero MQ to begin with.
Baranyi, Lajos
+1-240-483-1955
