- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Archived: Use Cases of the Distributed Control and Automation Framework
07-28-2016
10:41 PM
- last edited on
04-14-2025
10:41 AM
by
![]() Content Cleaner
Content Cleaner
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
This document has been archived and is no longer updated by National Instruments. You can find the replacement page for this information here.
The Distributed Control and Automation (DCAF) framework is a collection of open-source software that supports an effective approach to building embedded control applications with LabVIEW. To learn more about this approach and its benefits visit Introduction to the Distributed Control and Automation Framework. This article will explain common use cases for the framework, the various APIs and software components that comprise the framework, and end with details on how to get started.
DCAF Use Cases
DCAF is a powerful tool that can be applied creatively to meet a variety of application requirements. However like any other tool, the framework isn’t well suited for every job. This section will describe several use cases, in order of increasing complexity, to help users identify when the framework might be a good fit for their application.
Using DCAF with Existing Plugins
The easiest way to benefit from DCAF is as a data engine that utilizes existing plugins. A collection of plugins is provided with the DCAF installation and enable you to interface to local resources as well as I/O provided through common industrial communication protocols.
Existing I/O plugins include:
- RIO Scan Engine
- Modbus
- EthernetIP
- Profibus
Existing data exchange plugins include:
- Current Value Table (CVT)
- UI Reference Communication
- TDMS Data Logger
- UDP-based Engine-to-Engine Communication
A complete list of available DCAF plugins is provided.
Once installed, these plug-ins can be added to an application using the framework’s Standard Configuration Editor. The editor is available in the LabVIEW environment in Tools>>DCAF>>Launch Standard Configuration Editor...
In the editor a developer configures each target of the application by adding them to the system. For each target, one or more engines can be added. Each engine controls the execution and timing of the modules within it. With the editor you configure the top level loop rate of each engine.
You then add all of the necessary modules to each engine and configure them. From here, added functionality is configured by routing and connecting data through channels and tags in the application. Each data item in a module is called a channel. Channels are mapped or connected to Tags which are the data items in each engine. For example, Scan Engine input channels can be easily routed with just a few clicks to an external Modbus master, written to a TDMS data file, and displayed on a simple user interface (UI); all without detailed knowledge of the framework.
In addition to acquiring and routing data, the framework also provides various methods for manipulating or processing acquired data. For a deployed application the most sustainable route is to develop project-specific logic within a framework plugin, but the Current Value Table (CVT) plugin can be used to export local engine data to a top level VI, debugging loop, or custom processing function. The CVT allows a user to connect data within the data engine to CVT tags that can be read or written to throughout an application. This is similar to a Scan Engine I/O variable, except the I/O connected to the CVT can come from any of the framework plugins.

This approach removes the need to learn and implement the wide variety of I/O APIs in LabVIEW. A common data accessor like the CVT also allows users to easily change their data source or sinks to either a different set of hardware, or to a simulation, without having to rewrite any code. It’s much easier to reuse code with a common API like the CVT rather than with hardware-specific calls. As an extra benefit, the engine can still be used to automatically handle other tasks such as logging to data to disk.
While easy to use, the downside to using the CVT is that it bypasses some of the framework benefits. Global access to data reintroduces the possibility of race conditions. Global tags also make it difficult to support the creation of multiple instances of control logic, and limit the ability to reuse that logic across projects. It also introduces a cycle delay between data acquisition and data processing. To avoid these issues, the framework allows users to create control logic plugins that run inline in the execution of the data engine. In addition, the API for engine data and the API for CVT data are closely related, making it simple in many cases to transition between the two implementations.
User Control Module Plug-in
DCAF provides a User Control Module sample project that allows developers to create custom processing plugins with a fixed number of inputs and outputs, and run the processing logic as a module within the framework.
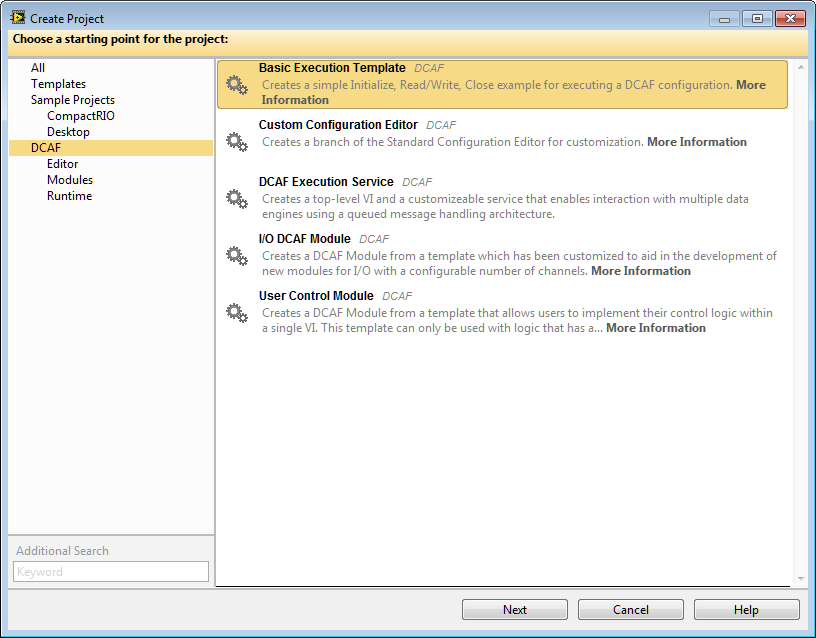
This sample project provides a dialog which the developer uses to specify the names and data types of the plugin inputs and outputs. Once entered, the sample project will script out the majority of code necessary for the new plugin. In many simple cases a user can add their logic in a single VI, such as the one below.
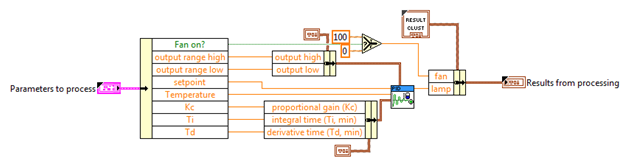
The framework offers many extension points for customizing plugin behavior, but default implementations are automatically created by the project template script. The plugin can be customized for initialization or safe-state logic, adding new configuration parameters to the editor, or by adding a custom glyph for display in the editor’s tree control.
The main limitations of this simple solution for processing plugin development is that the quantity, name, and data type of all inputs and outputs must be static. Changes to inputs and outputs are facilitated by an easy-to-use script, but the final design must be decided at edit time instead of at run time.
The framework supports plugins with dynamic run time channels, like a generic data logger whose inputs are configured in the editor, but their development is more complex, both due to requiring a greater understanding of the framework as well as the general challenges associated with developing dynamic code. Overall, the User Control Module sample project provides an easy way to create custom execution logic that benefits from the framework rules without a lot of complexity.
Other DCAF Use Cases
There are many other ways to use and customize the framework, but they require more detailed knowledge of how the framework works. Some examples include:
- Create an I/O or Data Service plug-in that supports a variable number of channels
- Customize the configuration editor for a specific project
- Create a new execution engine with customized functionality for features such as error handling or plug-in benchmarking
- Create a processing plug-in that supports its own model of computation. Existing examples include support for calling a shared library (DLL)
When not to use DCAF
DCAF is a tool for building embedded control applications with LabVIEW, but it’s not the right tool for every job. The framework is most useful for tasks that interact with single-point data needing updates at around 1 kHz or slower. As a general rule, it should not be used for application tasks that are heavy with waveform or message/event-based data. Also, while the framework has the potential to make the development of an embedded control solution much easier, it still has a learning curve. This framework is not meant as a replacement for programming or for training. Contact an NI Alliance Partner to discuss the creation of turn-key solutions.
Christian L, CLA
Systems Engineering Manager - Automotive and Transportation
NI - Austin, TX
