LabVIEW Interface for Amazon S3 is available on the LVTN and in VIPM!
Released on the LVTN and is available in the VIPM package list.
For any questions, issues or comments check the Support group for this toolkit!
First Round:
Summary:
I'm sure all of you have read a lot of documents on this Community. There is however a big problem I've experienced many times here: I cannot sort the documents. There are some filtering options, but it is impossible to browse popular, much valuable content. That's not the case any more! 
With this project you can browse NI Community groups, get all documents of the group you select, and the more importantly you can sort them by their score.
The score is based on the number of views, average rating and likes. At least by default. What's better than that? You can specify your own scoring formula.
Of course you can open each document from the program in a web browser.
This project uses many parts of this community site, it communicates with web services, downloads HTML pages, parses HTML and JSON (JavaScript Object Notation) data using Regular Expressions.
For Inter-process communication purposes I use my previous qualifying code. The project is fully event-driven.
It is highly documented, so I'm sure you will find the answer for your questions, if any.
This project uses a .NET assembly, which is open source and free to use and redistribute. I included the binaries in the zip file below, however sources have been trimmed out to save space. Documentation to it is included and there is a Readme.txt which contains author's information and the license.
I also used some graphical/decoration elements from the NI Community site, which I hope does not violate copyright rules, as this is not a commercial application and in fact the purpose of this is to serve this community.
Function:
- Browse NI Community Groups
- Display Group's documents
- Sort the documents by scoring them
- Write your own score calculation formula
- Open documents in your browser
- View document's body along with the attachments in a 2nd window
- Create report of the selected group in Excel
Second Round - Transfer data to other VI:
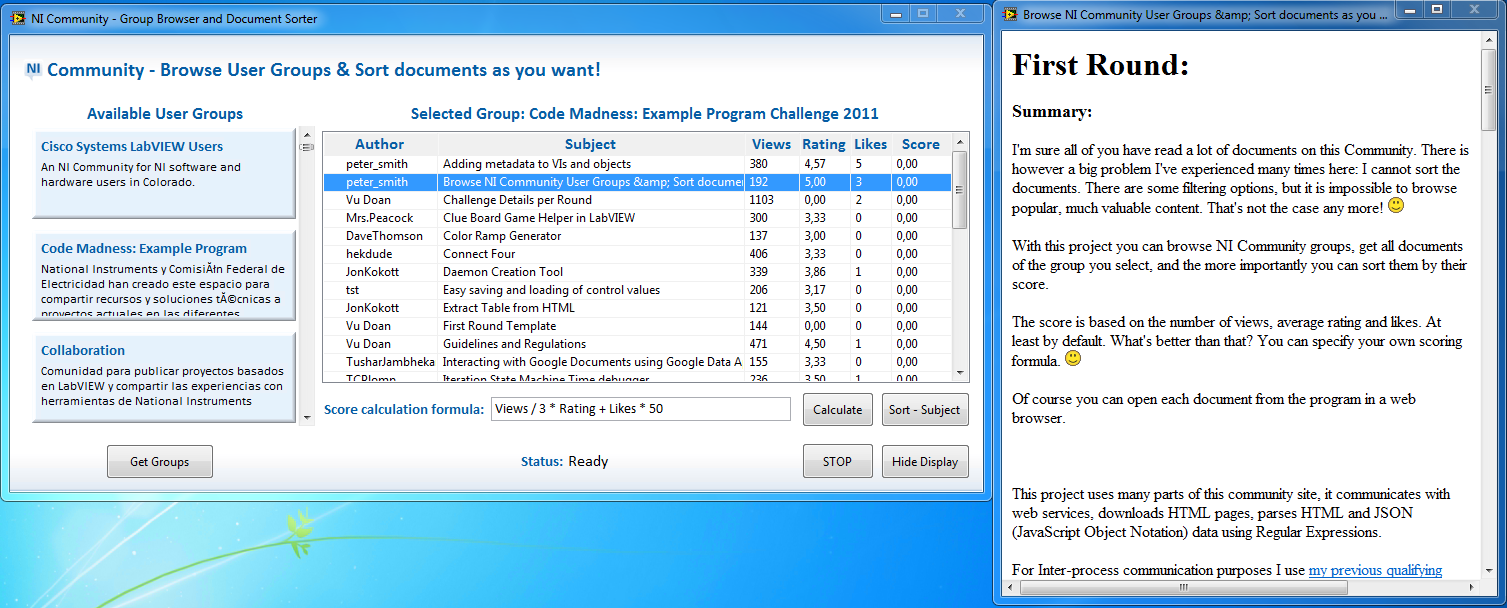
The application is extended with a new functionality: it can now display the selected document in a new LV window.
Only the document's body and the attachment are displayed. No eye-candy, page headers and footers, other side panels appearing on the community page are displayed.
There are also minor bugfixes:
- The Author name did not appear in the document list when the name contained other than alpha characters.
- The number of Views was 0 if there were more than 999 views. That was caused by the page of the document displaying views with thousands separator (like: 1,278).
Communication method:
1. For communicating with the display VI I use a queue.
The queue holds clusters as elements. The cluster contains an enum, which defines the Action the display has to take; and an optional variant that is the data which may be passed to the display as well.
There are actions, which need data to operate on, but there are others where data is unnecessary.
The de-queueing part unbundles the action and the data part of the cluster. The action is wired to the selector of a case structure, so each cases define the tasks to do on specific action commands. If an action needs the data, it may be converted to the specific type inside the case structure.
If you need a fast response to a command and that command makes unnecessary for the receiver to execute previous ones (eg: Close, Hide Panel), you can flush the queue in the transmitter side before queueing the next command.
I chose queue as it is a perfect communication method inside an application. It allows to use any data types, does not use a lot of resources, does not need the receiver to poll for available data.
The transmitter side of the transfer is the Main.vi, the receiver is the DocumentSidePanel.vi located in Display\DocumentSidePanel\ folder.
2. Main.vi already used a notifier to transfer data between VIs.
That example however shows how to combine a notifier (or even a queue) with user events. That way the received data may be transmitted to an event structure allowing the structure to stay "fully event-driven" (it is not necessary to set a timeout and poll for available data on each timeout).
Third Round - Process and display data in another Software Package:
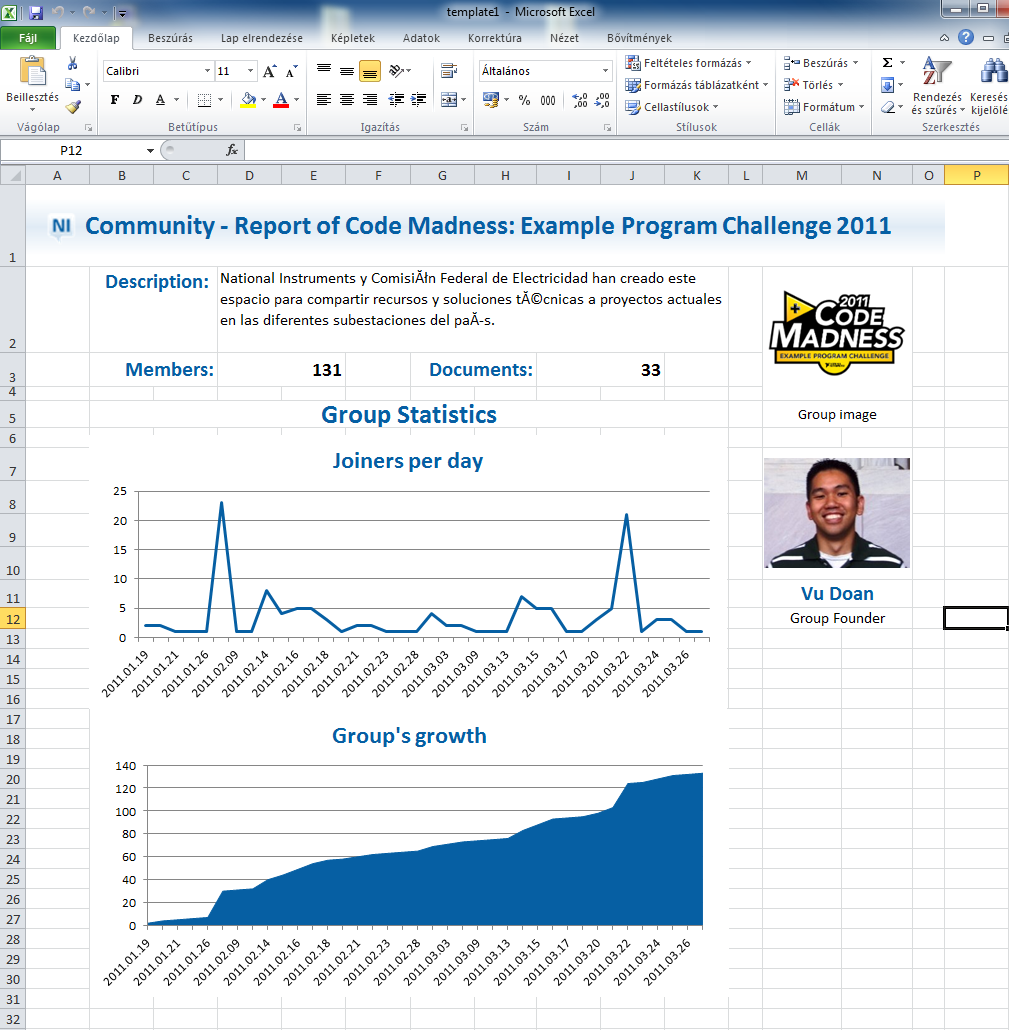
The application is extended with the functionality to generate a report of the selected group.
I was going to use DIAdem, but after playing with it for a few hours, it seemed to be so much more complicated to create reports from non-TDMS data, than M$ Excel, that I chose Excel instead. To transfer data to Excel I choso to use the Report Generation Toolkit for Microsoft Office. It's usage is really straightforward, and works very well. It is not locked to specific Office versions (like when I would use ActiveX).
To create the report, I transfer the harvested data to an Excel report created from a template. The data is then processed via VBScripts and Excel formulas (most of the formulas are also generated "on-the-fly" with scripts to allow adopting to the amount of data). Scripts are needed, because there are functions in Excel you can use only manually or via scripts (like filtering data). Using scripts to generate the formulas also allows you to use formulas on cells that really need them.
Minor bugfixes and modifications were made to speed up the fetching of groups.
Fourth Round - LabVIEW to the Cloud
Cloud services and cloud storage are going to be more and more popular nowadays. Cloud storage is a perfect way for sharing data (like measurement results, generated reports), creating backups, etc.
Amazon with it's AWS (Amazon Web Services) is probably the most popular and recognized provider of this kind of technology. S3 (Simple Storage Service) is a very powerful one, as it allows the cheap, safe storage of virtually infinite amount of data. As a very popular service, there are countless implementations of it's API in many languages (like Python, PHP, .NET, Ruby, etc.).
Even though I decided against them, and I did implement the S3 API from scratch. This way I was able to make it using only native LabVIEW functions. The VIs implementing the API are grouped to an lvlib. These together make it possible to use this library very easily on every platform LabVIEW supports. This might be very useful on targets like cFPs and cRIOs, where storage space is very limited, but they usually gather data 24/7/365.
The only third party code I used to implement the library is the SHA-1 Cryptographic Hash Function's implementation found in the NI Community as the service needs HMAC SHA-1 to sign requests.
The Amazon_S3 library I created in the project does not implement all the existing API calls, but the complete VIs are enough for many tasks. Also after understanding Amazon's REST API and the build-up of my code, it is a really straightforward process to realize other calls, as the building blocks necessary are there already as Private members of the library.
The Amazon_S3 library's code does not come with much documentation, becuse it would make no sense at all trying to place 10s of pages of documentation inside the block diagrams. Amazon has two very useful documents on S3 REST API:
I used these documents during development, so all the VIs are created according to them. They are very detailed, and really easy to understand, so if someone is going to extend this code, he/she should start with reading them.
Eevn if you want to use it in a project, the first part of S3 Developer Guide would worth to read.
Behind the scenes:
- Communicating with webservices
- Fetching simple HTML pages
- HTML Client VIs
- Data parsing via regular expressions
- Converting JSON data to XML
- Parsing XML documents
- Using math formulas and evaluating them
- Event-driven architecture
- Using notifiers combined with user events to send notifications to an event structure
- Using queues to send commands and data between VIs
- Using Report Generation Toolkit for Microsoft Office
Steps to execute code (latest version):
- Open attached project
- Open and Run Main.vi
- Press the Get Groups button
- After fetching groups you can browse them
- Click on one of the groups - Documents of the group will be fetched
- Change the formula as you want or leave default, then press Calculate button
- Press the Sort - Subject button
- Click on any document to display it in an other window
- Click on Hide Display button to hide or Show Display to show the document window
- Double-click a document to open it in your default browser
- Click on Create Report button to generate a report of the selected group in Excel
- Repeat any of Step 4 - 11 as many times as you want & Have Fun!
- Press Stop button
- Vote for my project!

Screenshots:
Main Front Panel:
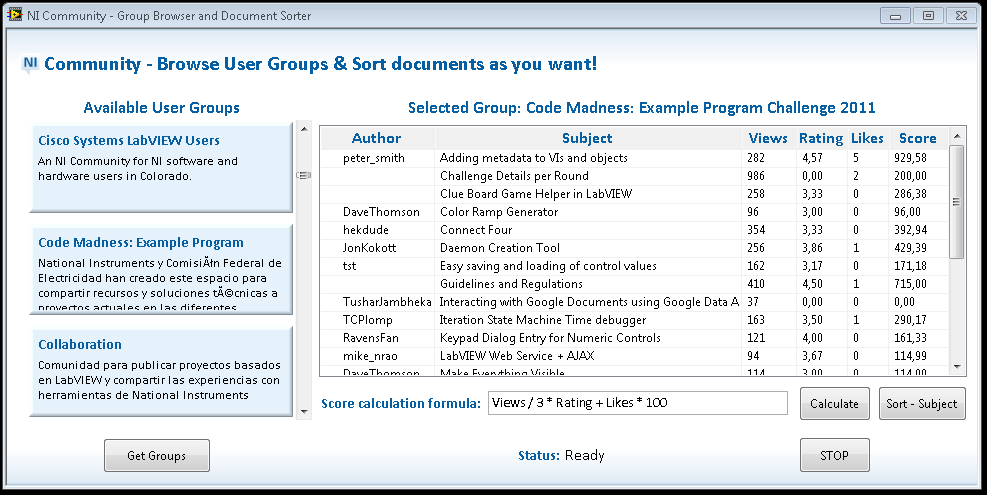
Main Front Panel after task 2:
Report generated in Task 3:
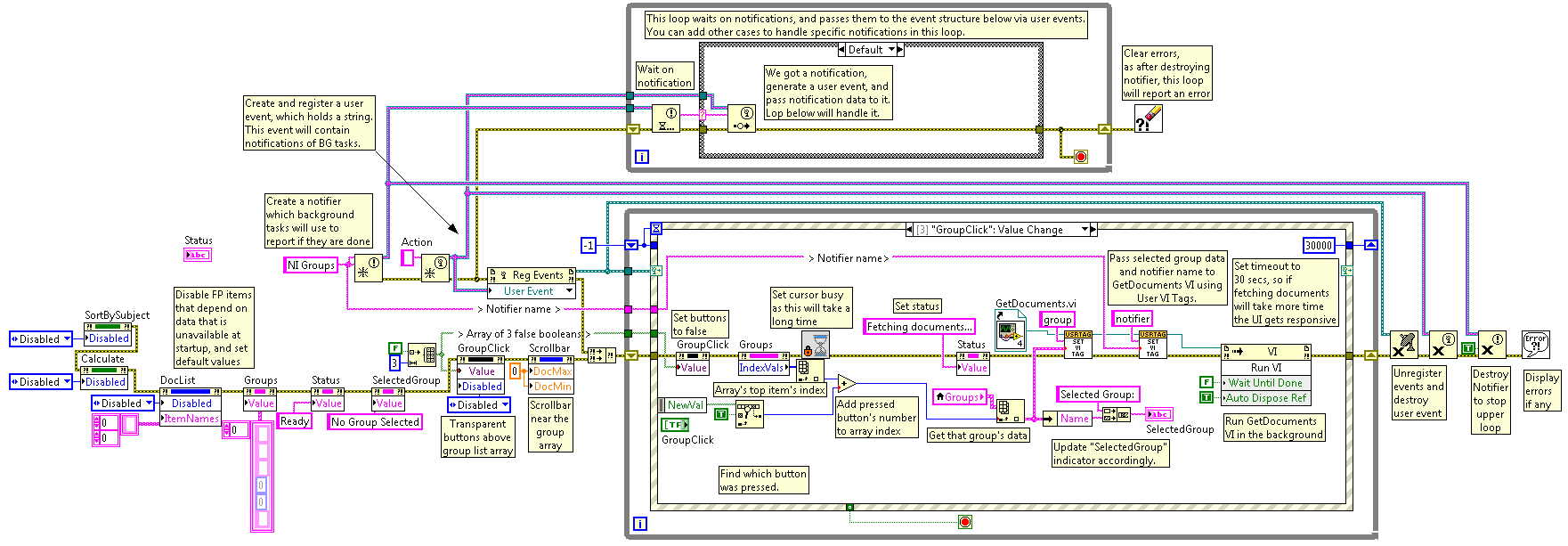
Main Block Diagram:
This diagram is quite large, but I hope it will show at least the architecture of the program.
VI Snippet:
This program is quite complex, and there is not much use of a snippet from it, however to suit the rules I include one here.
This snippet may be used to display the likes of a document of an NI Community Group. After placing it, fill in the URL with a Documents URL and run the VI.
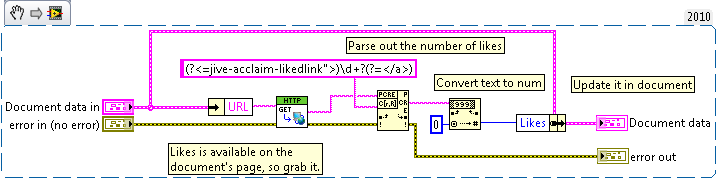
VIs attached below:
Note: I just upgraded to LV 2010 SP1 and noticed that fetching of the groups does not work. After identifying the root of the error I discussed it with Grant (Thank you for your help!), and he found that this is an already reported bug of the HTTP Client VIs. CAR number is 284156 if someone might be interested in it.
There is a workaround however: A path constant (eg. cookies.txt) should be wired to the OpenHandle.vi's cookie file input on the block diagram of the ConnectToCommunitySite.vi to allow the HTTP Client VIs to store the received cookies on the file system.
This bug is already repaired in LV 2011.
Bugfix: As Christina pointed out there was a bug in the application, as I assumed that all the groups have a description property. I corrected the VI that was responsible for this issue, it is attached below. To resolve the problem, simply overwrite the old VI in the Harvesting\NICommunitySite\GetGroups\ folder with the new Get_Group_data_from_XML_string.vi.

