- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
VI Analyzer Feature Idea - Ignoring Individual Results
04-25-2013 05:43 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I'd like to start a discussion about a frequently-requested VI Analyzer feature...the ability to point at a specific test failure within a specific VI and say, "never show me this failure again". Here are some raw brainstorming ideas I have on this feature so far:
- How should the ignored results be stored? I'm inclined to say that an ignored result would be a Test Name associated with a particular object within a VI. If we store the object's UID, that should make for easy lookups. In fact, it might be beneficial to update all tests to return UIDs to the results window...this has other performance benefits as well.
- If we went with the UID approach, then we would still need to have backwards compatibility for older tests written with the RD array approach. However, we might consider not supporting RD-based tests for the 'ignore this result' functionality.
- Probably the biggest issue in this list...where will we store ignored results? Some possibilities:
- An array of ignored results stored as a tag in the VI.
- A GObject tag on the ignored result. An advantage would be that we wouldn't need to use the UID approach...as we're traversing for results to display, we can just see if the returned GObject has the 'ignore' tag, and if so, not show it.
- The CFG or RSL file. Big disadvantage is that this would require users to create a CFG/RSL file...currently there is no requirement for a CFG/RSL to do an analysis and see results. Although since an ignored result implies a future analysis, maybe the CFG file is the best place to store this info, since a user performing multiple analyses probably has a CFG file.
- Any approach that involves storing ignored result info in the VI will require saving the VI. It will also mean that those results will be ignored by anybody else who is analyzing this VI.
- Should we have some reflection in the Results UI that there are ignored results on a VI, and provide an option to show them?
- Assuming we want to provide the ability to un-ignore a result, what will the UI experience be for managing ignored results?
- Should ignoring results somehow have representation in the programmatic interface? I'm inclined to say 'no' on this one...choosing to ignore a result seems like it is most well-suited to be a UI task.
Please let me know any opinions you have on this feature, and any potential suggestions you have on the questions I've posted above.
04-25-2013 06:13 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Random thoughts on this:
Really exicted to see you thinking about doing this. Even if it is going to be a few versions, thanks for looking into it.
I am all in favor of going completely UID based for results gathering. Especially for something like ignore capability. Even if this means ignore capability only supports "new" tests with UID coding support. I hate RD structures so much that I would be willing to have major recoding requirements to get custom VI analyzer tests to work right in LV version N+1. I REALLY want to see VI Analyzer get to UID and away from RD.
I completely support the idea of tagging the VI itself (either VI or object within the VI) for saving ignore information. I think the configuration file is the wrong place for this. I think we should support "ignore this test name for the entire VI" and "Ignore this test failure for this one situation in this VI". I would be more in favor of only storing this information in one location (so you don't have to traverse everything to find the information), which would suggest VI tags as an array of tests to ignore, and each test had a array of UIDs that should be ignored (and somehow support a "all UIDs" or "entire VI"). This is necessary since some stuff (like tests on VI description, or separate compiled code flag, etc) don't necessairly have a UID associated with them.
Something interesting to consider. If we have code that we have written, and we copy/paste that code (into same VI or different VI) should the new items get ignore flags like the old ones? If we tag against the Gobject, I would assume (correct me if I'm wrong here) that the tag would follow the copy/paste so the new elements would also be ignored. If we tagged as an array at the VI level it wouldn't. Need to scratch my head a little more for what I like more on this one.
I think the UI should then have a "show/hide ignored results" selector that is defaulted to hide ignored results (and settable through your cfg file). These would then show up colored differently in the list even when they are displayed. You could then select the item in the list, right click and choose "no longer ignore this item", or right click on an actual failure and choose "ignore this item", or right click on the VI and choose to "ignore this whole test for this VI", or "ignore this test for all VI's in this analysis event". Multiple select would be really important here.
As far as PI, it would be helpful to be able to set ignore flags through VI scripting. Or possibly even more important to be able to write a scripting VI that would clear all VI analyzer ignores. If this is me manually writing a scripting VI that goes through all the tags of a VI and deletes anything starting with "NI_VIanalyzer...", I'm OK with that. Not the most elegant, but then that's really a super-user type thing so we can expect super-user type coding to get there. If it were easy enough to Start VI analyzer and start analysis of all the VI's, show all hidden results, right click on the root of the results tree and choose "un-ignore all items", and then save all VI's, that would be pretty painless (except for maybe waiting the hour or 2 that some of my VIAnalyzer tasks take).
Can't wait to see this actually implemented.
04-26-2013 02:31 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Thanks for the reply, Warren. Here are my thoughts on your feedback:
> I am all in favor of going completely UID based for results gathering.
So am I. The RD approach was a last-minute change during the VI Analyzer 1.0 beta (this was back during the LabVIEW 7.0 release) to get around the fact that we were keeping every analyzed VI in memory during the analysis. This approach was turning out to be unscalable (duh) with large numbers of analyzed VIs. We didn't have UIDs back in LabVIEW 7.0, which is why the RD approach was our next best option. As soon as I get a measurable amount of time budgeted to work on VI Analyzer features, providing a new UID-based test interface (and updating the shipping tests to use it) will be my top priority, since it will most certainly be reused by the 'ignore this result' feature. The RD approach will definitely need to stick around for legacy support, though...we've got 10 years worth of custom tests floating around out there that still need to be supported.
> I completely support the idea of tagging the VI itself. [...] I think the configuration file is the wrong place for this...
My main hesitancy with storing the 'ignore' info in the VI is that this would result in modifications to user code. In general, there are very few LabVIEW add-ons that modify user code in a non-interactive way. One great thing about the VI Analyzer is that it's non-obtrusive...you can analyze VIs across multiple targets, and you can analyze VIs saved in older LabVIEW versions, and you never need to worry about the VI Analyzer messing up your stuff by cross-linking files, or upsaving them to the current version, because the VI Analyzer never makes modifications to user code. This is why I was leaning towards a CFG-based solution. Another idea I just had, though...what if ignored results were saved in a .xml file next to the VI on disk? You'd have an extra file to carry around (maybe a single XML file within a folder could represent ignore settings for all VIs in that folder?), but your code would not be modified...and if you wanted to wipe your 'ignore' settings, you could just remove the file. If you wanted to edit your ignore settings, you could edit the file. What do you think of that? The more I think about a tagging solution, the more I think it's just got too much destructive potential.
> I think we should support "ignore this test name for the entire VI" and "Ignore this test failure for this one situation in this VI".
Why do you need "Ignore this test name for the entire VI"? Page 4 of the VI Analyzer UI allows you to deselect individual tests on individual VIs. Again, though, if you want that setting persisted, you have to use a CFG file. Which makes me wonder if the ignore results info really should be stored in the CFG file. The whole point of the CFG file is that you're running the same analysis multiple times, which is also the use case that we want 'ignore this result' functionality for.
> I think the UI should then have a "show/hide ignored results" selector...
This seems like a yellow feature to me. The primary use case that has been described to me by users who want this feature is that, once a failure is ignored, it's really never thought about again.
Again, thanks for your feedback thus far. It's nice to have community involvement in brainstorming to augment the internal discussions we're having on this feature.
04-29-2013 10:47 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I understand your concern about modifying user code to store VI Analyzer ignores in, but consider this: It's not like VI Analyzer decides for itself to modify the code, the user selected a failure item and told VI Analyzer to ignore it. Almost like clicking on the item and editing it himself (more like quick drop shortcut using VI scripting to make code changes)
A few other thoughts on this: I'm not really liking the idea of a separate xml file with VIAnalyzer ignores in it. That just means another file to carry around. It is almost starting to sound like a section of a lvlib file. (storing this information inside the lvlib for a VI could work, but then you are limited to only VI's in lvlibs)
One of the downsides with having VI Analyzer information stored separately is that when I share code with someone, all that VI Analyzer configuration gets lost. Now when they use my VI and run VI Analyzer, they have lost all the exception/ignore information. This is true for shared code libraries across projects, and also stuff I share with others across the internet. You could argue that in that situation I should really be analyzing each reuse library independently and sharing the whole reuse library to the end users, and I wouldn't really have any counter argument to you on that one.
On the subject of CFG files: we have just given up on using VI Analyzer CFG files for code bases unless they are mature. We ARE using CFG files to define "our comany coding standards are XXXXX" (example -- we can ignore backwards wires but absolutely need our copyright in place), and after a project is mature we are starting to look at adding VI analyzer CFG files, but as it is developing they are just too much hassle to maintain -- having to go over to another location and modify the CFG file to include the new VI and the configuration parameters is just too much work at that time -- it's easier to just analyze everything and mentally skip tests for specific VI's. Finding a way to EASILY integrate the configuration of new VIs (and their ignore information) as they get added to a code base is really important. If I have a large code base that takes 1 hour to analyze and I add 1 file to it, how do I just add that one file to the CFG and analyze just that file and ignore (without risking saving the CFG with nothing else selected). CFG files start to become troublesome when you think in the realm of QuickLaunch VI Analyzer tasks -- I want to just analyze this VI, how do I find the right CFG file for it (with proper ignores)?
I think where some of this comes from is that our use case is very heavily TestStand driven -- we write small independent code modules to be called from a TestStand sequence. We don't have a parent LabVIEW project, and very few lvlibs. It would be great if we could start our analysis at our project level (which really is TestStand) and have one of the TestStand Sequence Analyzer tasks be to do an analysis on the code module (which would be a VI Analyzer task for LabVIEW modules. Instead for now we are limited to analyzing directories of individual VI's that we believe are used by the TestStand sequence.
Another one of our "pie in the sky" dreams is to configure an automatic analysis server that would just sit there and watch for commits to our revision control repository, get each of those commits and run VI Analyzer ( or TestStand Sequence Analyzer) on the code and email failures to the user. If ignore information is stored in a independent configuration file we would need to spend a lot of time configuring the analysis server (as new files are added, new tests developed, etc). If the ignore informaiton is included with the VI itself, then our configuration is nothing.
08-01-2014 05:41 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Jumping into this rather old thread.....
I'm currently using the VI Analyzer in a Actor Framework based project. A lot of Failures are shown on VIs automatically generated by the message maker, first of all Error Style on Do.vi and Send.vi
Being aware of the inherent risk of having a tag or similar on the VI, it would be very cool to have such a feature, maybe automatically being setable by VI scripting during automatic creation. Or at least an Ignore Option for subsequent runs.
But maybe the VI Analyzer world has continued turning and I have missed it 
08-01-2014 10:53 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Oli_Wachno wrote:
But maybe the VI Analyzer world has continued turning and I have missed it
Thanks for the feedback. No, you haven't missed anything...the "Ignore Individual Results" feature is not in the product yet, but I'll definitely be consulting this thread when I get some project time allocated for it.
08-04-2014 12:59 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Thanks a lot!
01-13-2015 10:25 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
The idea of ignoring items became enough of an issue that we ended up implementing it ourselves in a "hack" manner, but things are working:
Background -- we are moving towards an automated headless analysis engine that will email users when they commit code to revision control that does not meet standards. However, sometimes you need to bend the rules a little and don't want to be bothered every time you commit a change to code that is a little "different". (Not that there's necessarily something wrong with being alerted, just that the power of the tool changes drastically when it goes from "oh, another one of those blasted emails -- it's probably just a set of exceptions so I'll ignore it" to "oh, one of those emails. I had that code base perfectly clean / exceptioned out yesterday, what did I do to break it".
Talking with a select set of our internal customers, the few key requirements were
1) the "exception" information must stay with the code, not some separate configuration file that is different for different people, or that would be recreated every time we branched/copied/renamed the code.
2) the "this is OK" flag must be easy to add.
3) users must be able to see through block diagram that there is an exception in place. This came partially because of "new feature I want to know exactly what is going on here" which is just engineers being engineers and may go away after they know more or become more trusting, but also because any amount of visible "flags" that something is exceptioned is more documentation to the user that "yes it is OK that I dropped this error line and it is intentional" rather than just seeing the dropped error line and having to look through several menus to see whether someone had intended it as dropped and flagged it to be allowed dropped in VI Analyzer testing. Adds some more to the idea of "self documenting code".
From our side to extend the existing VIAnalyzer to support this without totally redoing it, we ended up going with comment blocks.
We added single-word comment blocks with specific text values in them "Prefix_TestUID", where Prefix was company name , and TestUID was a short descriptive text for the VIAnalyzer test, like "ErrorDrop". To make these easier to separate from normal comments, they were all colored a different background color, and we created a large number of VIs to go on the LabVIEW Palette that were just comments and set to "place contents" so we could drop the properly-spelled flags on the block diagram through the LV palette. (this was decided as "easy enough" -- preference was given to modifying VIAnalyzer UI to auto-place the right comment through a rightclick menu, but that would be too much modification for us.
Then all we needed to do is write some code that got placed in each one of our custom VIAnalyzer tests that checked whether there was a comment text box with the text "FOO" "reasonably close" to the problematic item and owned by the same parent. Not totally fool-proof (like if there are two problematic items very close together, the one exception text can/will cover both of them) but things are working.
01-13-2015 02:15 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Warren,
That's a really cool approach! I really like that it requires conscious user action to edit the VI to ignore failures, which gets around my big concern of this feature requiring edits to user code. I guess with the current RD approach of the VI Analyzer, it makes the most sense to have the code that checks for failure exceptions live within each test individually.
Is there any reason why y'all didn't use attached comments, which eliminates the "reasonably close" requirement with your current setup? I'm envisioning the next evolution of this idea involving attached comments, like so:
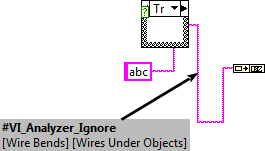
We would have some common subVI that all tests could call that would pre-parse the diagram of the target VI to find items that are exceptions for failures being returned by the current test. Then a given test would ignore any items returned by this subVI. I'm thinking an unattached comment would mean that all failures would be ignored for the VI that owns that comment. Having the tag be a bookmark also makes it easy to find all ignored items across your codebase...just look for the #VI_Analyzer_Ignore tag in the Bookmark Manager.
The best part of your idea is that it wouldn't require *any* changes to the VI Analyzer UI or Engine. Although it would be preferable if I added a support VI for pre-parsing target VIs that all test writers could use.
-D
01-13-2015 03:49 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
We went with free-floating comments because we are still using LV2012, and that feature was not available -- going to attached comments would definitely be an improvement. Tweaking what we have right now I would expect it to be use LV palette to drop contents of SubVI to create the comment, and then attach to the item. (key part here making sure users don't need to type in the flag and get spelling/capitalization/spacing wrong)
Adding a quickdrop menu to deal with VI Analyzer exceptions could probably been done, but we have ended up staying away from quickdrop stuff (largely because of issues related to lanugage localization across multi-lingual instances of Windows).
Right now the text comment is treated differently by different tests -- for some tests (like "check for compiled code being separate") the existance of the special flag anywhere in a comment on the BD or a text box in the FP or in the VI properties description field will disable/ignore that test. However for other tests (like error tunnels being shift registers through loops) I wanted to make sure I could exception single items, so it is all about the comment being close to the object itself (which right now is based on formula of the size of the item in question and the comment block itself, and the owner of each). I was playing around with the idea of checking (Is close enough) && (is not closer to another item that the exception would apply to) but that was a lot more coding and a lot more processing time for not enough extra gain. Going to an attached comment would make that code a LOT simpler (presuming there is a way to traverse from a GObject to obtain all attached comments -- don't have a LV installed version to try it on)
Using LV2012 we don't have the bookmarks feature available to us, and had long discussions about whether we should prefix our tags with # to have stuff automatically start working in the bookmark manager. Eventually we decided NOT to, but that was largely because we were afraid of over-populating a bookmark list and distracting users from being able to use it for other stuff -- which would disappear if there was an easy way to filter items out or categorize based on regular expressions (I expect bookmark manager will be just fine by the time we upgrade to a newer version of LV that has it and we will wish we had used the # prefix, but we'll cross that bridge when we get to it).
