From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
10-14-2015 09:34 PM
Hey evryone
I'm using GPIC doing a induction motor control. To do the vector control, have to use the abc to dq and dq to abc transformation.
However, when I put the high through put sin-cos function in the fpga vi, it takes way too many LUTS resources
I wonder is there a better way to calculate the sin-cos in fpga vi, which takes less fpga resources?
Thank you
Regards
Jia
10-15-2015 09:14 AM
Hi Jia, I did a quick test and found that this VI:
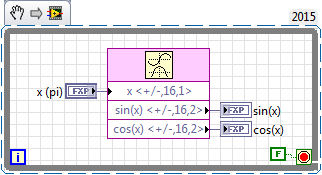
Generates these compilation results:
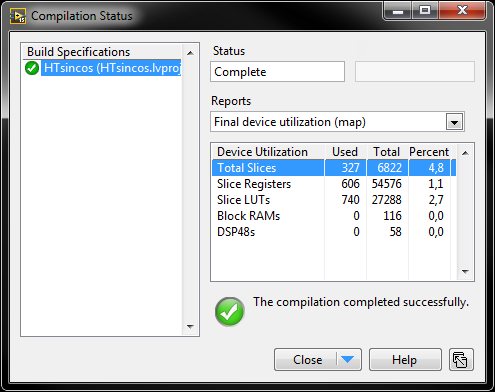
From my point of view, that seems like a reasonable amount of resources (target is 9606). In fact, the Sine & Cosine VI usage will be a bit lower than that, since these results include some logic for the front panel control and indicators.
Is that not the resource usage that you are getting? Might it be some other part of the abc to dq transformation what's having a high resource usage?
If you share your code, people might be able to provide more guidance.
10-15-2015 10:21 AM
Thank you for the reply, looks like we use the same vi. I dont know what casue the high LUTS usage
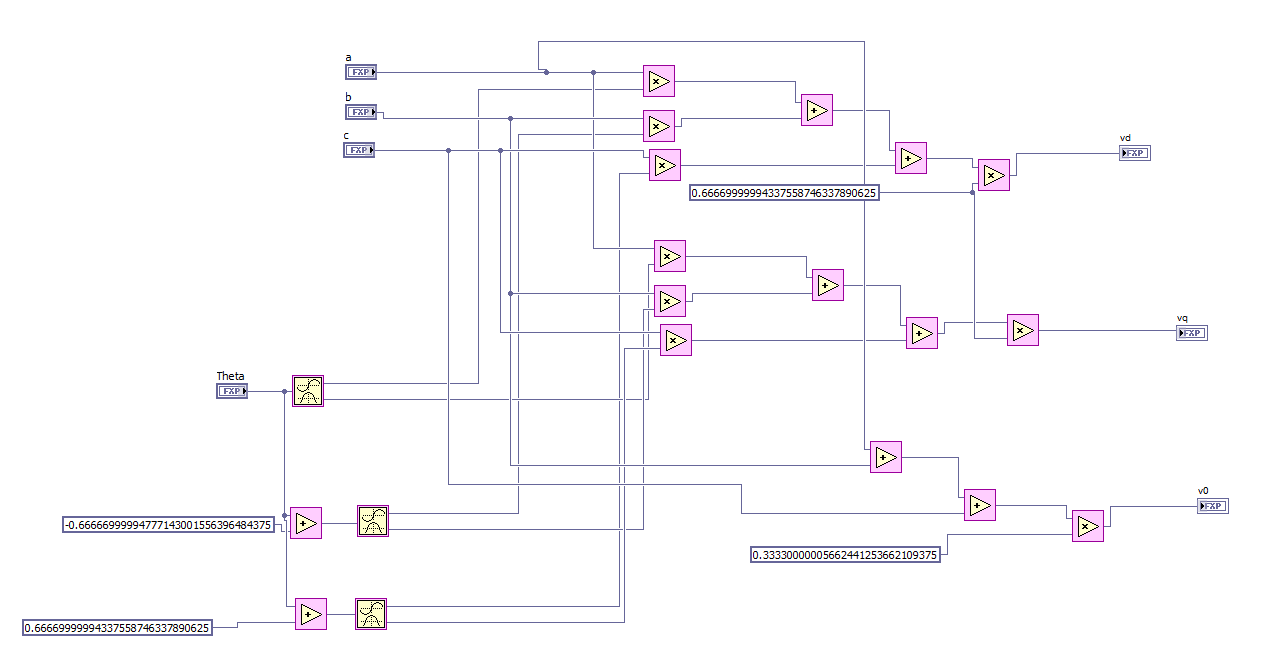
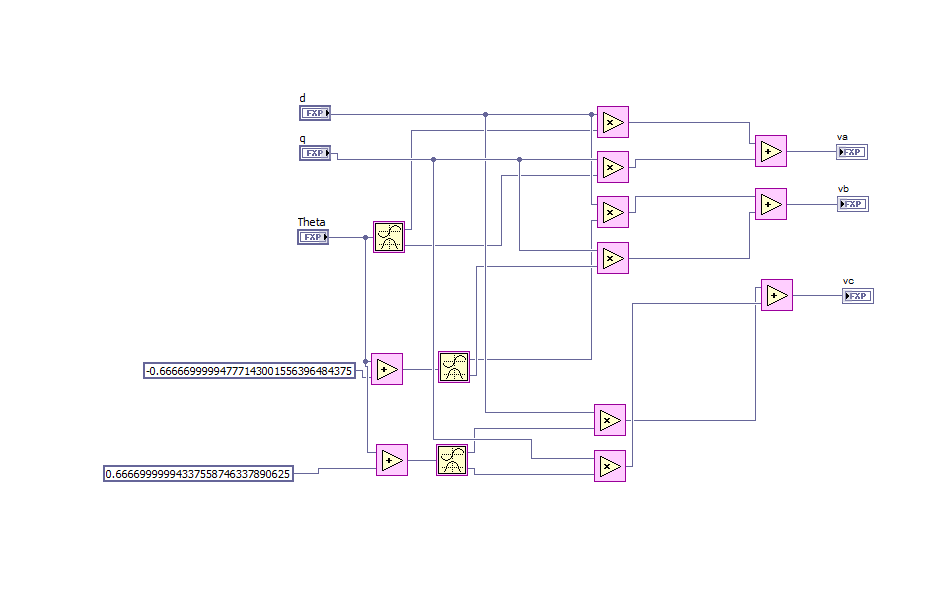
the figure above is the way i build the abc to dq and qd to abc trasnformatoin
i also attach the code
thank you very much
10-15-2015 11:05 PM
Keep in mind that the Xilinx compilation report tends not to give an accurate estimation of resource use unless the FPGA is close to full. It is perfectly happy to lazily fill up the FPGA if there is lots of space available. The reason is that it determines there is plenty of space available, and therefore does not "try hard" to minimize the resource utilization of your IP. Therefore, compile reports can be very misleading in the case that there is a lot of unused FPGA space. In this case, if the compiler meets timing constraints, it considers the job done (regardless of resource utilization).
To help get a more accurate estimate, you can change the compilation settings to force the compiler to work harder. To do this, right-click on your FPGA VI and create a build specification (if it doesn't already exist.) Then open the build specification (bottom of the FPGA project tree), and go to the Xilinx Options tab. Uncheck the box for Use recommended settings and change the Design Strategy to Timing Performance. This asks the compiler to work hard on all aspects of the compilation.
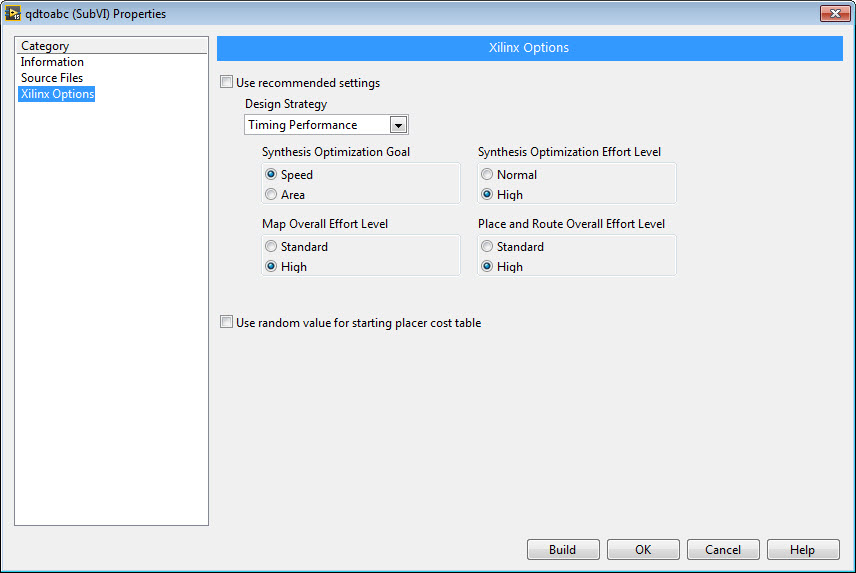
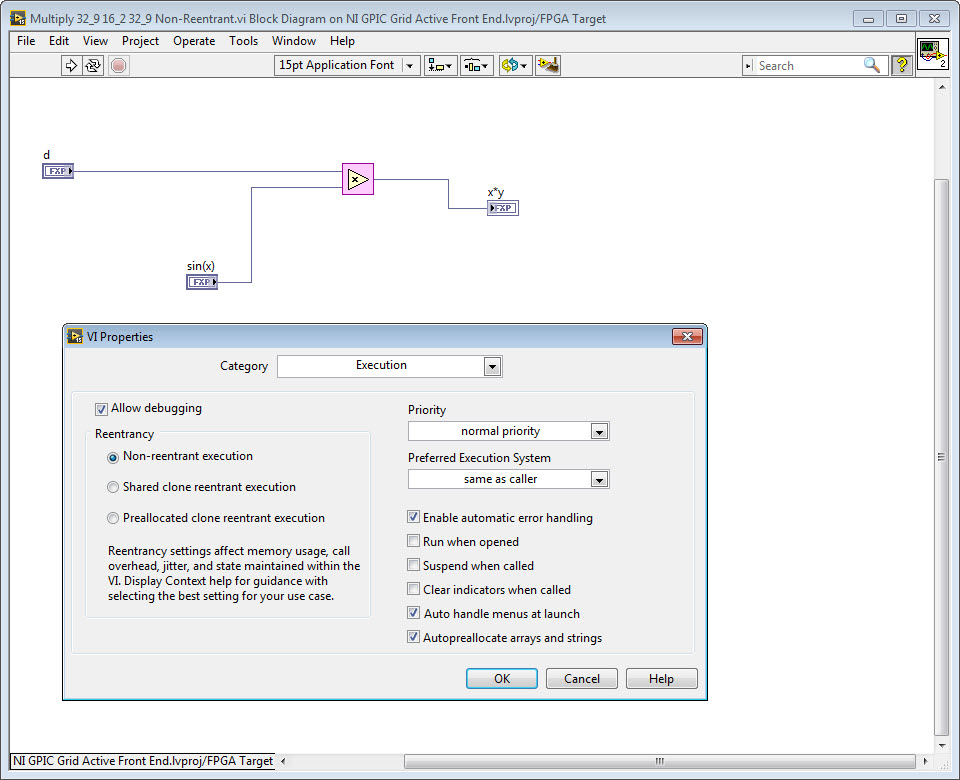
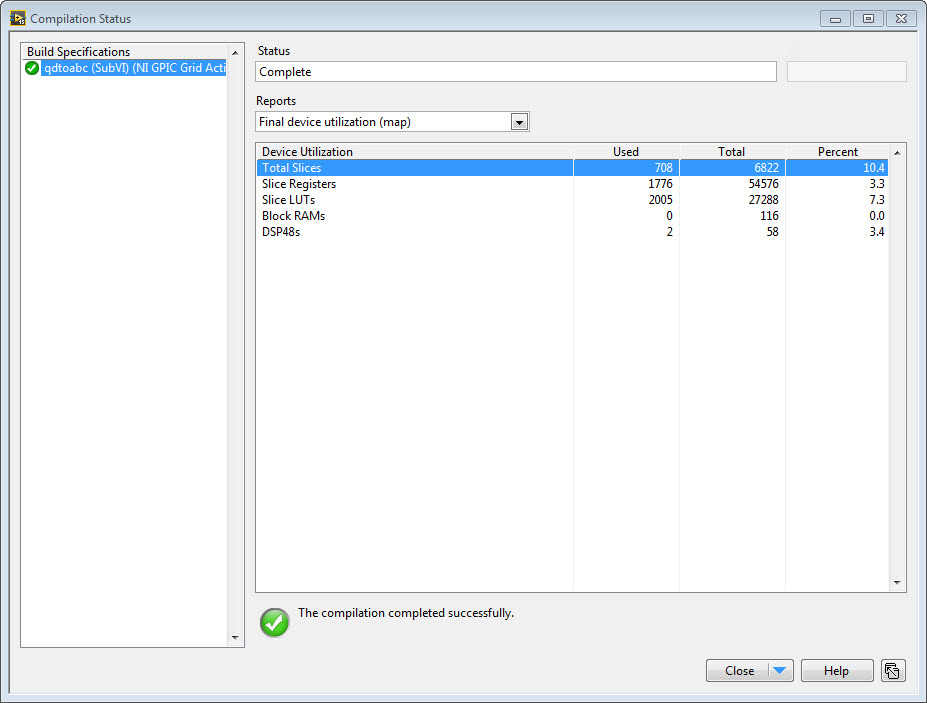
Next compile the FPGA application and observe the Final device utilization (map) report. I modified your IP core to use common fixed point data types for multiply, add and sine calculations where possible and then moved the math operations into non-reentrant (shared) subVIs. By resource sharing, this will make it slower due to resource sharing (multiplexing via arbitration), but reduce the resource utilization since only a single instance of a math operation for each data type is required. Typically FPGA IP is extremely fast, so sharing resources to reduce resource utilization is a good trade off. The FPGA block diagram and utilization report is shown below.

Non-reentrant execution (multiplexed shared resource) setting for subVI (File>VI Properties):
Compile report for DQ to ABC (Park) transformation (708 slices, 2 DSPs):
The code is attached.
10-16-2015 12:18 PM
thank you very much
10-26-2015 12:23 PM
You can download resource efficient IP Builder versions of all of the most common transforms for power electronics here. Big thanks to NI systems engineer, Brian_K, for these!
This free, open source library includes efficient floating point (and fixed point versions) of the following transforms:
Notes:
To learn how to use IP Builder to create highly resource optimized IP cores for LabVIEW FPGA, see this whitepaper. Please reply to this thread with any questions.
Here are screenshots:
