From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
06-01-2016 01:52 AM
In Y2's case, the crash is caused by running out of memory (Error 0x661 occurs when VmRSS > 650 MB). Here's the memory usage history (VmRSS) of the lvrt process on the actual cRIO on-site (this data was captured by a cron job that ran every 15 minutes. The sharp drops in memory correspond with a crash + restart of lvrt😞
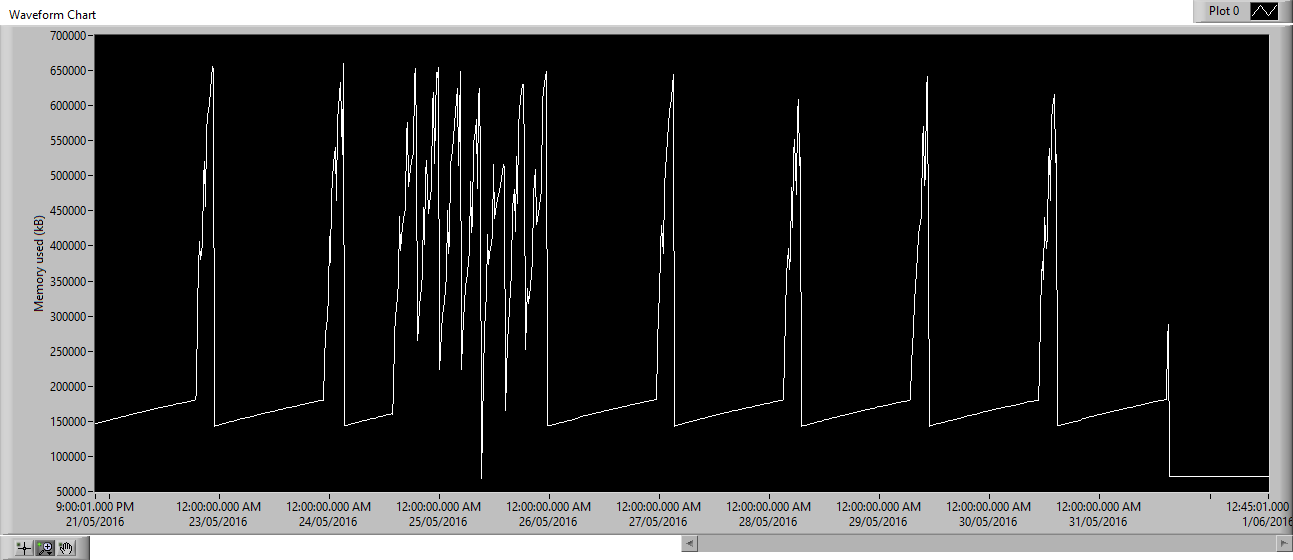
Interestingly, there seem to be 2 different leak rates (fast and slow).
Even more interestingly, I disabled the Embedded UI from NI MAX without touching the actual deployed code (the UI VI was still deployed and set to run at startup) and rebooted the cRIO... Memory usage then flatlined at ~70 MB over 24 hours, and all the connection problems disappeared. During this test, the main state machine was in "Shutdown" state, which previously correlated to the fast leaks.
The state machine, OPC UA, and Modbus bits were implemented in completely separate loops; a state machine transition should not have had any effect on any of the other loops. The UI was even in a completely separate startup VI altogether; it has ~200 indicators bound to NSVs, and also reads 19 NSVs every 10 seconds to update a chart (which has a history length of 8640)
Any ideas what this could mean?
We're currently testing to see if running the UI from a separate computer triggers the issues. If it doesn't, then we've found the solution for Project Y2. However, we'd still like to be able to use Embedded UIs in future projects.
12-20-2016 01:48 PM - edited 12-20-2016 01:59 PM
Well I too am seeing these errors on a new RT setup, and I suspect it is TCP related.
So I have a setup where there are 4 pieces of equipment on a private network with my NI 9132 which is an embedded cDAQ chassis running Linux RT. 3 DC power supplies and one programmable load from three different suppliers all claiming LXI compatible. Each device has a dedicated loop to communicate to the hardware with. I started seeing communication drop out for some reason so I started adding periodic checks of communication, and retry mechanism that would close and re-open the port if there was an error, or if the response was not seen in the expected amount of time. Originally this was 500ms but I'm going to increase it.
The large majority of the time the tests ran just fine, but once in a while the device wouldn't respond in the time expected, or the port would be closed by the peer. In both cases I close the session, and reopen it in the hopes to recover. Recently I saw a time when it would open the port, have no error, then on the next request for a read, it would timeout, so it would close the session, reopen it, perform a single successful request/reply, then the next request/reply would timeout causing the port to be closed and the cycle to happen again and again. I was probing around trying to find where the error was, and adding breakpoints to simulate longer delays when my controller restarted causing me to lose control of the equipment. On the next connect LabVIEW informed me of error 0x661. I didn't have any memory monitor code running at the time, but looking at the distributed system manager it seems stable, especially for the couple of minutes the controller was up for, before restarting in this case.
I've seen similar close, reopen, crash, situations on all 4 pieces of equipment. All are in relatively slow loops, and not much data is sent back and forth. My issue is not very reproducible and will usually not happen for a couple of days, and then will happen multiple times a day. I'll be adding more random delays, retries and longer timeouts but I get the feeling it has to do with something low level in the Linux RT code when dealing with TCP.
LabVIEW 2015 SP1 32-bit, Windows 7 x64.
Edit: GRRRRRR....On the retry the open was successful, but if the device has never been reset we send two commands to reset it using two VISA writes, seperated by 100ms, with no read. The open was successful and no error, but the VISA write had the error "Insufficient location information or the device or resource is not present in the system." Which I thought was odd because the open returned no error a few milliseconds earlier. So I probed the VISA wire and...controller restarted.
Unofficial Forum Rules and Guidelines
Get going with G! - LabVIEW Wiki.
16 Part Blog on Automotive CAN bus. - Hooovahh - LabVIEW Overlord
