- Document History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
*Note* This page contains information regarding the High Performance Analysis Library offering on NI Labs for archive purposes. The functionality previously provided by the High Performance Analysis Library (HPAL) on NI Labs will be included in an official LabVIEW software add-on in the near future. To request enrollment in the beta program, evaluate the software, and provide feedback, please contact Product Manager Casey Weltzin at casey.weltzin@ni.com.
While most functionality included in the NI Labs release is included in the beta software, there may be some discrepancies between this NI Labs page and the beta software / end product. Please see the beta software documentation for the most up-to-date summary of features and reference information.
Introduction
As multi-core machines become more commonplace, we are seeing an increasing demand for parallel processing on those machines. Many of the cutting-edge applications we tackle today come down to solving a mathematical problem. At the heart of these mathematical problems we often find key analysis functions. One such function, the matrix-vector multiplication, is vital to the control systems of the Extremely Large Telescope. These key functions are often the CPU-intensive bottleneck in meeting the specifications of the applications. To overcome the bottleneck, we could rely on a machine with a faster processor. But such a single-core upgrade will only help so much. We need to leverage modern architectures - multi-core machines - and figure out how to parallelize the computation. It then becomes very important to provide a set of high-performance analysis functions in the domains of mathematics and signal processing. The characteristics of the high performance analysis functions include:
- Superior performance to current analysis functions in LabVIEW
- Scalability on COTS multi-core machines
- Thread-safety Ease of use
Creating parallel versions of computational code can be challenging. Parallelization continues to be an important topic in academia and industry. Of course, there is a very understandable interest on the side of chip manufacturers. Companies like Intel, AMD, and NVidia invest a lot of time and energy in optimizing their mathematical libraries, which are then leveraged by National Instrument’s products. One of the most prominent examples is the Intel Math Kernel Library (MKL).
MKL contains a collection of highly-optimized, thread-safe mathematical functions. For several years now, LabVIEW Analysis has used MKL to achieve processor-tuned performance. But for reasons explained shortly, LabVIEW only uses single-threaded MKL routines, missing opportunities offered by the latest generations of multi-threaded MKL.
Why is LabVIEW Analysis limiting calls to single-threaded MKL? The complication comes from MKL’s thread-management, which can potentially collide with LabVIEW’s thread model. Note that LabVIEW is already an inherently parallel language. The compiler in LabVIEW automatically breaks up an application’s source code into clumps, and then the LabVIEW execution system schedules data-independent clumps to run in different threads. These threads can then execute on different cores on a multi-core machine. This is true for both G code and calls to an external library like MKL. It is therefore possible that more than one LabVIEW clump calls into MKL simultaneously. There would be no way, then, to exactly know how many system resources should be allocated because the MKL routines are also threaded. In order to avoid potential disaster in overusing resources, Intel strongly recommends turning off MKL threading in nested parallelism situation, which can happen naturally in LabVIEW applications.
Despite this possible conflict, we consider MKL to be a compelling technology for us to implement the parallel analysis functions in LabVIEW. We are able to meet the desired behavior of parallel analysis functions given the functionality and parallelism MKL offers. Through NI Labs, we intend to make the following MKL routines available within LabVIEW.
- BLAS and Linear algebra routines
- FFT routines
- Sparse linear algebra routines
- Certain single-precision routines
When we implement the parallel analysis functions, we add some special support code in order to employ multi-threaded MKL while at the same time overcoming the conflict between LabVIEW and MKL thread models. Even so, you still have to use the functions with care. We recommend the following guidelines:
- Use the HPAL (High Performance Analysis Library) functions only when the current analysis functions in LabVIEW are insufficient or you want to utilize the capabilities of multi-core machines
- Use the HPAL functions sequentially
- Do NOT execute other computationally-intensive functions at the same time as HPAL functions
- Do NOT use the HPAL functions for small-size problems, which may result in slower execution due to the overhead of multithreading
- Do NOT use the HPAL functions within a threading control structure like the Parallel For Loop. Exception: 1D FFT and 1D Inverse FFT VIs.
Function List
Download the Quick Reference Guide for the list of functions exposed.
Examples
There are several examples to be downloaded. These examples show how to use this library to accelerate your VI. They also show how to use support VIs to control the behavior of threading.
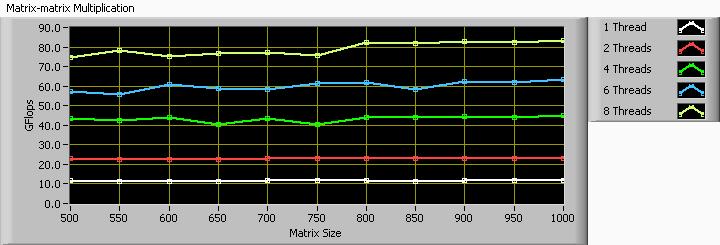
Benchmark
Download the examples for the benchmark VI. It benchmarks the performance of matrix-matrix multiplication with different number of threads. The benchmark result might vary through different computers. The following figure is the result from an 8-core computer with Intel Xeon W5580 processors.
Software Requirements
- Windows XP or later
- LabVIEW 2009 (32-bit)
Installation
- For access to the high performance analysis functions in LabVIEW, please request enrollment in the beta program by contacting casey.weltzin@ni.com
- Note that the beta program also includes functionality previously included in the LabVIEW Sparse Linear Algebra Library software on NI Labs
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report to a Moderator
Very nice - I've only looked at the FFT routines, but they're definitely faster, even on my 2-core machine! I've done some simple benchmarking against the built-in FFT routines, with the following results (1499x1499 element 2D CDB array):
- Builtin 2D: 1500ms
- Builtin 1D parallel: 800ms
- HPAL 2D: 340ms
- HPAL 1D by Row/Column: 390ms
- HPAL 1D in a parallel loop: 320ms





So for this test case, the fastest computation is to use the HPAL 1D FFT inside a Parallel For-loop. I presume the 1D FFT routine does not of itself use multiple threads??
A couple of other questions:
- Would it be possible to incorporate a 3D FFT? And perhaps a "1D by Row/Column/Page" equivalent?
- FFTs are commonly used together with the Inverse, and in many cases, the result (and sometimes even the FFT) could go back into the original array (thereby saving memory for large arrays). Would the call to the MKL library support something like this? The current design requires allocating a new array for every FFT/Inverse call.
