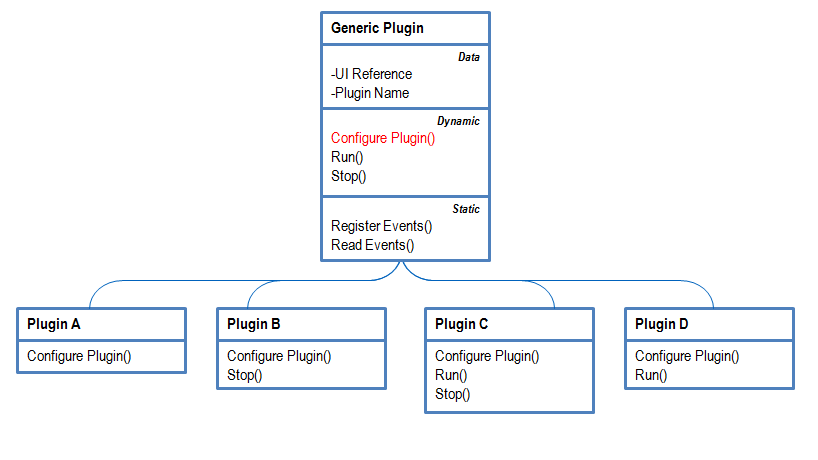
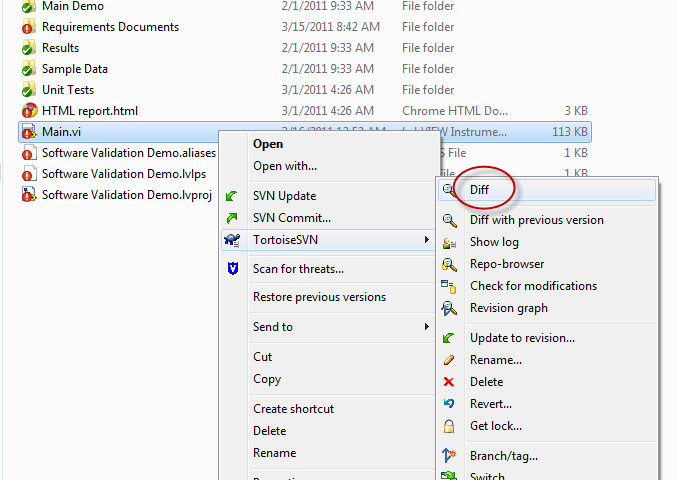
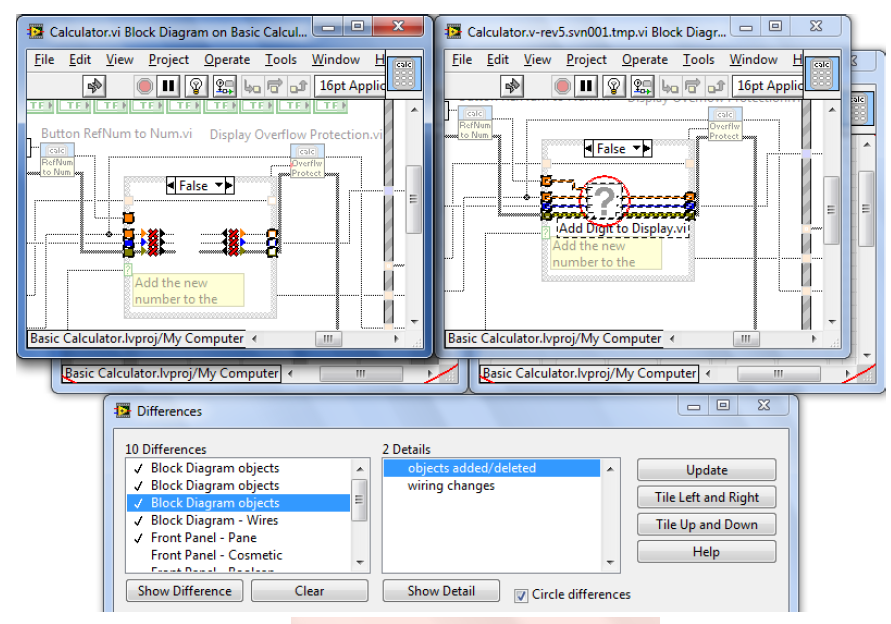
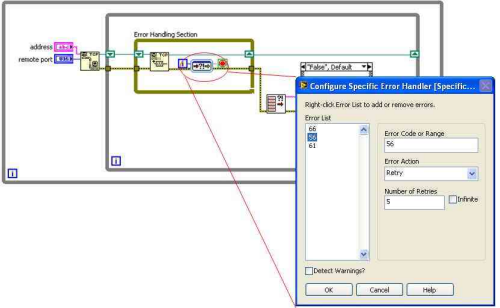
This idea, LabVIEW as one of the Top 20 Software Development Environments, was recently posted to the NI Idea Exchange, which prompted some great discussion that I wanted to contribute my thoughts to. Unfortunately, my response grossly exceeded the number of alotted characters, so I decided to offer my response here instead:
In general, LabVIEW is a highly-productive graphical development environment for scientists and engineers. The language, which is commonly referred to as G, is just one of the aspects of LabVIEW that we believe makes our customers so productive when building and designing systems with our products. To go beyond the language itself, it is the combination of all the elements of engineering in one environment that really differentiates LabVIEW. I'm referring to the abstraction of various hardware platforms, the inclusion of a very large amount of IP that is aimed at engineering and scientific applications, and the very tight integration with hardware and I/O. Because it is so much more than just a language, it is sometimes a difficult comparison with other approaches, and the comparison often risks overlooking a lot of the other benefits.
As the complexity of the applications people are using LabVIEW in has grown over the years, so to has our offering of professional software tools and capabilities. The professional version of LabIVEW includes many features and capabilities that are targeted towards users that do consider themselves programmers, which has made it more approachable for this audience. This has already helped elevate our visibility as a language, but our primary goal is to enable engineers and scientists who care about I/O and turning real-world data into meaningful information for the sake of measurement and control applications.
That's the world as we see it - at this point, here are some specific thoughts on your points (thank you to Shelley G. for contributing her input to several of these posts as well):
1) Reduce the price of LabVIEW Professional to $1500 (and get rid of LabVIEW Base – why teach poor programming practices)
Pricing is always tricky, but Base exists to provide a inexpensive entry point with all of the functionality needed for very simple data acquisition and instrumentation applications. Our model is designed to enable the use of our products at a reasonable price, while still making it possible to fund the very high-level of investment in new features and products (an average of one a day!). Consider that we strive to re-invest roughly 16% of our annual revenue back into our R&D groups. We don't want to teach bad programming practices, but our assumption is that simple tasks do not require the use of advanced programming concepts, which are specific to the professional version.
2) Allow a standard web browser to be the user interface (without any plug-ins!)
I'm glad you brought this up! If this were an individual suggestion I would mark it as complete and point you towards our new LabVIEW Web UI Builder, which you can see and use at ni.com/uibuilder. There are multiple approaches to interacting with a web browser from LabVIEW, but this new tool actually allows you to design an HMI that runs in your browser and communicates with other LabVIEW applications via standard web services. You will need to have Microsoft Silverlight installed on your system, but you do not need the LabVIEW Run-Time Engine (unlike remote front panels).
3) Fold in some of the general purpose toolkits into the main product (best way to add new features!, but I can live without this)
That's exactly what we strive to do with Developer Suite, which gives you access to a wide variety of add-ons and toolkits without having to spend much more. That being said, we have received consistent and vocal feedback from users who want a few toolkits in particular to be more readily available in the Developer Suite Core package, so look for some changes in the packaging with the release of LabVIEW 2011. (I've already said too much!)
4) Sell single board cRIO in quantities of one (at a reasonable price). And show the price on the NI website.
This is available today through our Embedded Eval Kit option, which you can find here: http://sine.ni.com/nips/cds/view/p/lang/en/nid/205722
5) Reduce the price of LabVIEW RT, FPGA and embedded.
This goes back to the tricky topic of pricing, but embedded development tools are normally extremely expensive. What you can achieve with LabVIEW FPGA for a few thousand dollars is unmatched in the embedded or test industry.
6) Offer more deployment platforms (RT, FPGA and embedded) – this is where NI will make money, by selling more hardware.
Earlier I mentioned that we release an average of one new product a day, and I think that this is evident if you look at are large portfolio of products on ni.com/products. LabVIEW has enabled us to abstract the complexities of programming for multiple and different hardware targets - making it possible to leverage all the latest platforms and technologies in your application, which we see as a core value proposition. We can target all the latest Xilinx FPGAs and we're constantly coming out with newer, faster and better RT targets. We also recently introduced the LabVIEW ARM module.
7) Offer general-purpose low-cost mini-board (a few digital and analog I/O and a controller). Think 32-bit Arduino-like. In fact, why not make it compatible with the Arduino shields (stackable plug in boards that add functionality).
While we evaluate our own low-cost platforms, we have already plugged LabVIEW into the low-end hardware ecosystems (it’s a big request from our academic market). Check out some of the Arduino resources:
😎 Improve the robustness of LabVIEW (in preference to new features).
Absolutely. Based on feedback from users, this is the primary focus of our LabVIEW development team – you will see in LabVIEW 2011 and future releases, an intense focus on performance and stability. This focus is a direct result of compelling customer input like yours.
9) More tutorials, examples and learning documentation (helps users, reduces support costs and opens the door to cheaper LabVIEW).
We have a very large offering of online and in-person training courses for all of our software products, which you can find at ni.com/training. LabVIEW also installs hundreds of examples in the Example Finder (in the 'Help' menu). When it comes to software development best practices and similar practices, you can find a lot of the latest content here at ni.com/largeapps. To see a summary of all of our technical resources, visit ni.com/labview/technical-resources
10) Increase the user base by a factor of 4 (needed to get to “critical mass” for user community).
We totally agree with you here! Lets increase it by 10X for that matter. To this end, we have a large focus on increasing the number of students that know how to use our tools and better connecting them with demand from industry. You can also get involved as a FIRST mentor, participate in local LabVIEW user groups, or even contribute to online discussions (like these). If you have any other ideas, let us know.
11) Have the same feature set across Windows, Macintosh and Unix (or at least reduce the gap).
This is ideal, but, as you know, extremely difficult. Each of those operating systems has a unique set of APIs and capabilities particularly around their UI idioms and more importantly their OS level driver integration models. We have wrestled with this issue for 20+ years and invest heavily to try to normalize what we can with LabVIEW, but we also won’t succumb to creating a lowest common denominator experience. We have actively searched for a software technology that could provide an execution abstraction that runs on Pharlap, LinuxRT, VxWorks, iOS, MacOSX, Windows, Windows Phone, Android, and Web browsers and sadly have not found one. However, we agree that we need to continue invest in better cross platform support and we are actively doing so for our future feature developments. We believe we have found a path that only requires us to implement features twice to run on the platforms that you have requested and we or an a path to better support for drivers on the Mac and on Linux.
12) Publish a textbook for experienced LabVIEW programmers that want to move step-by-step to object oriented LabVIEW programming (assuming this is the way to go, haven’t used it myself so not sure how useful it is).
I definitely think it's the way to go, and there are a number of great resources that you should check out. Actually, several people in this community contributed to a document I'd recommend you review, called Applying Common OO Design Patterns to LabVIEW. We also have a growing number of text-books, which you can find a list of here. For more information on object-orientation, we even have instructor-led training: LabVIEW Object Oriented Design Patterns.
13) Add features to make it a more general purpose programming language (to challenge C, C++ and C#). Don’t take it too far, we don’t need LabVIEW to write word processors and database programs, but we would like to write home automation software (my next hobby project), general purpose utilities and more commercial software to go with our products (as opposed to our current usage of just in-house software).
We couldn't agree more, which is why we've invested so heavily in advanced software features and in enabling the standard software engineering and configuration management practices that users expect. You can and should be using LabVIEW with fundamental tools like source code control and static code analyzers. For more information on this, visit ni.com/largeapps, or just browse around this community.
14) Improve controls and indicators to allow the same look-and-feel as “professional” programmes. Want to create an awful user interface? Just add a Toggle Switch! There done! (Can you imagine any commercial software written in any other language that would go out of their way to add a Toggle Switch looking control? Can you even begin to imagine this in, say, Windows?). Anyway, more controls and indicators that look like those of general purpose applications and a built-in powerful easy-to-use control and indicator editor.
I love that I can always spot a LabVIEW Front Panel when watching the Discovery Channel, but I agree that alot of them are pretty ugly. Many people don't realize just how much you can customize the appearance of front-panel controls in order to design an extremely professional application. There is an entire community (and avery active one) dedicated to this very topic, here: UI Interest Group. There are also a number of great examples of progessional UIs throughout the web and in the product (a lot of LabVIEW is written in G). Finally, I strongly recommend checking out the Beta of LabVIEW 2011, as you might find some new palettes that will make designing professional interfaces even easier.
That should do it for LabVIEW 2012. I’ve got more to take LabVIEW to the Top 20 programming languages.
Let us know!


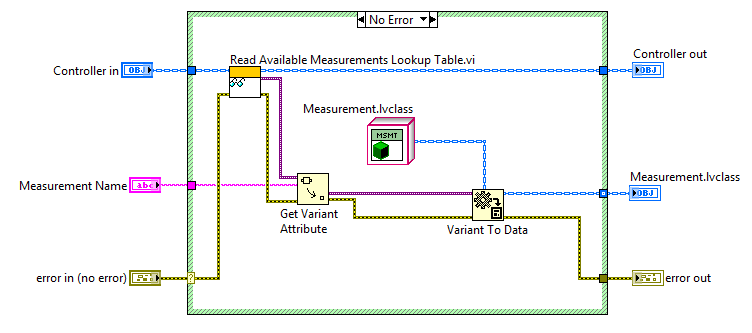

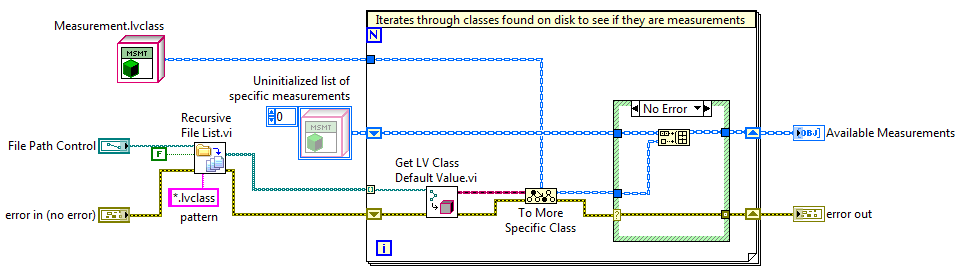
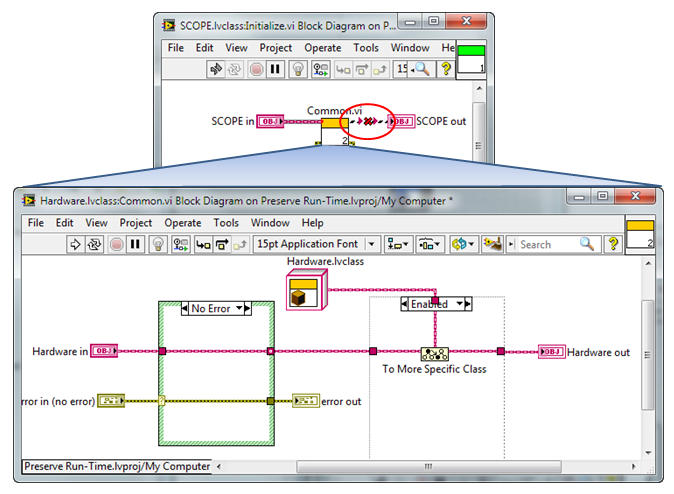
 The CLA Summit is a unique opportunity for me, as I get to participate as both a user and as a product manager. It’s great to be able to talk to so many other passionate and knowledgeable LabVIEW users, and as always, to hear your feedback and opinions regarding LabVIEW and the latest advanced concepts.
The CLA Summit is a unique opportunity for me, as I get to participate as both a user and as a product manager. It’s great to be able to talk to so many other passionate and knowledgeable LabVIEW users, and as always, to hear your feedback and opinions regarding LabVIEW and the latest advanced concepts. For those of you who weren’t able to attend, the topic this year was ‘separating user interfaces from application logic,’ which prompted a lot of passionate discussion (and healthy debate) regarding various approaches, such as model-view-controller and various frameworks for implementation. Presentations and demos from the summit are going to be posted to the community group, here:
For those of you who weren’t able to attend, the topic this year was ‘separating user interfaces from application logic,’ which prompted a lot of passionate discussion (and healthy debate) regarding various approaches, such as model-view-controller and various frameworks for implementation. Presentations and demos from the summit are going to be posted to the community group, here: