- Document History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Darwin applied to LabVIEW: The evolution of the data management
"Darwin applied to LabVIEW: the evolution of the data management." subtitle “The survival of the fittest applied to the LabVIEW Dataflow model ”.
With deep humor this presentation makes the link between the evolution of the LabVIEW data management and the Darwin's Theory of Evolution.
PS : Download the full presentation attachement and LabVIEW 2014 examples code.
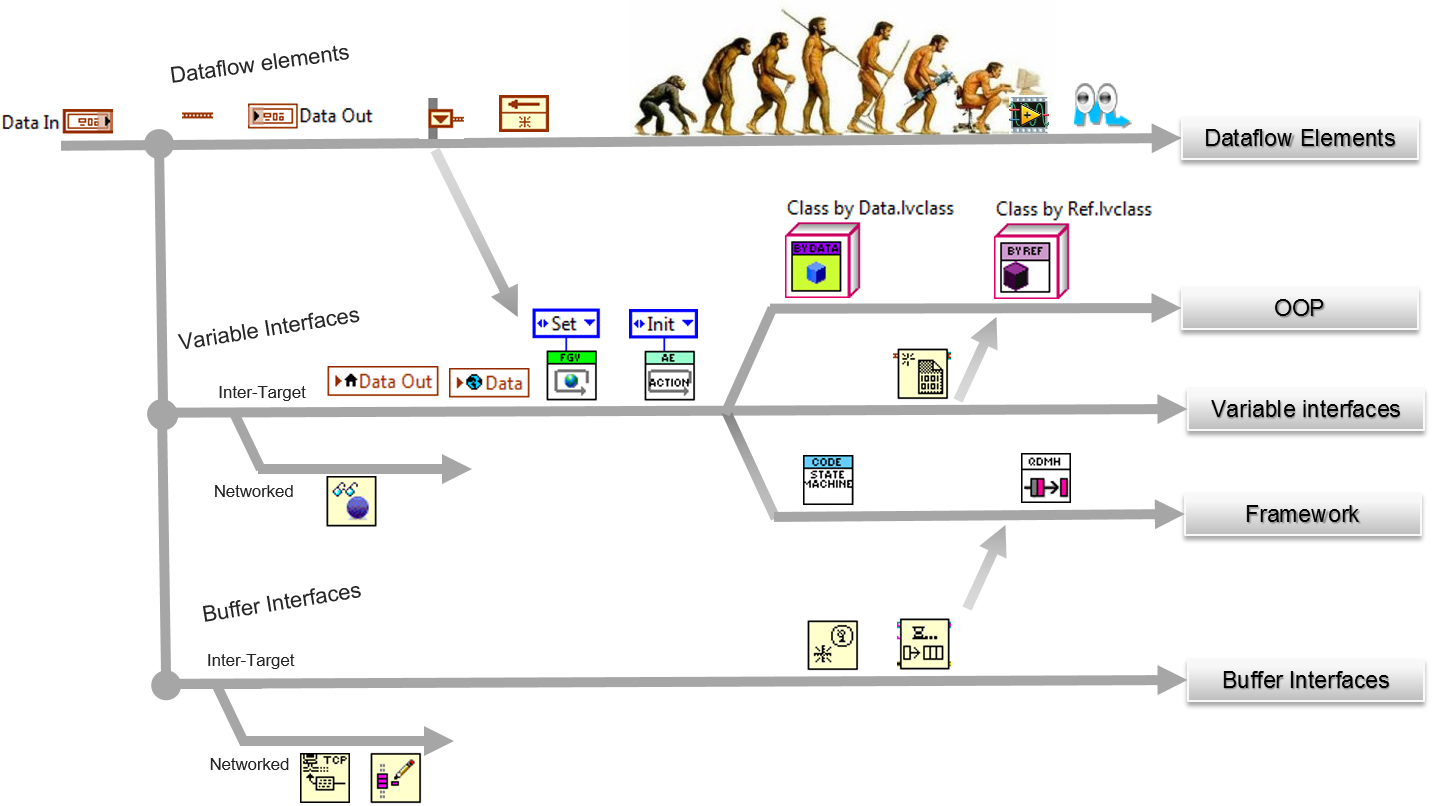
- The presentation deals with the evolution of the concept of "Data communication" of the LabVIEW dataflow model:
- Dataflow element to Variable Interfaces, to Buffer Interfaces
- To store a value in memory/ To access the value
- To prevent Race Condition, buffer copies
- The presentation does answer the following questions:
- Why avoiding local, global, Property Node? How to avoid Race Conditions? Does FGV prevents Race Condition (realy!) ?
- Which method to use? Why?
- Who is the survival of the fittest? (the survival of the most scalable)
- LabVIEW follows a dataflow model
- In dataflow programming, you generally do not use variables. For a literal implementation of this model.
- Dataflow models describe nodes as:
- consuming data inputs
- producing data outputs
- Advanced concepts : LabVIEW contains many data communication methods.
- For example, local and global variables are not inherently part of the LabVIEW dataflow execution model.
- LabVIEW contains many “data communication” methods, each suited for a certain use case.
- Can by order into 3 types:
- Dataflow elements, the primary methods
- Variable Interfaces
- Buffer Interfaces

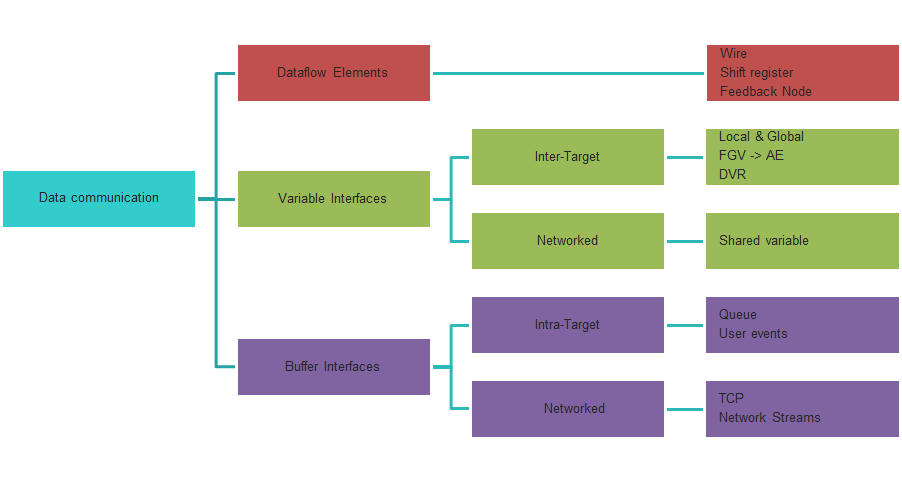
For diner tonight: Functional Global variable (FGV, LV2), Action Engine (AE), DVR, OOP, State Machine and QMH. Speed demonstration, UI thread, memory management (buffer copies) and Race Condition with simple and downloadable examples.
for example, (CLAD exam): Which of the following is the best method to update an indicator on the front panel? explain WHY...
A. Use a Local variable
B. Wire directly to the indicator « Data Out »
C. Use an implicit « value » property node
D. Use an explicit « value » property node (reference)
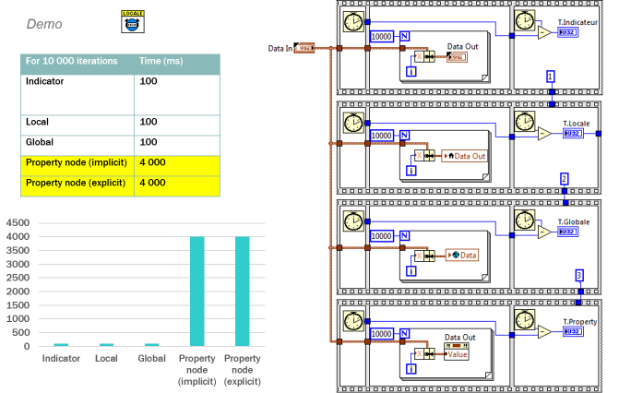
source:
more presentations? LabVIEW code, presentations
http://zone.ni.com/reference/en-XX/help/371361L-01/lvconcepts/data_comm/
http://zone.ni.com/reference/en-XX/help/371361L-01/lvconcepts/data_comm/
--------------------------------------------------------------------------------------
En français, la version française de la présentation est disponible ici Darwin appliqué à LabVIEW : l’évolution de la gestion des données
A+
--------------------------------------------------------------------------------------
Luc Desruelle | Voir mon profil
Auteur livre LabVIEW "Programmation et applications" édition Dunod
Author of the French book “LabVIEW programming and applications".
CLA : Certified LabVIEW Architect / Certifié Architecte LabVIEW

Luc Desruelle | Mon profil | Mon blog LabVIEW | Auteur livre LabVIEW : Programmation et applications - G Web
Certified LabVIEW Architect (CLA) & Certified TestStand Developper (CTD) | LabVIEW Champion
MESULOG - LinkedIn site | NERYS - NERYS Group
| directeur CEO MESULOG
| CODIR - NERYS group
