- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- « Previous
-
- 1
- 2
- Next »
Bandwidth from FPGA to RT on 9606 and 9651
07-30-2015 08:19 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi Tiffin:
I remember that fxp data are represented as a 64bit data during transfer
process form FPGA to RT, and it will have quite a overhead at RT.
So, avoid fxp in FIFO is always a good idea.
07-31-2015 03:03 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
I checked in with the FPGA devs and they confirmed that older PCI devices we recommended bit packing for bus width. But on our newer targets for whatever data type your select (multiple of 8bits) we'll implement a different dma engine to push the data back and forth to the host. We thought there shouldn't be significant difference in throughput but didn't have a benchmark on hand (24 bits will of course scale to 32 so throughput will hinder with awkward data types).
Kevin,
Please take a look into our help for overcoming the memory manager with LVFPGA.
http://zone.ni.com/reference/en-XX/help/371599J-01/lvfpgahelp/fpga_zerocopy_dma/
Senior Embedded Software Engineer

08-01-2015 12:15 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Thank you very much for your information.
DMA is designed to avoid unnecessary memory copy, but RT seems waste some
of the adventures. However FIFO did help resolve interrupt issue.
Now its clearer for me that RT performance is much of a memory manage
issue, maybe that can give me a hint someday when I need extra performance.
08-03-2015 04:15 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
For FPGA, I did discuss bit packing for bus width with Xilinx. Remember FPGA FIFO DMA is very different from the ARM processor FIFO DMA. Xilinx indicated that there is a performance benefit (i.e. fully utilising DMA channel bus width and improved DDR performance) but most users are unlikely to see any difference because the ARM processor dominates performance.
For LabVIEW Real-Time, I found the best data throughput was using one loop containing DMA FIFO read and associated data logging/processing. I use an interrupt to block/unblock reads from using a large real-time DMA FIFO buffer,
Element Packing - There is considerable benefit in packing multiple data elements together for real-time FIFO DMA reads. It reduces the frequency of read returning data (and associated memory management and memory copies) which gives noticable performance improvements. This may be needed by the rest of your application for optimal data throughput (e.g. USB and network performance improves when moving large amounts of data).
Polling - It appears LabVIEW Real-Time FIFO DMA read is implemented by polling underlying hardware (rather than blocking until an interrupt is raised). A useful reducing in ARM processor load can be gained by implementing an interrupt to block the real-time loop (FPGA raises interrupt after putting an amount of data into its FIFO DMA).
Kyle - I did ask whether memory regions would help in my NI support request. The answer was no - but I tried it anyway. The end result was ARM processor load increased and data throughput reduced. I never got any explanation for why. NI feedback was for high throughput disable VI debug (significant improvement), use one loop to avoid queues between loops (all NI queues/FIFOs use memory copies - no ability to just move pointers) and use normal loops with blocking interrupt (real-time loops are slower).
08-03-2015 11:31 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Kevin,
Would you mind posting or sending your benchmark code for regular DMA and zero Copy and I'll take a look? Your reads will typically have to be very large to benefit from zero copy as well.
Senior Embedded Software Engineer
08-03-2015 01:40 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Just to add a some specifics to that. The Acquire Region calls have higher overhead than the Read/Write functions, mostly due to some extra locking that they require. As a result, the access size has to be large enough that the timed saved by removing a copy exceeds the extra function call overhead. I don't have any numbers handy for where the crossover point is on a Zynq target, but I know on PXIe targets like the 8135 and 8133 we've measured it in the 50 - 70 kB per read range.
In general, with both APIs, reading a larger amount of data at a time will improve throughput.
I'd also be interested in seeing your benchmark code.
Thanks,
Sebastian
08-11-2015 10:09 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hey guys:
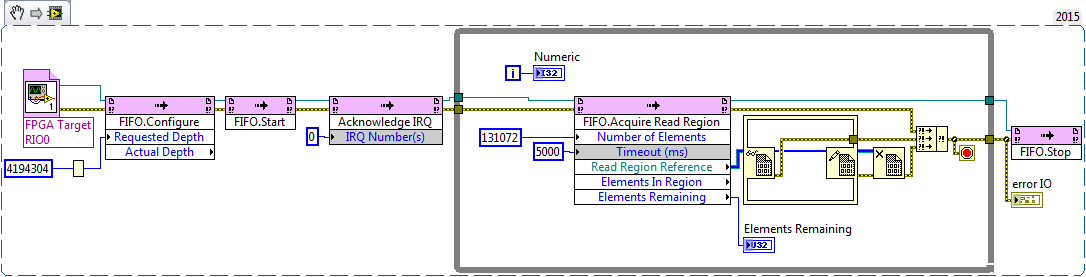
I just did a benchmark on a cRIO 9068, I think it have the same core and memory like 9607/9651, the results says something.
You can stream about two 16bit 80Msps AD from FPGA to RT (didn't consider any postprocessor), or four 8bit 80M AD data, so the bandwidth would be: 2.56Gbps or 320MBps.
The configuration:
LabVIEW 2015
RIO Driver 15.0
FIFO: U16, pack two element while writing, depth 131071 elements
9068: firmware 3.0
With this configuration, RT can read all these data, anyway, we are talking about the bandwidth here.
the same code cannot last for two or three loops at RT if we set the SCTL clock to 83.33Mhz

10-31-2017 03:43 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
Hi Guys,
I'm working on a project where we plan to take in 16bit data through some ADC chips at a 100MHz and stream it to the PC as fast as possible over ethernet.
I'm trying to tackle a project in a similar manner with the SOM and I was wondering if any of you have some example code to share which you have used to put the SOM through its paces.
02-13-2018 05:00 PM - edited 02-13-2018 05:01 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report to a Moderator
The width of the AXI bus on Zynq is 64 bits, but that is handled transparently, so you shouldn't have to worry about that. The DMA Engine also handles the coalescing and bursting so you shouldn't have to worry about that either. Data is packed efficiently on the FPGA because there is no alignment requirements. It is sent through the DMA engine and LV FPGA (SW) has to unpack it. So any changes in performance from different data types is probably related to the RT doing the packing and unpacking (because again, it's CPU bound). I'm not sure why different data types can be packed or unpacked more efficiently (I'm not in LV FPGA) but If I was to guess which data types are easiest to pack and unpack, I would guess 32-bit data types. If you use the C API, you might be able to bypass it.
Host Memory Buffer wasn't optimized for throughput but it can hit 30MB/s and there is no flow control, so there's zero CPU usage for the transfer. So that's another option.
- « Previous
-
- 1
- 2
- Next »
