From 04:00 PM CDT – 08:00 PM CDT (09:00 PM UTC – 01:00 AM UTC) Tuesday, April 16, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From 04:00 PM CDT – 08:00 PM CDT (09:00 PM UTC – 01:00 AM UTC) Tuesday, April 16, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
02-03-2007 09:14 AM
02-03-2007 10:33 AM - edited 02-03-2007 10:33 AM
Message Edited by altenbach on 02-03-2007 08:40 AM
02-03-2007 11:09 AM
I haven't looked deeply into your post (I assume Altenbach can help you better there), but as for some possible resources which will help you:
02-03-2007 11:38 AM
Thanks tst. Since the OP mentioned LabVIEW 8.2, file size is probably not an issue (and since the files are under 2GB, there would not be a problem with pre 8.0).
Starting with LabVIEW 8.0, the plain LabVIEW file I/O functions can use files up to 9.2 exabytes (reference).
(Paraphrasing Bill Gates, "9.2 exabytes ought to be enough for anyone". :))
Here is the link for Managing Large Data Sets in LabVIEW, a useful resource in general. 🙂
02-08-2007 10:15 AM - edited 02-08-2007 10:15 AM
Message Edited by Azazel on 02-08-2007 10:16 AM
02-08-2007 11:18 AM - edited 02-08-2007 11:18 AM
OK, here are some very preliminary comment:
Look at your "read header" For each call, you are opening the file, setting the offset, then read the entire rest of the file into an array (you actually try to read past the end of the file by offset), close the file and return that array to the caller.
Repeat five times!
In the following code each of the arrays contains nearly the entire datafile, staritng with the desired element. You now have five copies of the entire huge file (!!) in memory where all you want is 20 bytes. 🙂
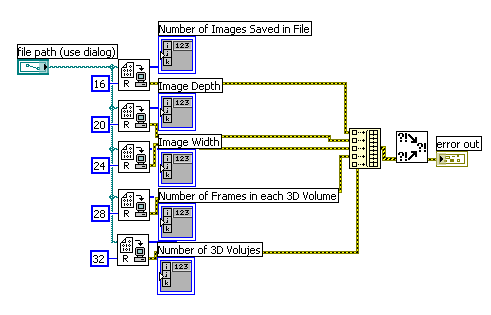
Quickest fix for that: After setting the position, read only one I32 element by leaving the count unwired and replacing the output array by a number. (or you could simply wire a "1" to count and return an array with one element).
Still, there seems little reason to do all these individual calls. Just set the offset to "16" and count to "5" and you get an array with five elements (20 bytes), corresponding to the five desired values (# of images, depth, ..., # of volumes), all in one call... and nothing else.

Similarly, once you know the file position and dimension of a frame, read the exact amount of data.
Message Edited by altenbach on 02-08-2007 09:19 AM

{kind=link}
{kind=link}
{kind=link}
{kind=link}